

Stable Diffusionは、AIを用いて画像を生成するための強力なツールです。
そのWebUI、AUTOMATIC1111には、画像生成の作業をより効率的に、そしてより簡単に行うための様々な拡張機能が存在します。
本記事では、その中でも特におすすめの拡張機能をピックアップし、それぞれの機能とその使い方について詳しく解説します。
- 目的ごとのWebUIおすすめの拡張機能
- 各拡張機能のインストール方法と使用方法
また、当ブログのStable Diffusionに関する記事を以下のページでまとめていますので、あわせてご覧ください。

Stable Diffusionの導入方法から応用テクニックまでを動画を使って習得する方法についても以下のページで紹介しています。

Stable Diffusionとは
Stable Diffusion(ステーブル・ディフュージョン)は2022年8月に無償公開された描画AIです。ユーザーがテキストでキーワードを指定することで、それに応じた画像が自動生成される仕組みとなっています。
NVIDIAのGPUを搭載していれば、ユーザ自身でStable Diffusionをインストールし、ローカル環境で実行することも可能です。
(出典:wikipedia)
Stable DiffusionのWeb UI AUTOMATIC1111
AUTOMATIC1111はStable Diffusionをブラウザから利用するためのWebアプリケーションです。
AUTOMATIC1111を使用することで、プログラミングを一切必要とせずにStable Diffusionで画像生成を行うことが可能になります。
Web UI AUTOMATIC1111のインストール方法
Web UIであるAUTOMATIC1111を実行する環境は、ローカル環境(自宅のゲーミングPCなど)を使用するか、クラウドコンピューティングサービスを利用する2通りの方法があります。
以下の記事ではそれぞれの環境構築方法について詳し解説していますので、合わせてご覧ください。
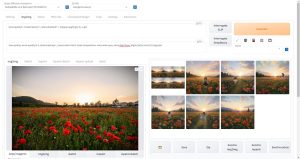

絵の構図、キャラクターのポーズをコントロールする
生成する画像のキャラクターのポーズや構図を自由にコントロールできる機能を紹介します。
この項目で紹介する機能を使うことで、自分の思い描いた構図やポーズを具現化することが可能となり、より細かい制御が可能になります。
OpenPoseでキャラクターのポーズを指定する
ControlNetで使用できるモデル、OpenPoseは生成する画像のキャラクターのポーズや構図を自由にコントロールできます。
以下の記事では、ControlNetのインストール方法、ポーズデータの作成方法、そして実際にControlNetを使って画像生成を行う方法について解説しています。
ユーザーは自分の思い描いた構図やポーズを具現化することが可能となります。

Depthライブラリで失敗した手を修正する
ControlNetとDepth map library and poser(深度ライブラリ)をインストールし、これらを組み合わせることで手の形状を自然な形に修正することが可能です。
以下の記事では、Depth map library and poserとControlNetのインストール方法、Depthデータの作成方法、そして実際にこれらを使って画像生成を行う方法について解説しています。
手の形状だけが不自然だった画像も修正して再利用することが可能となります。

reference_onlyでキャラクタを固定する
reference_onlyを使用すると、一枚の参照画像を用いて生成する画像のスタイルや特徴をより細かく制御することが可能になります。
これにより、追加学習を行うことなく、一枚の画像を読み込むだけで参照画像のキャラクターが再現可能となります。
また、気に入った絵のキャラクターに別のポーズを取らせたり、別の背景で画像を生成することができます。
この機能は、LoRAのデータセットを作成する手段としても有効で、手軽に試すことができます。

Latent Coupleで複数の人物を描く
Latent Coupleは、Stable Diffusionで生成する画像内の領域を複数に分割し、別々のプロンプトで指示を与えることができる機能です。
複数の人物を描きたい場合や、背景に関するプロンプトを分離したい場合などに活用できます。

イラストの補正
adetailerで顔や手の崩れを補正する
adetailerは、イラストの顔や手の部分を自動検出し、補正する機能です。
AIを用いた画像処理などをされている方にはおなじみのYoloなどの機械学習モデルを使用して、イラストの中の顔や手の位置を自動検出し、補正してくれます。
描画領域の小さいキャラクターでも顔の崩れなどを補正できますので、全身を写したイラストや背景メインの小さい人物の顔でも綺麗に生成することが可能でです。

アップスケーラ
MultiDiffusionで画像全体をアップスケールする
MultiDiffusionは、img2imgで画像生成する際にも使用できるアップスケーラで、元の画像の構図を保ったまま画像サイズを拡大、高精細化することができます。
具体的な使用例として、アニメ調画像の高精細化を解説していますが、フォトリアル系有効です。また、グラフィックボードのVRAM(ビデオカードメモリ)が少ない環境でも動作します。

Ultimate SD Upscalerで高速にアップスケールする
機能的にはAUTOMATIC1111 WebUI標準のhires.fixと同じものですが、画像の生成速度が圧倒的に速いアップスケーラです。
画像をいくつかの領域に分割し、並列処理を行うため短時間でアップスケールが完了します。(私の環境ではhires.fixの約4倍の速度でした)
また、画像のクオリティもhires.fixと比較して遜色ありませんので、hires.fixを多用する方には特におすすめです。

LLuLで画像の一部を高精細化する
LLuLは、画像の一部をLatentアップスケールすることで、指定した箇所のディティールを追加することが可能です。
以下の記事で、具体的な使用方法やインストール方法、そして実際の使用例について解説しています。画像の中のキャラクターの服装や背景だけを精細に描きたいといった場合に有効です。

tile_resample
ControlNetで使用できるプリプロセッサ、tile_resampleを使用することでイラストの書き込み量を大幅に増やすことが可能です。
書き込み量を増やす以外にも、画像サイズを拡大する際に元の絵柄を保持するという役割もありますので、大サイズの画像を生成したい場合に有効です。
他のアップスケーラーとの併用でも活用できます。

便利機能
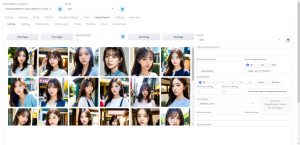
Image Browserで生成した画像の一覧表示する
Image Browserは、生成した画像をWebUI上で一覧表示し、確認することができる機能です。これにより、画像生成の作業効率が大幅に向上します。
過去に生成した画像を遡ってサムネイルで一覧表示できますので、大量に生成した画像の中からお気に入りの画像のSeed値やプロンプトを拾いたいといった場合に有効です。
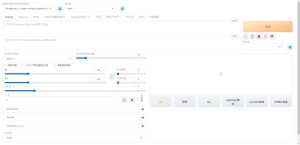
WebUIの表示を日本語化する
Stable Diffusion WebUIの操作画面は、デフォルトでは英語表記になっています。
特に初心者の方には、聞きなれない機能名が並んでいて操作を覚えるまでは大変かと思いますが、ja_JP Localizationという拡張機能をインストールすることで、操作画面の表示を日本語化することができます。
Stable Diffusionのテクニックを効率よく学ぶには?
 カピパラのエンジニア
カピパラのエンジニアStable Diffusionを使ってみたいけど、ネットで調べた情報を試してもうまくいかない…
 猫のエンジニア
猫のエンジニアそんな時は、操作方法の説明が動画で見られるUdemyがおすすめだよ!
動画学習プラットフォームUdemyでは、画像生成AIで高品質なイラストを生成する方法や、AIの内部で使われているアルゴリズムについて学べる講座が用意されています。
Udemyは講座単体で購入できるため安価で(セール時1500円くらいから購入できます)、PCが無くてもスマホでいつでもどこでも手軽に学習できます。
Stable Diffusionに特化して学ぶ
Stable Diffusionに特化し、クラウドコンピューティングサービスPaperspaceでの環境構築方法から、モデルのマージ方法、ControlNetを使った構図のコントロールなど、中級者以上のレベルを目指したい方に最適な講座です。
画像生成AIの仕組みを学ぶ
画像生成AIの仕組みについて学びたい方には、以下の講座がおすすめです。
画像生成AIで使用される変分オートエンコーダやGANのアーキテクチャを理解することで、よりクオリティの高いイラストを生成することができます。
まとめ
今回はStable DiffusionのWebUI、AUTOMATIC1111のおすすめ拡張機能を紹介しました。
それぞれの機能は、画像生成の作業をより効率的に、そしてより簡単に行うためのもので、Stable Diffusionを最大限に活用するためには欠かせないものばかりです。
ぜひ画像生成の際に活用してみてください。
また、以下の記事で効率的にPythonのプログラミングスキルを学べるプログラミングスクールの選び方について解説しています。最近ではほとんどのスクールがオンラインで授業を受けられるようになり、仕事をしながらでも自宅で自分のペースで学習できるようになりました。
スキルアップや副業にぜひ活用してみてください。

スクールではなく、自分でPythonを習得したい方には、いつでもどこでも学べる動画学習プラットフォームのUdemyがおすすめです。
講座単位で購入できるため、スクールに比べ非常に安価(セール時1200円程度~)に学ぶことができます。私も受講しているおすすめの講座を以下の記事でまとめていますので、ぜひ参考にしてみてください。

それでは、また次の記事でお会いしましょう。













コメント