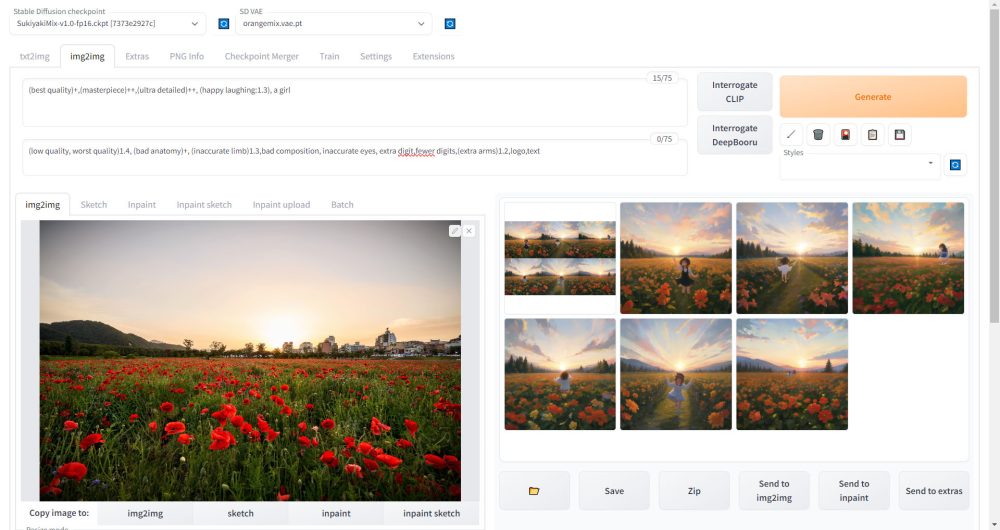

今回はAUTOMATIC1111でimg2imgを使って画像を生成する手順を解説します。img2imgを使うと、プロンプトの文字列での指示に加えて、画像を読み込んで構図を細かく指示することができますので、ぜひ活用してみてください。
また、当ブログのStable Diffusionに関する記事を以下のページでまとめていますので、あわせてご覧ください。

Stable Diffusionの導入方法から応用テクニックまでを動画を使って習得する方法についても以下のページで紹介しています。

Stable Diffusionとは
Stable Diffusion(ステーブル・ディフュージョン)は2022年8月に無償公開された描画AIです。ユーザーがテキストでキーワードを指定することで、それに応じた画像が自動生成される仕組みとなっています。
NVIDIAのGPUを搭載していれば、ユーザ自身でStable Diffusionをインストールし、ローカル環境で実行することも可能です。
(出典:wikipedia)
Stable DiffusionのWeb UI AUTOMATIC1111
AUTOMATIC1111はStable Diffusionをブラウザから利用するためのWebアプリケーションです。
AUTOMATIC1111を使用することで、プログラミングを一切必要とせずにStable Diffusionで画像生成を行うことが可能になります。
Web UI AUTOMATIC1111のインストール方法
Web UIであるAUTOMATIC1111を実行する環境は、ローカル環境(自宅のゲーミングPCなど)を使用するか、クラウドコンピューティングサービスを利用する2通りの方法があります。
以下の記事ではそれぞれの環境構築方法について詳し解説していますので、合わせてご覧ください。
img2img(Image-to-Image Translation) とは
従来の文章での指示をAIに入力して画像を生成する方法をtxt2img(Text-to-Image Translation)と言います。
それに対し、img2imgでは画像+文字を入力して画像を生成します。
これにより、文字だけでは難しい詳細な構図を、あらかじめ用意した写真や画像を使って指示することができます。
Stable Diffusionではimg2imgを使ったイラスト生成の機能も備えていますので、今回はAUTOMATIC1111でimg2imgを使って生成する方法を解説します。
img2img使用するメリット
構図を細かく指示できる
通常txt2imgで生成する画像を指示する場合、人物、キャラクターの特徴や大まかなシチュエーションは指示できますが、人物の立ち位置や背景の建物の位置、ライティングなどを詳細に文字で指示するのは困難です。
そのような場合に、img2imgを用いることで画像を使って絵の構図を詳細に指示することが可能になります。
以下の例では実写の風景写真を元に、アニメ調モデルを使ってimg2imgでイラストを生成したものです。

このように文字では指示が難しい細かい構図も再現することができます。
理想の絵が出るまでのトライ回数を削減できる
通常、Sampling stepsを40程度の実用レベルで使用できる値に設定し、ランダムで1024*1024以上の大サイズの画像をランダムに生成するには非常に時間がかかります。
このような場合に、まず小さい画像サイズでSeed値をランダムで大量の画像を生成しておいて、気に入った絵がでたら、そのSeed値を使ってimg2imgで高解像度の画像を生成することで、理想的なイラストを生成するまでの時間を大幅に削減することが可能です。
以下は512*512で生成した画像を、img2imgを使って1024*1024にアップスケールした例です。

このようにステップ数とSeed値を固定することで、元の絵柄をほぼ維持できます。
Seed値の詳細については以下の記事で解説していますので、あわせてご覧ください。

大きなサイズの画像を生成できる
前項でも解説しましたが、img2imgを使用することで、大サイズの画像を生成することができます。Stable Diffusionで使用するモデルは、512*512のサイズの画像を使ってトレーニングされています。そのため、いきなり大サイズの画像をtxt2imgで生成すると絵が破綻してしまいます。
しかし、一旦txt2imgで512*512~768*768程度のサイズで生成しておいて、それをimg2imgで2~2.5倍程度のサイズで再生成することで、絵が破綻することなく生成することが可能です。

img2imgで画像を生成する手順
img2imgの生成元となる画像を用意する
まずはimg2imgで読み込む画像を用意します。
今回はフリー素材サイトで入手できる以下の花畑の実写を用意しました。

入手先サイトは以下となります。たくさんの画像素材がありますので、好きな画像をダウンロードしてください。


AUTOMATIC1111でimg2imgを使って画像を生成する
ここからは実際にAUTOMATIC1111で先ほど用意した画像を読み込み、img2imgで画像を生成する手順を解説します。
まずAUTOMATIC1111のWebUIを起動したら、「img2img」のタブをクリックします。
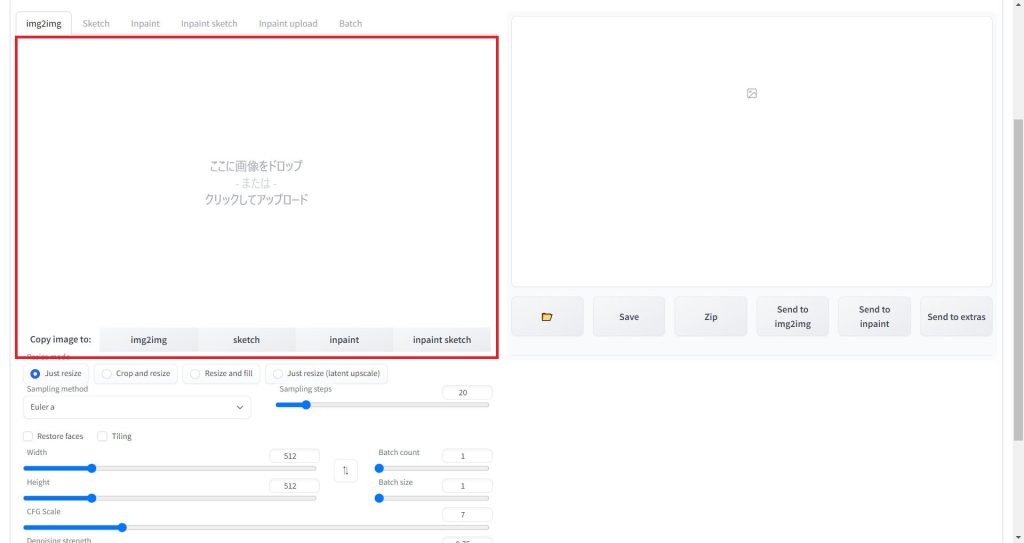
タブを切り替えると以下の赤枠の画像をアップロードする画面が表示されます。この赤枠の中に読み込みたい画像ファイルをドラッグ&ドロップします。
アップロードが完了すると、以下のように読み込んだ画像が表示されます。
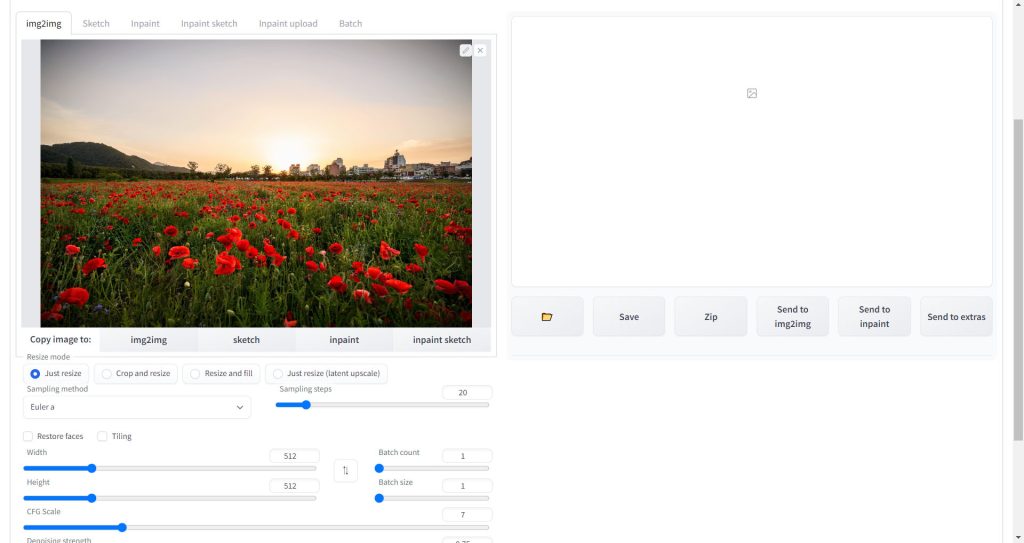
続いて、使用する学習済みモデルを選択しプロンプトを入力します。
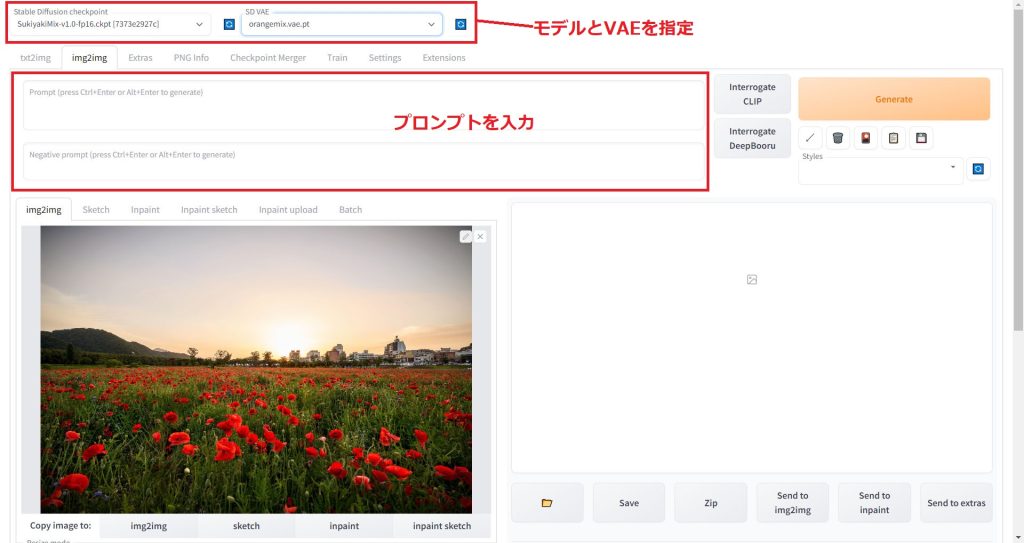
プロンプトの作成が難しいと思われている方には、AIでプロンプトを自動生成するのがおすすめです。「StableDiffusionのプロンプト(呪文)を自然言語処理モデルGPT-3(Catchy)で自動生成する方法」で詳細を解説しています。
最後に以下の赤枠のパラメータを入力します。
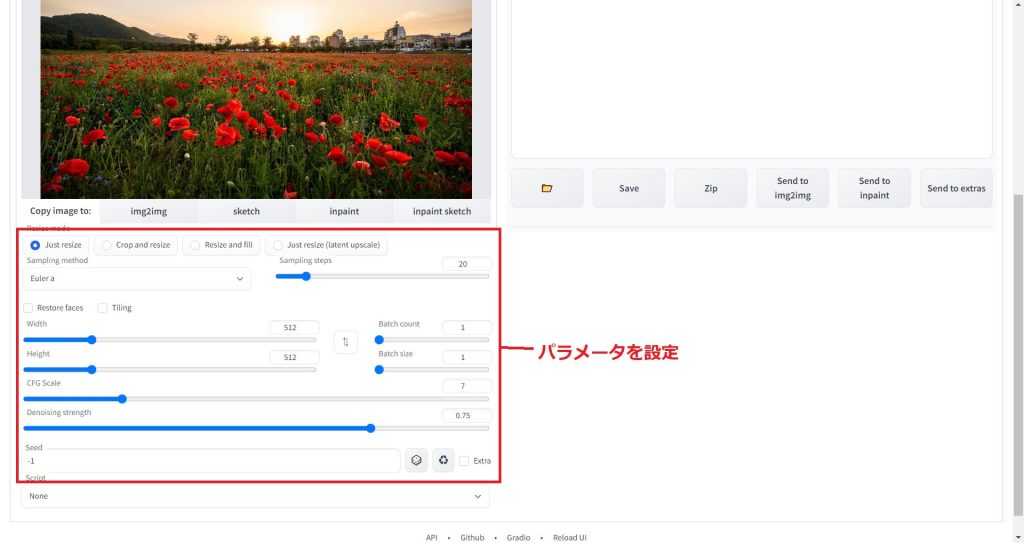
パラメータの内容については、以下の記事で解説していますので、参考にしてください。

入力が終わったら「Generate」ボタンをクリックします。これで画像が生成されます。
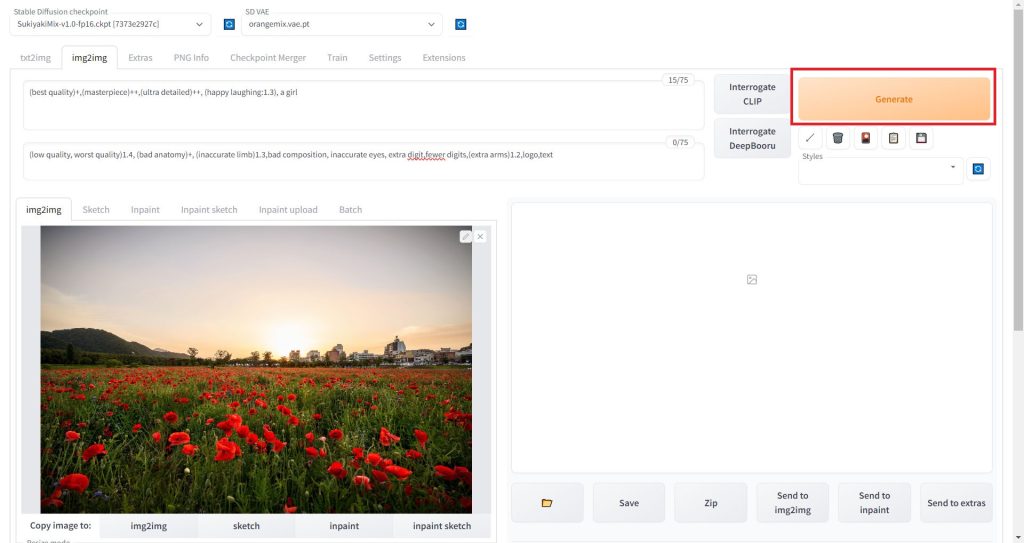
img2imgで生成された画像を保存する
画像の生成が完了すると、右側の赤枠の部分に生成された画像のプレビューが表示されます。
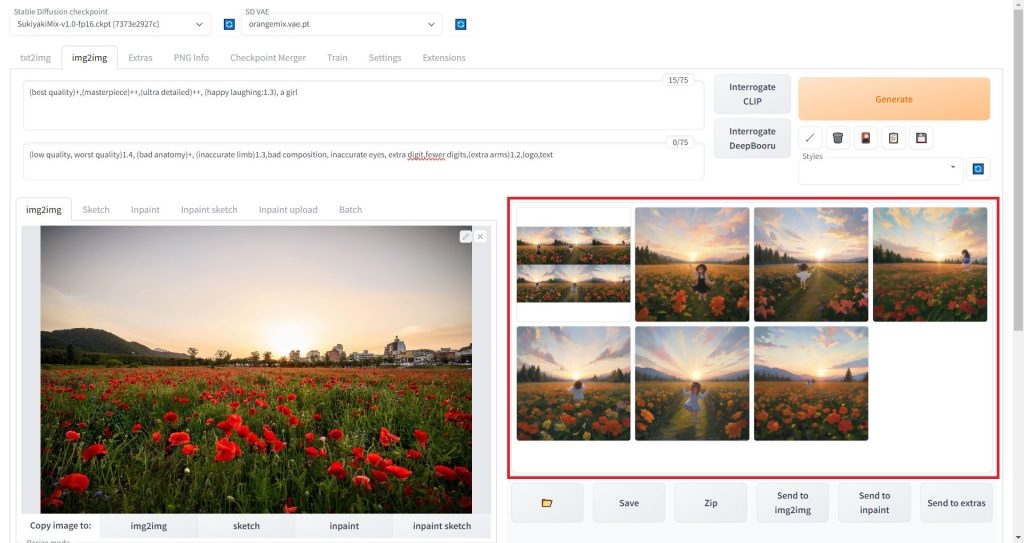
保存したいが像をクリックすると、以下のように大きなプレビュー画像が表示されます。
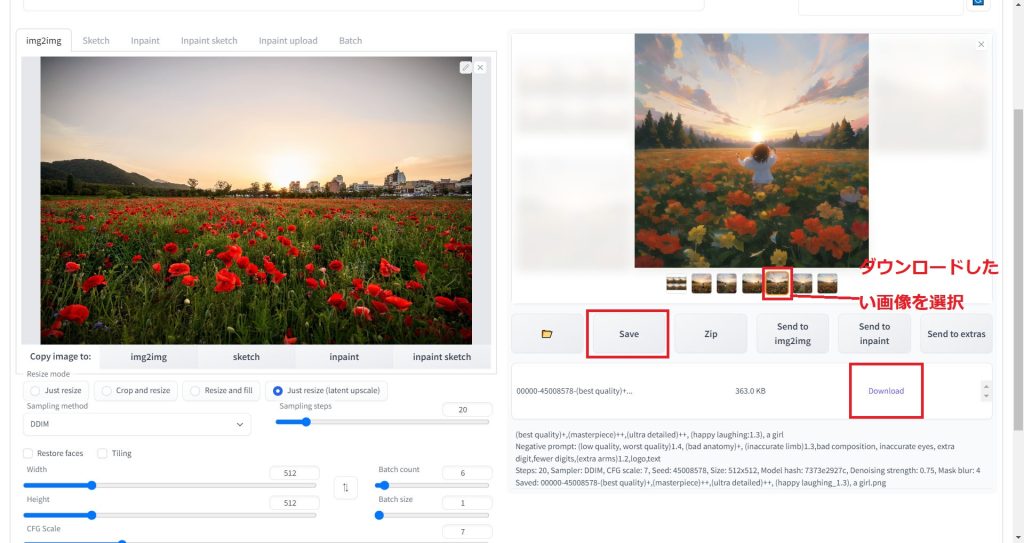
ダウンロードしたい画像が選択されている状態で「Save」ボタンをクリックすると、ダウンロードリンクが表示されます。
ダウンロードリンクをクリックしてファイルを保存してください。
img2imgの実行結果
今回行った具体例を解説します。
img2imgの元画像
まず、元となる画像は先ほどのフリー素材の花畑の写真です。
風景だけで人物は写っていません。
使用したプロンプト
今回は風景写真に人物を追加するため、以下のようなプロンプトを用意しました。
プロンプト
(best quality)+,(masterpiece)++,(ultra detailed)++, (happy laughing:1.3), a girlネガティブプロンプト
(low quality, worst quality)1.4, (bad anatomy)+, (inaccurate limb)1.3,bad composition, inaccurate eyes, extra digit,fewer digits,(extra arms)1.2,logo,text実行結果
生成時間を速くするため、Step数を低く設定しているのであまり精細に描画できていませんが、読み込んだ画像とほぼ同じ構図の花畑に、少女が立っているイラストを生成することができました。

全く同じ画像、プロンプトでシード値が違う画像です。

このように、img2imgを使うことで、絵の構図を細かく指定してイラストを生成できることが確認できました。
img2imgのパラメータの設定方法
ここからはimg2imgのパラメータ設定方法について解説します。
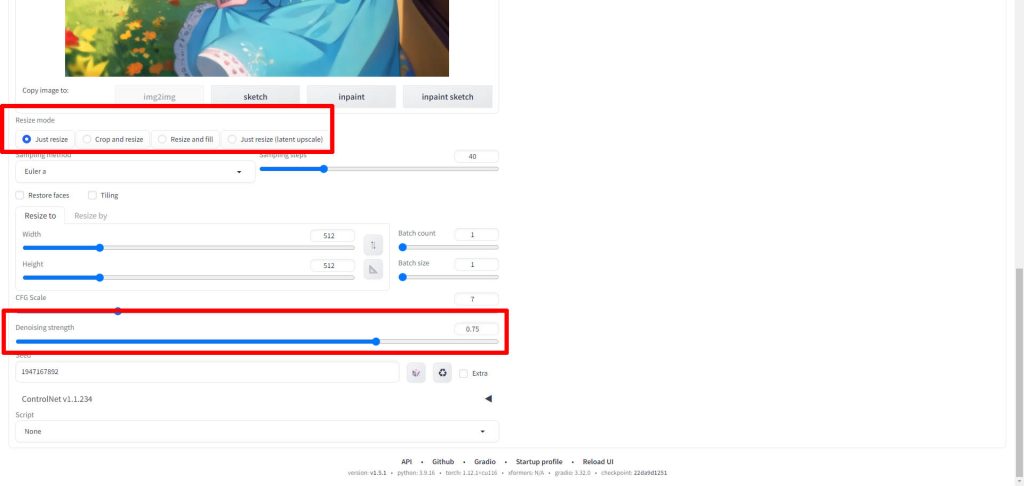
img2imgでは、以下のようにResize modeとDenoising strengthのパラメータが追加されます。
Resize mode
Stable Diffusionのimg2imgには、リサイズモードとして4つのオプションが存在します。これらのオプションは以下の通りです。
- Just resize: このモードでは、指定されたサイズに画像をリサイズします。例えば、512×500の画像を1024×1024に生成するよう指示した場合、アスペクト比を無視して画像をストレッチします。
- Crop and resize: このモードでは、まず画像を一定のサイズ(例えば500×500)にクロップし、その後指定されたサイズ(例えば1024×1024)にリサイズします。アスペクト比は維持されますが、画像の左右の一部が失われる場合があります。
- Resize and fill: このモードでは、新しいノイズを追加して画像を一定のサイズ(例えば512×512)にパディングし、その後指定されたサイズ(例えば1024×1024)にリサイズします。
- Just resize (latent upscale): このモードは最初のオプションと同じですが、latent upscaling(潜在的なアップスケーリング)を使用します。
以下が各モードでの出力結果の比較です。
512*512サイズの元画像を、img2imgでアスペクト比の異なる1200*1000サイズで出力します。
元画像

Just resize

Corp and resize

Resize and fill

Just resize(latent upscale)

Denoising strength
img2imgでの生成時に使用できるパラメータDenoising Strengthについて解説します。
このパラメータは、入力画像にどれだけのノイズを加えるかを制御します。具体的には以下のように動作します。
- Denoising Strengthの値が0の場合:この設定では、ノイズは一切加えられず、出力画像は入力画像と全く同じになります。
- Denoising Strengthの値が1の場合:この設定では、入力画像は完全にノイズに置き換えられます。
Denoising Strengthの値が小さいほど、元画像に近くなり、値が大きいほど自由度が上がる(元画像と乖離した画像が出力される)という効果があります。
Denoising strengthの影響度を比較した例を以下に示します。
元画像
こちらが元画像です。この画像をimg2imgで2倍のサイズ(1024*1024)に拡張する際のDenoising strengthのパラメータの影響度を比較します。

Denoising strength:0.75(デフォルト)
Denoising strengthをデフォルト値の0.75に設定した場合の出力結果です。
構図はおおむね維持されていますが、キャラクターの防止が増えていたり、服装にリボンが付いたといった変化が確認できます。

Denoising strength:1
Denoising strengthを最大値の1に設定した場合の出力結果です。
服装だけでなく地形も変化し、キャラクター横の家も消えています。

Denoising strength:0.2
Denoising strengthを最小値に近い0.2に設定した場合の出力結果です。
元画像からほとんど変化がない状態で、画像サイズだけを拡大することができました。

このようにDenoising strengthのパラメータの値によって、元の画像からどの程度の自由度を持たせて画像を生成するかを制御できることが確認できました。
img2imgで画像の一部を修正するInpaint
WebUIの標準機能であるInpaintを使って、img2imgの画像生成時に一部だけを修正することが可能です。Inpaintの詳細な使い方は、以下の記事で解説しています。

img2imgで画像生成時にアップスケーラで画像を高精細化する
今回はimg2imgの使用方法を解説しましたが、AUTOMATIC1111の拡張機能であるMultiDiffusionを使用することで、画像をアップスケールすることが可能です。
ベースの画像の構図を維持したまま、サイズを拡大、書き込み量を増やして高精細化することができます。
MultiDiffusionの使い方は以下の記事で解説しています。

Stable Diffusionのテクニックを効率よく学ぶには?
 カピパラのエンジニア
カピパラのエンジニアStable Diffusionを使ってみたいけど、ネットで調べた情報を試してもうまくいかない…
 猫のエンジニア
猫のエンジニアそんな時は、操作方法の説明が動画で見られるUdemyがおすすめだよ!
動画学習プラットフォームUdemyでは、画像生成AIで高品質なイラストを生成する方法や、AIの内部で使われているアルゴリズムについて学べる講座が用意されています。
Udemyは講座単体で購入できるため安価で(セール時1500円くらいから購入できます)、PCが無くてもスマホでいつでもどこでも手軽に学習できます。
Stable Diffusionに特化して学ぶ
Stable Diffusionに特化し、クラウドコンピューティングサービスPaperspaceでの環境構築方法から、モデルのマージ方法、ControlNetを使った構図のコントロールなど、中級者以上のレベルを目指したい方に最適な講座です。
画像生成AIの仕組みを学ぶ
画像生成AIの仕組みについて学びたい方には、以下の講座がおすすめです。
画像生成AIで使用される変分オートエンコーダやGANのアーキテクチャを理解することで、よりクオリティの高いイラストを生成することができます。
まとめ
今回はAUTOMATIC1111でimg2imgを使ってイラスト生成する方法を紹介してみました。img2imgを使用することで生成する画像の構図を細かく指示することが可能ですので、ぜひ活用してみてください。
また、以下の記事で効率的にPythonのプログラミングスキルを学べるプログラミングスクールの選び方について解説しています。最近ではほとんどのスクールがオンラインで授業を受けられるようになり、仕事をしながらでも自宅で自分のペースで学習できるようになりました。
スキルアップや副業にぜひ活用してみてください。

スクールではなく、自分でPythonを習得したい方には、いつでもどこでも学べる動画学習プラットフォームのUdemyがおすすめです。
講座単位で購入できるため、スクールに比べ非常に安価(セール時1200円程度~)に学ぶことができます。私も受講しているおすすめの講座を以下の記事でまとめていますので、ぜひ参考にしてみてください。

それでは、また次の記事でお会いしましょう。



参考












コメント