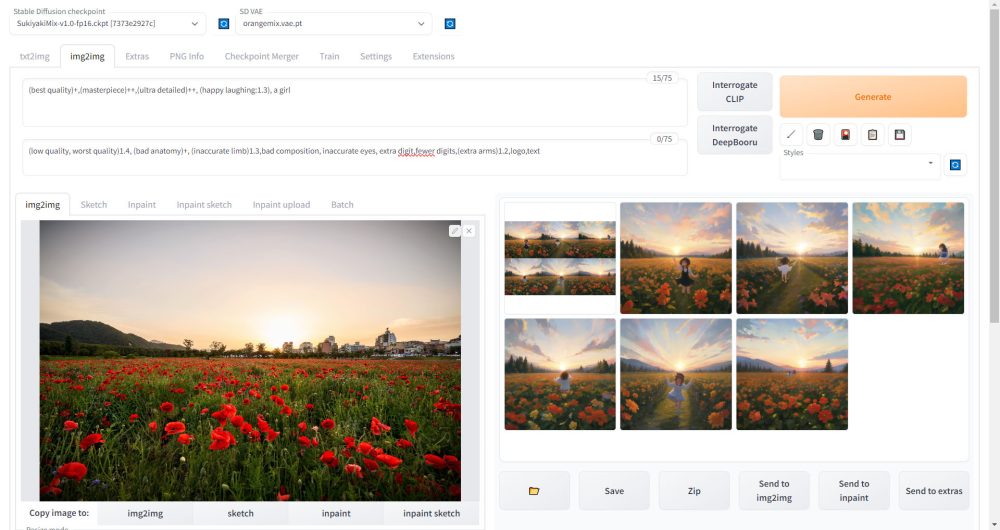
今回は、Stable DiffusionのWeb UIであるAUTOMATIC1111の使い方について解説します。
Web UIはブラウザから利用できるGUIで、画像AI Stable Diffusionの機能を直感的に操作することができます。
Web UIを導入することで、機械学習やプログラミングの知識がなくてもStable Diffusionを使える。
中でもAUTOMATIC1111は最もユーザーが多く、高機能で使いやすいWeb UIとなっていますので、ぜひ画像生成に活用してみてください。
また、当ブログのStable Diffusionに関する記事を以下のページでまとめていますので、あわせてご覧ください。

Stable Diffusionの導入方法から応用テクニックまでを動画を使って習得する方法についても以下のページで紹介しています。

Stable Diffusionとは
Stable Diffusion(ステーブル・ディフュージョン)は2022年8月に無償公開された描画AIです。ユーザーがテキストでキーワードを指定することで、それに応じた画像が自動生成される仕組みとなっています。
NVIDIAのGPUを搭載していれば、ユーザ自身でStable Diffusionをインストールし、ローカル環境で実行することも可能です。
(出典:wikipedia)


Web UI AUTOMATIC1111とは
Stable Diffusionはオープンソースで公開されているプロジェクトであるため、Stable Diffusionを使って画像生成を行うためには、ユーザーが自身でソースコードをダウンロードして実行環境を作成する必要があります。
入力するプロンプト(呪文)やパラメータを設定するためには、Pythonなどのプログラミング言語を使ってコーディングする必要があります。
プログラミングの知識がない方が使用するには、かなりハードルが高くなってしまいます。
そんな時に役立つのがGUI(グラフィカル・ユーザー・インタフェース)です。
GUIとは、グラフィカルユーザーインターフェース(Graphical User Interface)の略で、人間がコンピュータやソフトウェアと対話するためのインターフェースの一種です。
これは、一般的にマウス、キーボード、タッチスクリーンなどの入力デバイスを用いて、ウィンドウ、アイコン、メニュー、ボタンなどの視覚的な要素を操作することで、ソフトウェアの機能を使ったり、コンピュータの操作を行ったりするための方法を提供します。
AUTOMATIC1111はStable Diffusionをブラウザから利用するためのGUIアプリケーションです。
AUTOMATIC1111を使用することで、プログラミングを一切必要とせずにStable Diffusionで画像生成を行うことが可能になります。
Web UI AUTOMATIC1111は、開発者のAUTOMATIC氏によってものすごいスピードでアップデートが繰り返されており、また世界中の有志の方達が開発した拡張機能も多数リリースされています。
現在、Stable DiffusionのWeb UIの中では最も高機能でメジャーなプロジェクトとなっています。
 猫のエンジニア
猫のエンジニアネットで活躍しているAI絵師さんは、ほぼ100% AUTOMATIC1111を使ってるよね。
AUTOMATIC1111の公式リポジトリは以下となります。



Web UI AUTOMATIC1111の実行環境とインストール手順
Stable DiffusionとWeb UIはプログラムがオープンソースとして無料公開されているため、そのプログラムを実行する環境を用意する必要があります。
また、Stable Diffusionを実行するマシンには、高性能なGPUを搭載する必要があります。
GPUが必要な理由
AI画像生成の技術、特にStable Diffusionなどの最新の技術は、大量の計算能力を必要とします。
その理由としては、これらのAIモデルが膨大なデータ量を扱い、高度な計算を行うためで、そのプロセスの速度と効率を改善するためには、高性能なグラフィックボード(GPU)が必要となります。
- 並列処理能力: GPUは元々3Dゲームでの複雑な画像処理を行うために開発されたもので、大量の並行処理が可能です。これは、AI画像生成のようなタスクにおいても有用で、大量のデータ点(ピクセル)に対して同時に演算を行うことが可能です。
- 高速なメモリアクセス: GPUは高速な専用メモリ(GDDR6など)を搭載しており、大量のデータを素早く処理することができます。これは、画像の各ピクセルに対して複雑な計算を行うAI画像生成において非常に重要な機能です。
- ディープラーニングライブラリの対応: NVIDIAのCUDAなどのライブラリはGPUに特化しており、TensorFlowやPyTorchなどの主要なディープラーニングライブラリもこれらをサポートしています。これにより、ディープラーニングの計算を効率的に、かつ高速に行うことができます。
Stable Diffusion Web UIを実行するのにおすすめの環境
Stable Diffusionを実行するのにおすすめの環境は、以下の3つがあります。
予算や用途に合わせて選択してください。
- ローカルPC(グラフィックボードを搭載したゲーミングPCなど)
- Google Colaboratory
- Paperspace
ローカルPC
ローカルPCは自宅にあるゲーミングPCなどのグラフィックボードを搭載したPCにStable Diffusionをインストールして使用するケースです。
Stable Diffusion快適に動作させるグラフィックボードは10万円程度~とかなり初期投資が必要になりますが、マシンを用意すればあとは電気代のみで好きな時に好きなだけ使用することが可能です。
初期投資を行える場合は最も理想的な環境となります。
ローカル環境でStable Diffusion及びAUTOMATIC1111 Web UIを使用する方法を、以下の記事で解説しています。

既にDockerを導入されいている方は、Dockerを使って簡単にローカル環境を構築できます。
Dockerでの構築方法は、以下の記事で解説しています。

Google Colaboratory
Google Colaboratoryは、Googleが提供しているクラウドコンピューティングサービスです。
2023年5月現在、Google ColaboratoryでのStable Diffusionの使用は有料プラン契約者のみとなりました。無料プランでStable Diffusionを利用すると、アカウント停止などの措置が取られる可能性がありますのでご注意ください。
無料プランでのStable Diffusionは利用不可。
Google Colaboratoryの有償プランであるPro以上では、クレジット課金制で高性能なGPUを搭載したマシンをブラウザから使用できます。
処理はクラウドで実行されますので、低スペックのPCでも外出先からでもインターネットさえ使えればいつもで画像生成ができるのは大きなメリットです。
 カピパラのエンジニア
カピパラのエンジニアデータ分析や機械学習をやってる人にはなじみのあるサービスだね。
ただし有償プランでも、クレジットを使い切ってしまうと、それほどスペックの高くないフリーマシンしか使用できませんのでご注意ください。
Google Colaboratoryではストレージが用意されていないため、Web UIの設定や拡張機能が毎回リセットされてしまいます。
そのため、使用開始時に毎回自動でインストール、設定されるようJupyter Notebookにコードで実装しておく必要があります。(それなりに知識が必要です)
Google ColaboratoryでStable Diffusion及びAUTOMATIC1111 Web UIを使用する方法を、以下の記事で解説しています。

Paperspace
Paperspaceはアメリカのベンチャー企業が提供するクラウドコンピューティングサービスです。
Google Colaboratoryと同様に、ネット環境さえあればブラウザからいつでもどこでもStable Diffusionを利用することができます。
Google Colaboratoryとの最大の違いは、月額(月8ドル~)の定額制で高性能マシンが使い放題という点です。
ただし、Paperspaceにも一部制約があり、提供されているマシンの台数が決まっているため、マシンが空いていない場合には待ち時間が発生します。
2023年5月現在はユーザー数が増えてきているせいか、マシンの空きがない日が多いですが、しばらくブラウザの前でリロードボタンをクリックしていると、数分の待ちで借りられる時が多いです。
私自身も現在はPaperspaceメインで使用しておりおすすめです。
PaperspaceでStable Diffusion及びAUTOMATIC1111 Web UIを使用する方法を、以下の記事で解説しています。

Web UIの環境設定
AUTOMATIC1111 Web UIを使用する際に設定しておきたい項目について解説します。
Web UIの日本語化
Web UIの表示を日本語化するための手順について、以下の記事で解説しています。
Web UIのアップデート
WebUIは現在も日々開発が継続されており、アップデートにより新機能が提供されています。
WebUIの環境ごとのアップデート方法を、以下の記事で解説しています。

Stable Diffusionのモデルを設定する
Stable Diffusionで画像生成を行うためには、事前にたくさんの画像を使ってトレーニングされたモデルを用意する必要があります。
Web上には様々なモデルが公開されており、自分が生成したい画像に適したモデルを入手、使用して画像生成します。
モデルの設定方法
ダウンロードしたモデルをStable Diffusionのディレクトリに配置します。
実行環境により配置方法が異なりますので、ご利用の環境の項目を参考にしてください。
ローカル環境
ローカル環境で使用する場合は、ローカルPCの以下のディレクトリにモデルファイルを配置してください。
Google Colaboratory
Google Colaboratoryでモデルファイルを配置するディレクトリは以下となります。
Google Colaboratoryの場合は毎回モデルをダウンロードする必要がありますので、自動でダウンロードされるよう以下のコマンドを追加します。
!wget https://civitai.com/api/download/models/15980 -O /content/stable-diffusion-webui/models/Stable-diffusion/museV1_v1.safetensors詳細な追加方法については以下の記事で解説しています。
Paperspace
Paperspaceで使用する場合は、Paperspaceの仮想マシンの以下のディレクトリにモデルファイルを配置してください。
モデルの選択方法
モデルファイルを配置したら、WebUIのを起動します。
WebUIの画面左上のStable Diffusion checkpointと書かれている項目が、画像生成に使用されるモデルを指定する項目となります。
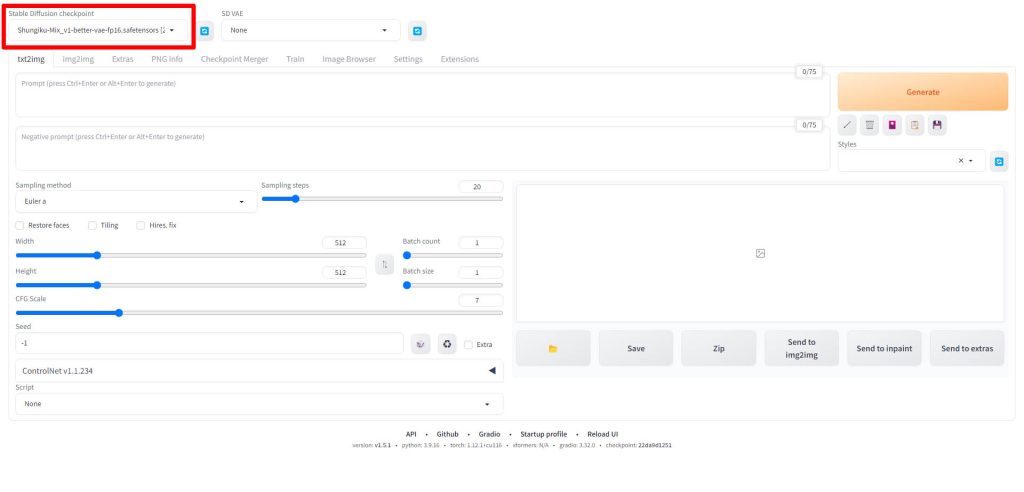
Stable Diffusion checkpointのドロップダウンリストをクリックすると、先ほどのモデルファイルを配置したディレクトリにあるファイルが一覧で表示されますので、使用したいモデルを選択してください。
以上でモデルの設定は完了です。
モデル紹介
ここからは、Stable Diffusionで利用できるモデルを紹介します。
モデルによって生成されるキャラクターや背景の描写などに特徴がありますので、用途に合ったモデルを探してみてください。
Stability AI公式
Stable Diffusionの開発元であるStability AI公式モデルです。
2023年7月にリリースされたモデルSDXL1.0の使い方を、以下の記事で解説しています。

Stable Diffusion 2.1の使い方を、以下の記事で解説しています。

フォトリアル系
実写に近いフォトリアル系のおすすめモデルを、以下の記事で解説しています。

アニメ調
アニメ調のイラストが生成できるおすすめモデルを、以下の記事で解説しています。

自分でマージモデルを作成する方法
Stable Diffusionでは、すでに公開されているモデルを入手して使用する以外に、自分の用途に合わせ、既存のモデルを掛け合わせて独自のマージモデルを作成することができます。
そして、AUTOMATIC1111 Web UIの機能を使うと、機械学習の専門知識無しにモデルの比率を指定するだけで、マージモデルを生成してくれます。
マージモデルの作成方法は、以下の記事で解説しています。

VAEを設定する
VAEは、機械学習の領域で使用される一種のオートエンコーダです。
VAEはモデルと並んで重要な要素であり、どのVAEを選択するかによって生成される画像の色彩などが大きく変わってきます。
カピパラのエンジニアVAEが変わると全く違った印象の絵になるよ。
通常、モデルごとに推奨するVAEが記載されていることが多いため、モデルの配布ページの解説を参考に選定します。
また、モデルによってはVAEを内包しているものもあります。(その場合はVAEは設定不要です)
VAEの設定方法
VAEの設定方法については、以下の記事で解説しています。

おすすめのVAE紹介
Stable Diffusionよく使われるおすすめのVAEを以下の記事で紹介しています。
モデルの配布ページで特に指定がない場合は、こちらの中から選んで使ってみてください。

画像を生成するためのプロンプト(呪文)を作成する
Stable Diffusionの実行環境とモデルを用意したら、最後に画像を生成するためのプロンプト(呪文)を作成します。
プロンプトとは、画像AIにどのような絵を生成させるか指示をするテキストデータになります。
このプロンプトの内容によって、生成される絵のクオリティが大きく左右されるため、重要な要素となります。
フォトリアル系とアニメ調のイラストとでは、プロンプトの特性が大きく異なります。
フォトリアル系プロンプト
フォトリアル系で使用できるプロンプト(呪文)は以下の記事で解説しています。

アニメ調プロンプト
アニメ調で使用できるプロンプト(呪文)は以下の記事で解説しています。

自然言語モデル(LLM)GPT-3でプロンプトを生成する
OpenAIの自然言語モデル(LLM)であるGPT-3を、画像生成AI用にチューニングしたAIツールCatchyで使用できます。特に背景の描写に対する細かい指示などを作成する際に有効です。

Catchyを使って生成したプロンプトのサンプル集を以下の記事で紹介しています。

Web UIでの画像生成の実行
画像生成の方法には、先ほど解説したテキスト(プロンプト)によるtxt2imgと、テキスト+画像で指示をするimg2imgの2種類があります。
txt2imgでの画像生成
テキストで指示するtxt2imgは以下の記事で解説しています。
記事はローカル環境に関する解説ですが、Web UI起動後のプロンプト、パラメータ入力に関しては全ての環境共通で使用できます。
img2imgでの画像生成
テキスト+画像で指示を出すimg2imgについては、以下の記事で解説しています。
img2imgはテキストだけでは難しい、絵の構図などに関する細かい指示も出すことが可能です。
追加学習LoRAでキャラクターやコスチュームを固定する
LoRA(Low-Rank Adaptation)はStable Diffusionの既存モデルを、20枚程度の画像を用いて追加学習させることにより微調整することができる仕組みです。
LoRAを用いることにより、キャラクターや服装などの特徴を固定して画像生成することが可能になります。
学習済みのLoRAファイルを入手する
Civitaiなどのサイトでは、他のユーザーが学習を行ったLoRAファイルを公開しています。
これらのファイルをダウンロードすることで、自分で追加学習を行うことなく手軽に利用することができます。

LoRAで追加学習を行い、LoRAファイルを自作する
少しハードルは上がりますが、自ら学習用の画像を用意して追加学習を行うことで、自分の好みのキャラクターのLoRAファイルを作成することが可能です。
LoRA追加学習の実行方法
LoRAの学習にはsd-scriptsというツールを使用します。
sd-scriptsの環境構築方法を、以下の記事で解説しています。

sd-scriptsを使って追加学習を実行する方法を、以下の記事で解説しています。

LoRA学習用データセット
LoRA使い方を習得する際に、ハードルになるのが学習用の教師データの作成です。
特定のキャラクターを色々な角度、ポーズから撮影、描写した画像を数十枚集める必要がありますが、著作権の問題もあり苦労します。
そこで、企業が非商用であれば無料で使用できるLoRA用データセットを使用するのがおすすめです。
SSS合同会社が無料で公開しているデータセットとその使用方法を、以下の記事で解説しています。

LoRAファイルを使って画像を生成する
入手したLoRAファイルを使って、実際に画像を生成する方法を以下の記事で解説しています。

Web UIの標準機能
WebUIに初期状態で搭載されている、便利な機能について紹介します。
Inpaint
Inpaintの機能を使うと、生成した画像の一部だけを範囲指定して再生成することができます。
破綻してしまった手や顔などを修正するのに便利です。

Web UIの拡張機能(Extensions )
AUTOMATIC1111 Web UIでは、世界中の有志が開発した拡張機能を使用することで、大幅に機能をアップグレードすることができます。
また、拡張機能のインストールはほとんどのものがWeb UI上で追加できます。
今回は公開されている多数の拡張機能の中で、特に有効なものを紹介します。
ControlNet
ControlNetはAUTOMATIC1111 Web UIに様々な機能を追加できるライブラリです。
ControlNetを使用することで、イラストの構図やキャラクターのポーズを自在にコントロールしたり、一部分だけを修正したりすることが可能です。
ControlNetの詳細については以下の記事で解説しています。

アップスケーラ
アップスケーラは、一度生成した画像を拡大、高精細化する機能です。
hires.fix
hires.fixはAUTOMATIC1111 Web UIに標準搭載されている機能です。
hires.fixを使うことで画像サイズを大きくするだけでなく、書き込み量を大幅に増やして高精細な画像にすることが可能です。

LLuL(Local Latent upscaler)
LLuLは画像の一部だけにディティールを追加したい場合に使用できる機能です。
背景や人物の服の装飾のみ、といった適用個所を限定したアップスケールを行い場合に有効です。

MultiDiffusion
MultiDiffusionはimg2imgで画像生成時にも使用可能なアップスケーラです。
画像を複数のエリアに分割して処理するため、少ないVRAM容量のグラフィックボードで大サイズの画像生成が可能です。
カピパラのエンジニアVRAM 8GBのRTX 4000でも1024×1024のサイズの画像が生成できたよ。
MultiDiffusionの詳細については、以下の記事で紹介しています。

Ultimate SD Upscaler
Ultimate SD Upscalerは超高速に大サイズの画像を生成できるアップスケーラです。
Stable Diffusion標準のhires.fixと比較しても遜色のないクオリティの画像を数倍のスピードで生成できますので、特に理由がない場合は、こちらを使用することをおすすめします。
猫のエンジニア当サイトの比較事例ではhires.fixの約4倍の速さ!
Ultimate SD Upscalerの詳細については、以下の記事で紹介しています。

Stable Diffusionのテクニックを効率よく学ぶには?
カピパラのエンジニアStable Diffusionを使ってみたいけど、ネットで調べた情報を試してもうまくいかない…
猫のエンジニアそんな時は、操作方法の説明が動画で見られるUdemyがおすすめだよ!
動画学習プラットフォームUdemyでは、画像生成AIで高品質なイラストを生成する方法や、AIの内部で使われているアルゴリズムについて学べる講座が用意されています。
Udemyは講座単体で購入できるため安価で(セール時1500円くらいから購入できます)、PCが無くてもスマホでいつでもどこでも手軽に学習できます。
Stable Diffusionに特化して学ぶ
Stable Diffusionに特化し、クラウドコンピューティングサービスPaperspaceでの環境構築方法から、モデルのマージ方法、ControlNetを使った構図のコントロールなど、中級者以上のレベルを目指したい方に最適な講座です。
画像生成AIの仕組みを学ぶ
画像生成AIの仕組みについて学びたい方には、以下の講座がおすすめです。
画像生成AIで使用される変分オートエンコーダやGANのアーキテクチャを理解することで、よりクオリティの高いイラストを生成することができます。

まとめ
今回は、Stable DiffusionのWeb UIであるAUTOMATIC1111の使い方について解説しました。
現在でもWeb UIは凄まじいスピードで開発されており、日々新しい拡張機能が登場していますので、今後も随時このページで最新情報をお届けしていく予定です。
また、以下の記事で効率的にPythonのプログラミングスキルを学べるプログラミングスクールの選び方について解説しています。最近ではほとんどのスクールがオンラインで授業を受けられるようになり、仕事をしながらでも自宅で自分のペースで学習できるようになりました。
スキルアップや副業にぜひ活用してみてください。

スクールではなく、自分でPythonを習得したい方には、いつでもどこでも学べる動画学習プラットフォームのUdemyがおすすめです。
講座単位で購入できるため、スクールに比べ非常に安価(セール時1200円程度~)に学ぶことができます。私も受講しているおすすめの講座を以下の記事でまとめていますので、ぜひ参考にしてみてください。

それでは、また次の記事でお会いしましょう。












コメント