
画像生成AIであるStable Diffusionでは、プロンプト(呪文)によって画像の内容指示することで意図した構図、画風に近づけることが重要でした。
実際に生成される画像はランダム(ガチャ)要素が高く、かなりの回数を試行しないとイメージ通りの画像が生成されません。
しかし、Stable Diffusionの拡張機能であるControlNetを使用することで、構図やキャラクターのポーズを自在にコントロールすることが可能になります。
この記事では、ControlNetとStable Diffusionの基本から、具体的な応用例、そしてこれらの技術を最大限に活用する方法まで、幅広く解説します。
- ControlNetの概要
- ControlNetのインストール方法
- ControlNetで使用できるモデルとその機能
- ControlNetを使った画像の生成手順
また、当ブログのStable Diffusionに関する記事を以下のページでまとめていますので、あわせてご覧ください。

Stable Diffusionの導入方法から応用テクニックまでを動画を使って習得する方法についても以下のページで紹介しています。

Stable Diffusionとは
Stable Diffusion(ステーブル・ディフュージョン)は2022年8月に無償公開された描画AIです。ユーザーがテキストでキーワードを指定することで、それに応じた画像が自動生成される仕組みとなっています。
NVIDIAのGPUを搭載していれば、ユーザ自身でStable Diffusionをインストールし、ローカル環境で実行することも可能です。
(出典:wikipedia)
Stable DiffusionのWeb UI AUTOMATIC1111
AUTOMATIC1111はStable Diffusionをブラウザから利用するためのWebアプリケーションです。
AUTOMATIC1111を使用することで、プログラミングを一切必要とせずにStable Diffusionで画像生成を行うことが可能になります。
Web UI AUTOMATIC1111のインストール方法
Web UIであるAUTOMATIC1111を実行する環境は、ローカル環境(自宅のゲーミングPCなど)を使用するか、クラウドコンピューティングサービスを利用する2通りの方法があります。
以下の記事ではそれぞれの環境構築方法について詳し解説していますので、合わせてご覧ください。
ControlNetとは
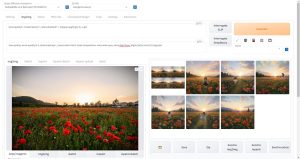
ControlNetとは、Stable DiffusionのWebUIであるAUTOMATIC1111に拡張機能としてインストールすることで、Stable Diffusionで生成される画像の内容を細かく制御することができる機能です。
従来のプロンプト(文字列)による指示では、絵の構図やキャラクターのポーズなどを細かく指示するのには限界があり、ランダム要素で自分の理想の絵が生成されるまでトライする必要がありました。
しかし、ControlNetを使用することで、事前に別の画像や深度情報を機械学習モデルを使って読み込み、その内容を指示として、生成する画像をコントロールできます。
また、ControlNetはWebUIの機能としてしようできるため、プログラミングや機械学習の知識を必要とせず、以下のようにGUI上で全ての機能を使用することができます。

ControlNetの使用例
ここからはControlNetの使用例について紹介します。
ポーズを指定する
ControlNetでは以下のようにキャラクターのポーズを棒人間を操作して作成することが可能です。
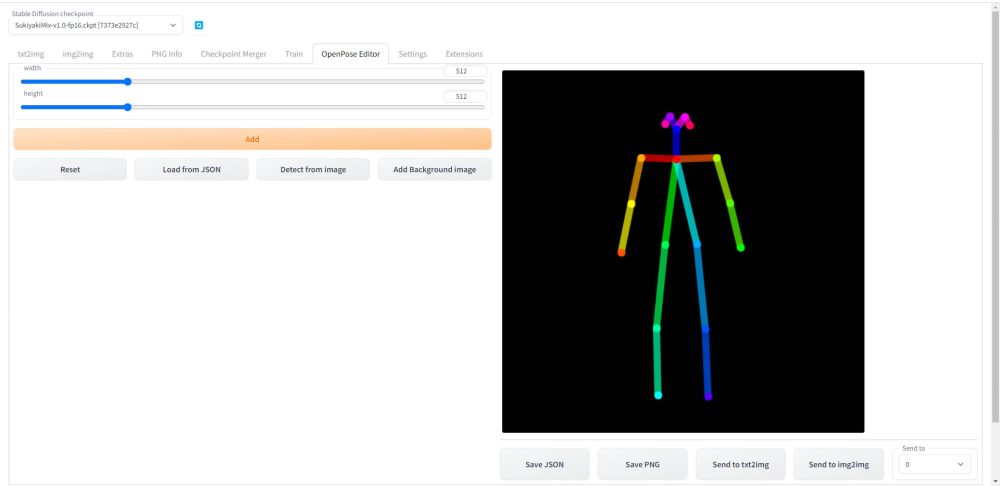
そしてこの棒人間で作ったポーズや、人物を絵のどのあたりの位置に配置するかといった構図についても指示することができます。

詳細は「Stable DiffusionでControlNetを使ってキャラクターのポーズを指定する方法」の項目をご覧ください。
手の形を補正する
以下のように、手のポーズライブラリと、それに対応した深度情報を読み込むことで、キャラクターの手の部分だけを修正することも可能です。
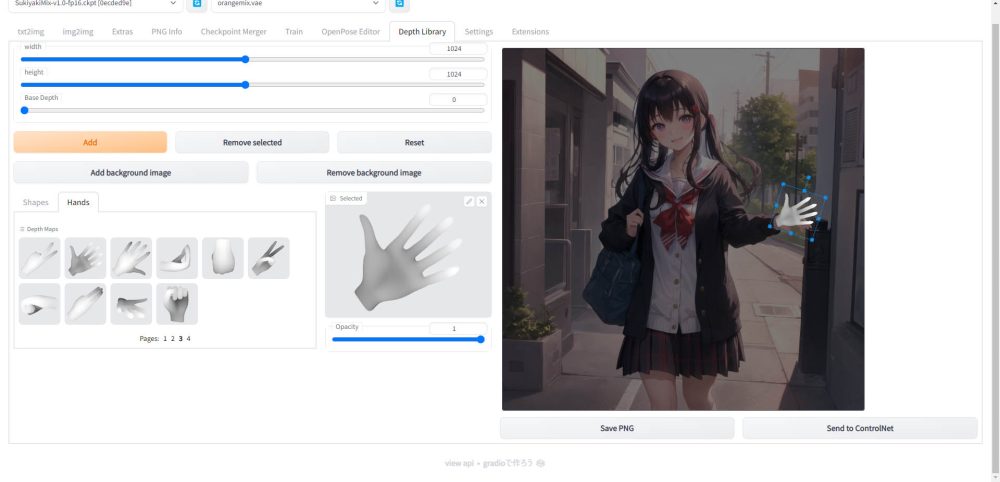
通常であれば、手の部分だけが失敗してしまった場合でも全体を生成し直す必要がありましたが、ControlNetを使うと手だけを任意の形状に修正することができます。

詳細は「Depth map library and poser」の項目をご覧ください。
ControlNetのインストール
Stable DiffusionのWeb UIであるAUTOMATIC1111にControlNetのインストール方法について、以下の記事で詳しく説明しています。
後程、紹介するControlNetを使った画像生成で必要となりますので、あらかじめ済ませておいてください。

ControlNetで使用できるモデルと機能
ControlNetでは様々な機能を持ったモデルが用意されています。
これらのモデルを事前にStable Diffusionの指定のフォルダにインストールすることで、WebUI上から使用することが可能になります。
モデルの機能一覧
各モデルの機能は以下となります。
| モデル名 | 機能説明 |
|---|---|
| control_v11p_sd15_canny | エッジ検出を強化したモデル。画像のエッジを強調して生成します。 |
| control_v11p_sd15_mlsd | 線分検出に特化したモデル。画像内の線分を明確に検出します。 |
| control_v11f1p_sd15_depth | 深度情報を取得するモデル。3D空間の深度を表現します。 |
| control_v11p_sd15_normalbae | 通常の画像生成に適したベーシックモデル。 |
| control_v11p_sd15_seg | 画像のセグメンテーションを行うモデル。物体の境界を特定します。 |
| control_v11p_sd15_inpaint | 画像の欠損部分を補完するモデル。 |
| control_v11p_sd15_lineart | ラインアートの生成に特化したモデル。 |
| control_v11p_sd15s2_lineart_anime | アニメ風のラインアートを生成するモデル。 |
| control_v11p_sd15_openpose | 人物のポーズを検出するモデル。 |
| control_v11p_sd15_scribble | スクリブル(落書き)を基に画像を生成するモデル。 |
| control_v11p_sd15_softedge | エッジの滑らかな画像を生成するモデル。 |
| control_v11e_sd15_shuffle | 画像の要素をシャッフルして新しい画像を生成するモデル。 |
| control_v11e_sd15_ip2p | 画像間の変換を行うモデル。 |
| control_v11f1e_sd15_tile | タイル状の画像を生成するモデル。 |
各モデルの詳細は以下の公式リポジトリで解説されています。

モデルの入手と配置
モデルの入手方法とインストールについて解説します。
.safetensorsファイルを配置する
以下の.safetensorsファイルのダウンロードページにアクセスします。

以下のページから使用したいモデルの.safetensorsファイルをダウンロードします
ダウンロードした.safetensorsファイルを以下のディレクトリに配置してください。
.pthファイルを配置する
以下の.pthファイルのダウンロードページにアクセスします。

一覧の中から使用したいモデルの拡張子.pthのファイルをダウンロードします。
ダウンロードしたファイルを以下のディレクトリに配置してください。
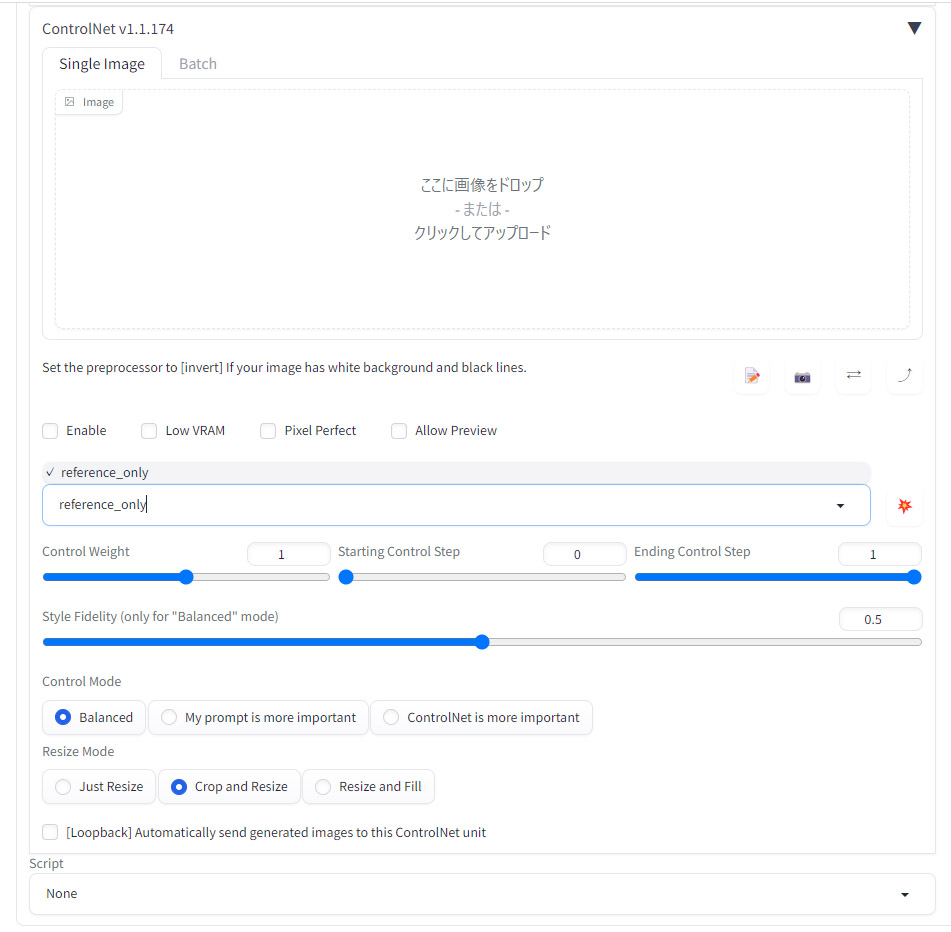
また、こちらの一覧に無いモデルも順次ControlNetのアップデートにて標準機能で使えるモデルとして追加されていっています。各モデルの詳細な機能と使い方は、reference_onlyなど後程紹介する個別の項目をご覧ください。
ControlNetの基本的な使い方
ここからは、具体的にControlnetを使って画像を生成する手順を解説します。
今回は例として、ControlNetで使用できるエッジ(輪郭)検出モデルであるcannyを例に説明します。
cannyは既に所有している別の画像を読み込んで画像のエッジを検出し、その情報を読み込んで別のモデルで生成する際に構図などを再現することが可能です。(もちろん同じモデルでも可能です)
モデルのダウンロード
まずcannyのモデルをダウンロードします。
以下のHugging Faceのページからモデルをダウンロードし、先ほど解説したStable Diffusionのディレクトリに配置してください。
cannyで検出したエッジ(輪郭)を元に画像を生成する手順
WebUIを起動したら、ControlNetの項目をクリックします。
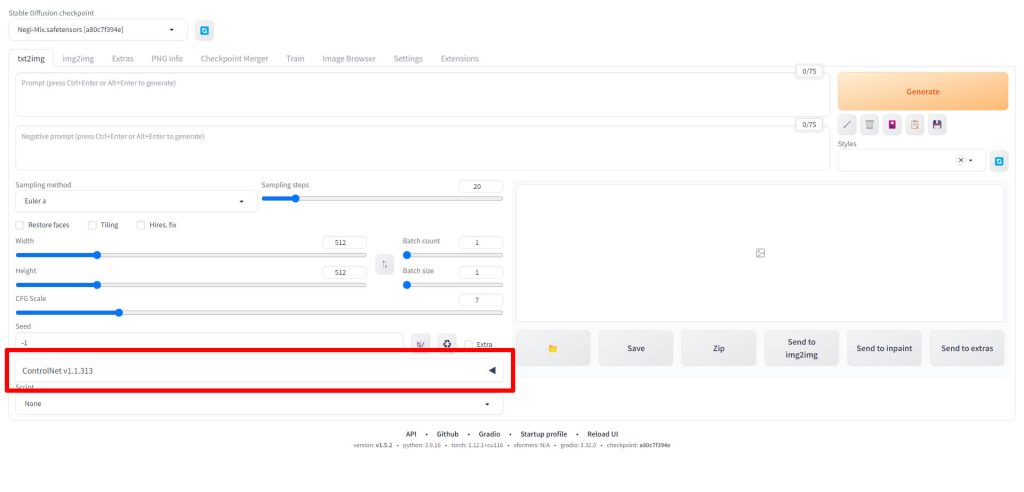
ControlNetの項目が展開されたら、赤枠のSingle Imageのエリアにエッジ検出の対象となる画像をドラッグ&ドロップします。
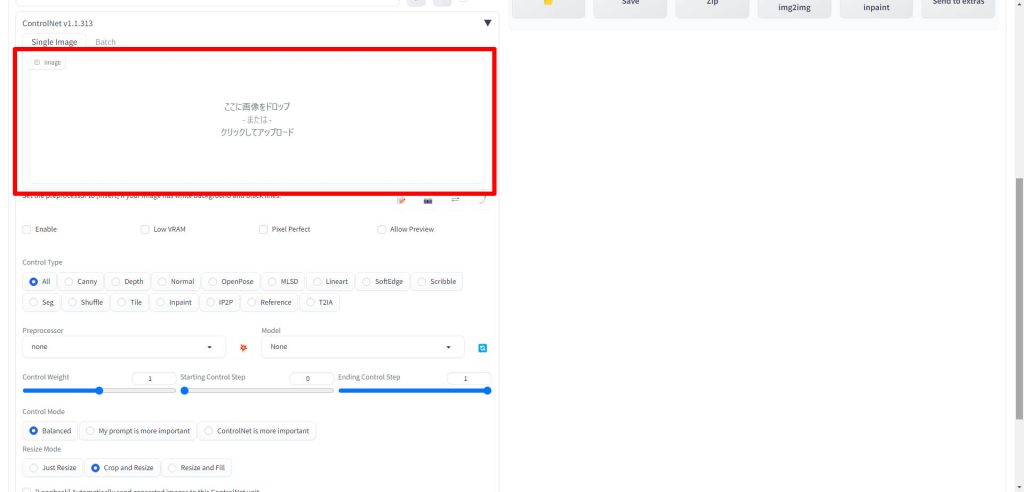
画像が読み込まれると、Single Imageに表示されます。
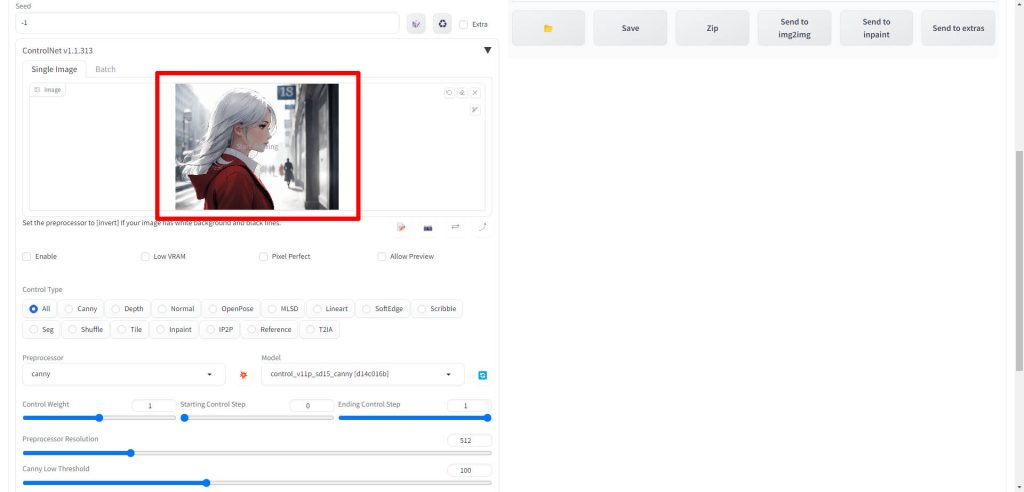
EnableとPixel PerfectのチェックボックスをONにします。
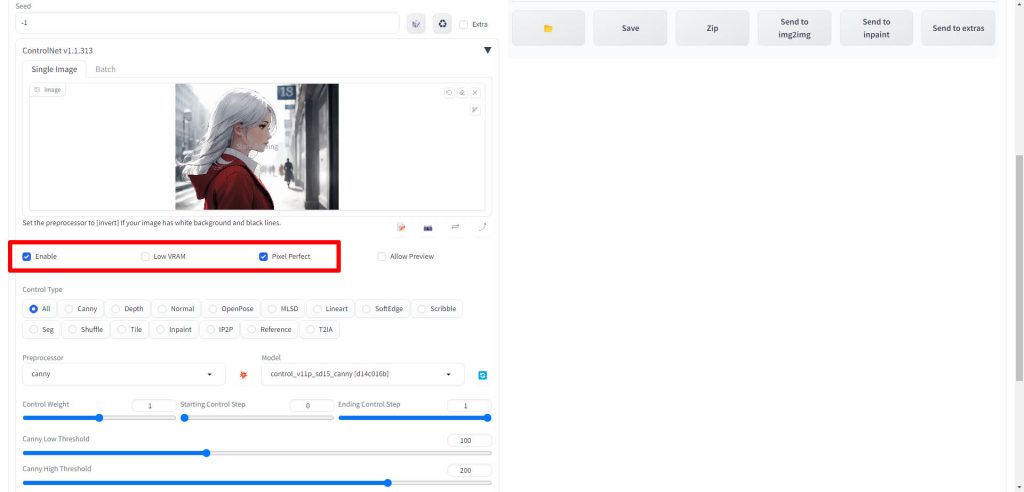
Preprocessorの項目をcannyに、Modelの項目をcontrol_v11p_sd15_cannyに設定します。
ここでcannyがリストに表示されない場合は、モデルの配置場所などを見直してください。
以上で最低限のパラメータ設定は完了しましたので、Generateをクリックして画像生成を実行します。
画像生成が完了すると、以下のように生成された画像と一緒に検出されたエッジ情報も表示されます。
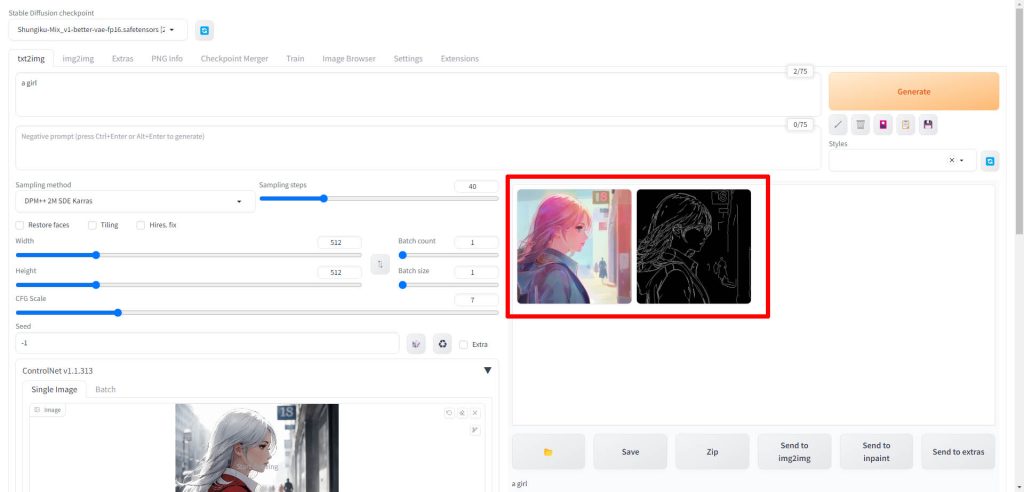
生成された画像の比較
ここからは、実際にcannyを使って生成された画像を確認していきます。
元画像
こちらが元画像です。この画像をcannyで読み込み、エッジ(輪郭)を検出します。

検出されたエッジ
こちらが検出されたエッジです。人物と大まかな背景が正しく検出できています。

生成画像
こちらが先ほどcannyで検出したエッジを元に別のモデルで生成した画像です。モデルを変更していますので、絵のタッチは変わっていますが、構図はしっかりと再現できています。

アップスケールした画像
先ほどの画像をhires.fixで2倍の画像サイズで描画した画像です。アップスケールしても、正しく検出したエッジが反映されていることが確認されました。

今回はcannyを使って手順を解説しましたが、ControlNetにはほかにも様々な機能を持ったモデルが用意されています。
以降の項目で紹介しますので、ぜひ試してみてください。
Stable DiffusionでControlNetを使ってキャラクターのポーズを指定する方法
Stable DiffusionとControlNetを使用して、特定のキャラクターポーズを生成する方法について詳しく説明しています。
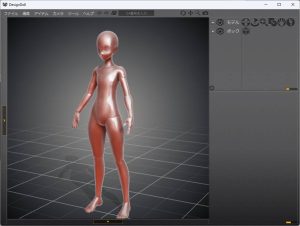
デザインドール(DESIGN DOLL)でControlNetのポーズデータを作る方法
ControlNetで使用するポーズデータを作成するためのソフトウェア、デザインドール(DESIGN DOLL)の使い方について詳しく説明しています。
デザインドールを使用してポーズを作成し、そのデータをControlNetで読み込んで画像生成することで、絵の構図をコントロールすることができます。
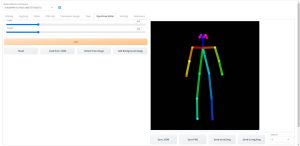
ControlNetでポーズデータを読み込んで画像を生成する
デザインドール等で作成したポーズデータを、ControlNetで利用可能なOpenPoseという機械学習ライブラリで読み込んで骨格検出を行い、その情報を元にStable Diffusionで特定のキャラクターポーズを生成するための手順を解説しています。

Openpose Editorを使ってポーズデータを作成し、画像を生成する
AUTOMATIC1111の拡張機能であるOpenpose Editorのインストールと使い方について解説しています。
Openpose Editorは、ControlNetでOpenposeのモデルを使って画像生成をする際に、あらかじめ外部ツールでポーズデータを作成し、それを読み込んで使う必要があったのを解消します。
Openpose Editorを使用することで、AUTOMATIC1111のWebUI内でポーズデータの生成までを行うことが可能になります。
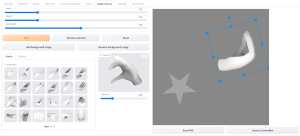
Depth map library and poser(深度ライブラリ)
以下の記事では、ControlNetの拡張機能であるDepth map library and poserのインストール方法について詳しく解説しています。
Depth map library and poserは、AIで生成したイラストの手の部分だけを修正することができるため、AIで生成したイラストに手の部分だけがおかしいという問題がある場合には非常に有用なツールとなります。
不自然な手を修正する方法
以下のでは、Depth map library and poserとControlNetを使って、手の描画を失敗した絵を修正する手順を詳しく説明しています。Depthライブラリで作成した深度データをControlNetで読み込み、それを元に手の部分を修正します。

reference_onlyで1枚の画像から同じキャラクターのイラストを生成する
ControlNetの機能であるreference_onlyを使用すると、LoRAのように追加学習等は行わずに、1枚の画像からそこに描かれているキャラクターを、別の構図、ポーズで描画することができます。
LoRAのデータセットとして使用する画像の生成等にも使用することができます。

tile_resampleで書き込み量を増やす
ControlNetで使用できるプリプロセッサ、tile_resampleを使ってイラストの書き込み量を増やす方法について、以下の記事で解説しています。
書き込み量を増やす以外にも、画像サイズを拡大する場合に元の絵柄を保持するという役割もあります。アップスケーラーとの併用でも活用できます。

Stable Diffusionのテクニックを効率よく学ぶには?
 カピパラのエンジニア
カピパラのエンジニアStable Diffusionを使ってみたいけど、ネットで調べた情報を試してもうまくいかない…
 猫のエンジニア
猫のエンジニアそんな時は、操作方法の説明が動画で見られるUdemyがおすすめだよ!
動画学習プラットフォームUdemyでは、画像生成AIで高品質なイラストを生成する方法や、AIの内部で使われているアルゴリズムについて学べる講座が用意されています。
Udemyは講座単体で購入できるため安価で(セール時1500円くらいから購入できます)、PCが無くてもスマホでいつでもどこでも手軽に学習できます。
Stable Diffusionに特化して学ぶ
Stable Diffusionに特化し、クラウドコンピューティングサービスPaperspaceでの環境構築方法から、モデルのマージ方法、ControlNetを使った構図のコントロールなど、中級者以上のレベルを目指したい方に最適な講座です。
画像生成AIの仕組みを学ぶ
画像生成AIの仕組みについて学びたい方には、以下の講座がおすすめです。
画像生成AIで使用される変分オートエンコーダやGANのアーキテクチャを理解することで、よりクオリティの高いイラストを生成することができます。
まとめ
今回はControlNetのインストール方法と活用方法について解説しました。
ControlNetを導入することで生成できる画像の自由度が大幅に向上します。今後もこの記事でControlNetの新機能に関する解説を追加していきます。
また、以下の記事で効率的にPythonのプログラミングスキルを学べるプログラミングスクールの選び方について解説しています。最近ではほとんどのスクールがオンラインで授業を受けられるようになり、仕事をしながらでも自宅で自分のペースで学習できるようになりました。
スキルアップや副業にぜひ活用してみてください。

スクールではなく、自分でPythonを習得したい方には、いつでもどこでも学べる動画学習プラットフォームのUdemyがおすすめです。
講座単位で購入できるため、スクールに比べ非常に安価(セール時1200円程度~)に学ぶことができます。私も受講しているおすすめの講座を以下の記事でまとめていますので、ぜひ参考にしてみてください。

それでは、また次の記事でお会いしましょう。













コメント