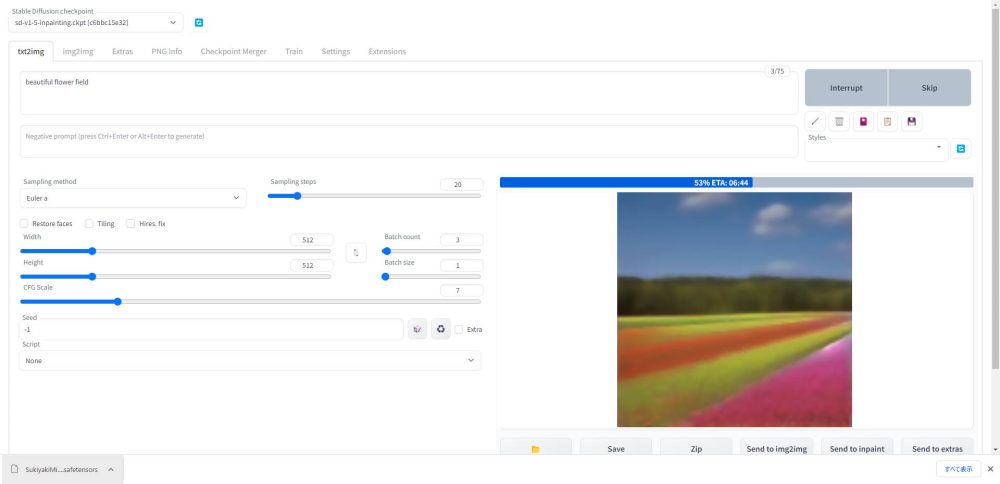
Stable Diffusionの高機能UIであるAUTOMATIC1111をローカル環境(自宅のゲーミングPCなど)に導入する方法を解説します。
AUTOMATIC1111を使用することで、プログラミングを一切必要とせずにStable Diffusionで画像生成を行うことができますので、ぜひ活用してみてください。
また、当ブログのStable Diffusionに関する記事を以下のページでまとめていますので、あわせてご覧ください。

Stable Diffusionとは
Stable Diffusion(ステーブル・ディフュージョン)は2022年8月に無償公開された描画AIです。ユーザーがテキストでキーワードを指定することで、それに応じた画像が自動生成される仕組みとなっています。
NVIDIAのGPUを搭載していれば、ユーザ自身でStable Diffusionをインストールし、ローカル環境で実行することも可能です。
(出典:wikipedia)
クラウドコンピューティングでStable Diffusionを使用する
本記事ではローカル環境のPCでAUTOMATIC1111を使用する方法について解説しますが、ゲーミングPCなど高性能なGPUを搭載したグラフィックボードが必要となります。
高性能なグラフィックボードを所有していない方向けには、クラウドコンピューティングサービスを使ってAUTOMATIC1111を使う方法も解説していますので、あわせてご覧ください。
Google Colaboratory
Googleのクラウドコンピューティングサービス、Google ColaboratoryでAUTOMATIC1111を使用する方法については、以下の記事で解説しています。

Paperspase
定額制で高性能GPUを利用できるクラウドコンピューティングサービス、PaperspaceでAUTOMATIC1111を使用する方法については、以下の記事で解説しています。



AUTOMATIC1111とは
AUTOMATIC1111はStable Diffusionをブラウザから利用するためのWebアプリケーションです。AUTOMATIC1111を使用することで、プログラミングを一切必要とせずにStable Diffusionで画像生成を行うことが可能になります。
AUTOMATIC1111の公式リポジトリは以下となります。


AUTOMATIC1111をインストールする準備
gitのインストール
gitは、分散型バージョン管理システムで、ソフトウェア開発やドキュメント管理など、さまざまなプロジェクトで使用されています。
今回、使用するAUTOMATIC1111はGit Hubで公開されているリポジトリを使用しますので、まずはgitをインストールします。(インストール済みの方は飛ばしてください)
インストール手順は以下のページで解説しています。
Dockerのインストール
Dockerは、コンテナ仮想化技術を利用してアプリケーションをパッケージ化し、移植性の高い環境を提供するオープンソースのプラットフォームです。
先ほどGitHubでダウンロードしたリポジトリはDockerのイメージとなっており、AUTOMATIC1111の環境が一式そろった状態で配布されていますので、ビルドを実行するだけですぐに使用できます。
AUTOMATIC1111のコンテナを実行するためDockerをインストールします。(インストール済みの方は飛ばしてください)インストール手順は以下のページで解説しています。

Dockerを使用せずにローカル環境を構築したい方向けには、以下のページで直接インストールする方法についても解説しています。


AUTOMATIC1111のインストール
ここからは実際にAUTOMATIC1111のインストール手順を解説します。
インストールから起動まで
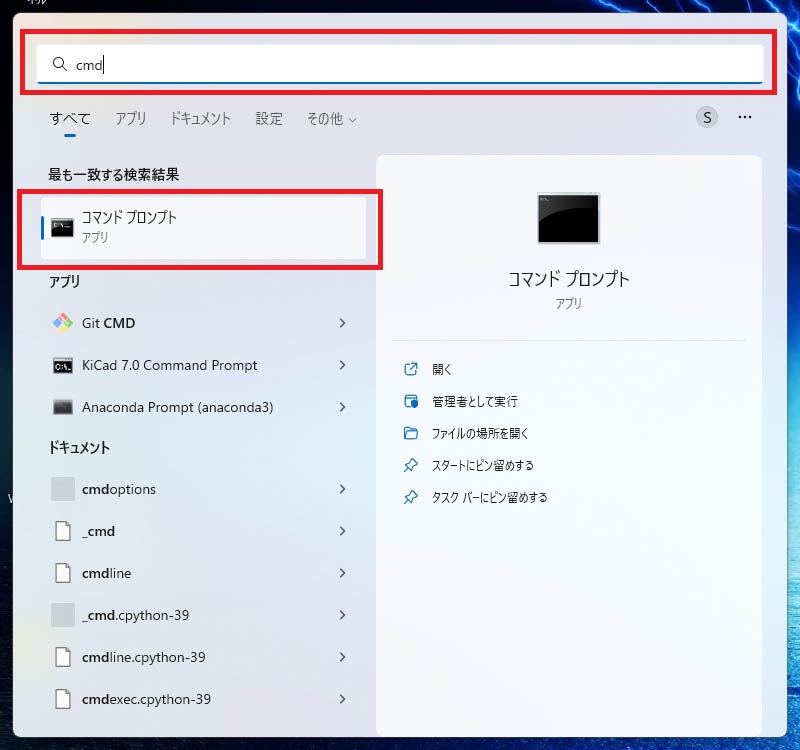
Windowsのコマンドプロンプトを起動します。Windowsのスタートメニューをクリックし、検索テキストボックスに「cmd」と入力します。
以下のように、検索結果に「コマンド プロンプト」が表示されますので、クリックして起動します。
コマンドプロンプトで以下のコマンドを実行してください。
cdコマンドでカレントディレクトリをAUTOMATIC1111をインストールしたいディレクトリに移動します。
cd (AUTOMATIC1111をインストールしたいディレクトリのパス)GitHubのAUTOMATIC1111のリポジトリをダウンロードします。
git clone https://github.com/AbdBarho/stable-diffusion-webui-docker.git
cd stable-diffusion-webui-dockerダウンロードしたイメージをビルドします。
ノートPCなどGPUを搭載していないマシン、またはGPUを使用したくない場合は「auto」→「auto-cpu」に変更して下さい。
docker compose --profile download up --build
docker compose --profile auto up --buildビルドにはかなり時間がかかりますので、気長に待ってください。
以下のように表示されたらビルド完了です。
この状態でAUTOMATIC1111がWebアプリケーションとして既に起動しています。
webui-docker-auto-cpu-1 | Running on local URL: http://0.0.0.0:7860
webui-docker-auto-cpu-1 |
webui-docker-auto-cpu-1 | To create a public link, set `share=True` in `launch()`.ブラウザを起動し、以下のアドレスにアクセスしてください。
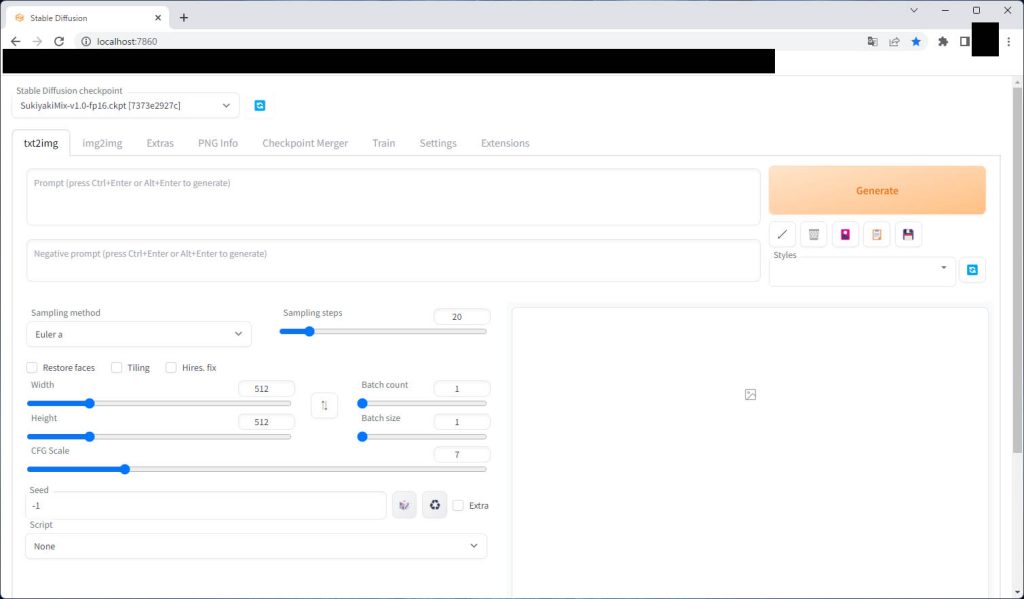
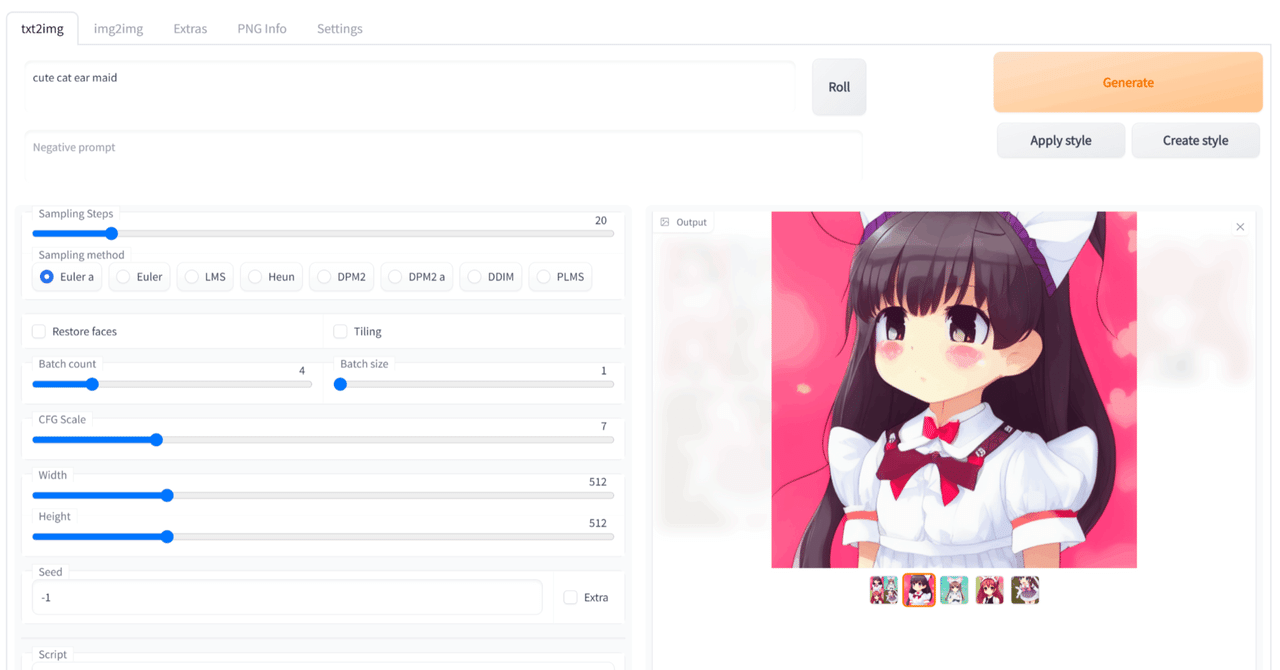
http://localhost:7860/ブラウザ上に以下のようなインタフェースが表示されていればセットアップ完了です。
これでStable Diffusionを使用する準備ができました。

2回目以降の起動方法
2回目以降の起動についてはDcokerのコンテナを起動するだけで使用できます。
WindowsのスタートメニューからDocker Desktopを起動します。
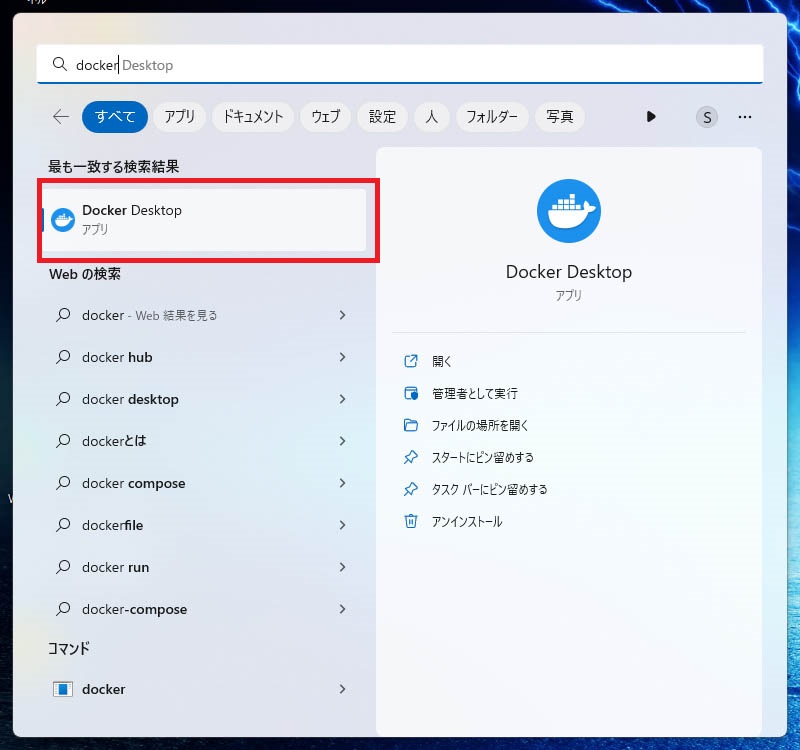
Dockerのデスクトップアプリが起動すると、コンテナの一覧画面が表示されます。
「webui-docker」という名前のコンテナがAUTOMATIC1111です。「Status」が「Exited」となっており、コンテナが停止した状態ですので、右側の「Actions」の実行ボタン(▶)をクリックしてコンテナを起動します。
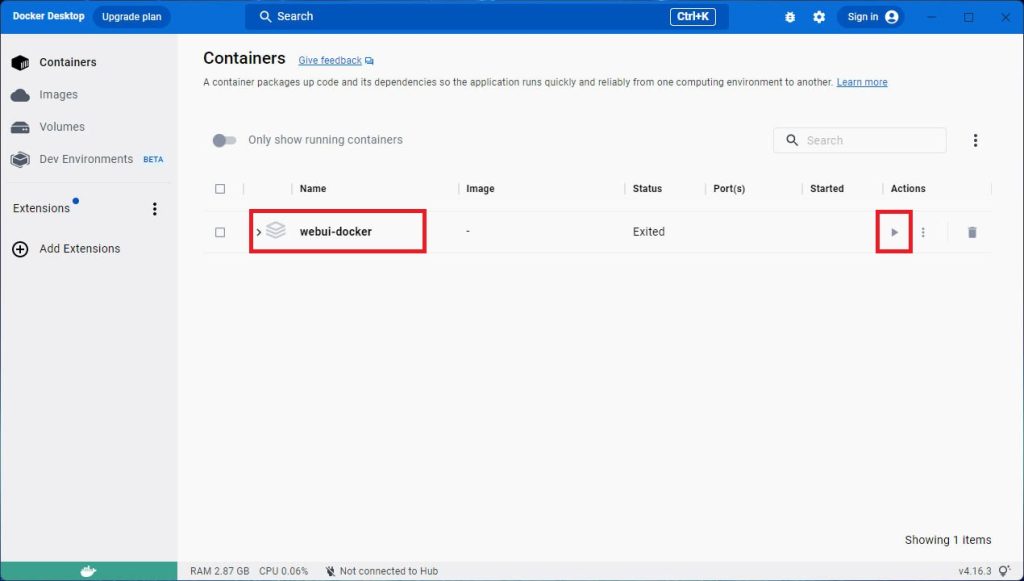
コンテナを起動すると、「Status」が「Running」に変わり、コンテナが起動した状態となります。これでAUTOMATIC1111にアクセスできる状態になりました。
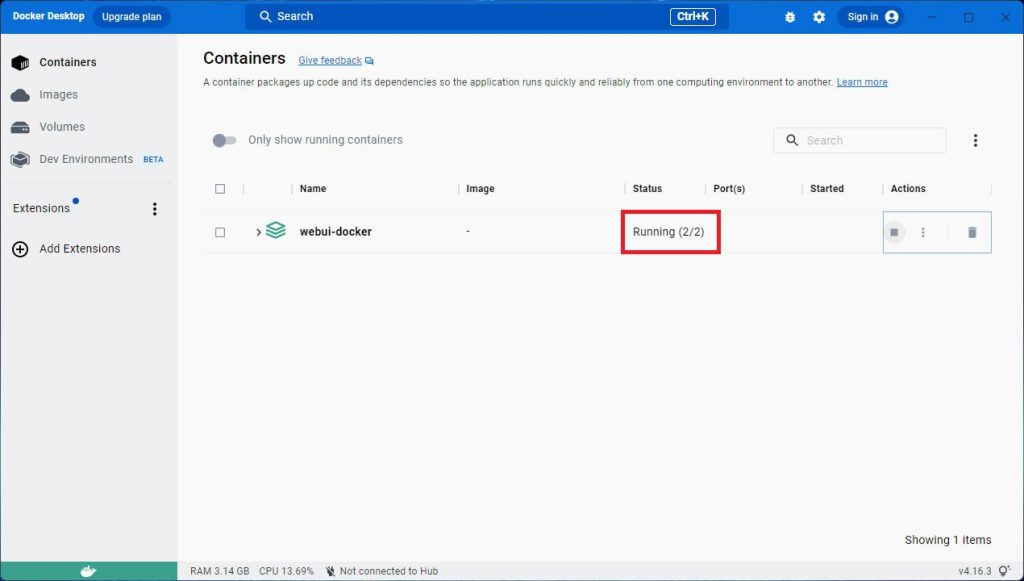
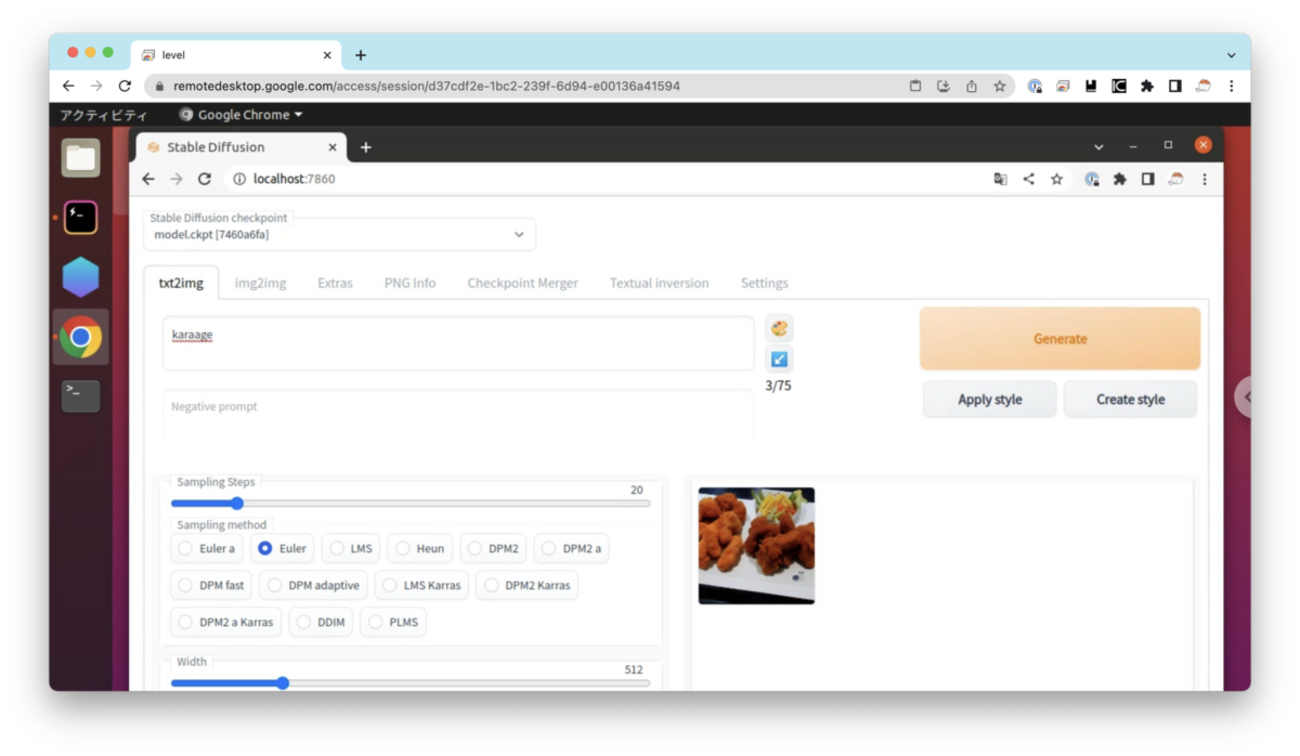
「http://localhost:7860/」にアクセスすると、AUTOMATIC1111のUIが表示されました。
Web UIのアップデート
WebUIは現在も日々開発が継続されており、アップデートにより新機能が提供されています。
WebUIの環境ごとのアップデート方法を、以下の記事で解説しています。

使用する学習済みモデルを指定する
Stable Diffusionでイラストを生成する際に最も重要なのが、使用する学習済みモデルです。使用するモデルがどのような画像を学習しているかによって、同じプロンプト(呪文)を指定しても出力される画像が大きく変わります。
AUTOMATIC1111では、使用するモデルをGUI上で簡単に切り替えることができます。
モデルの追加方法
モデルの入手方法については以下の記事で解説しています。欲しいモデルをダウンロードしてください。
モデルファイルが保存されているディレクトリは以下となります。
このディレクトリにダウンロードしたモデルファイルを入れるだけで、AUTOMATIC1111の画面から選択できるようになります。
モデルの切り替え
今回はAUTOMATIC1111で最初から用意されている、Stable Diffusionの標準モデルを使用して画像を生成してみます。
画面左上の「Stable Diffusion checkpoint」で選択されているのが、画像生成で使用されるモデルです。ドロップダウンリストをクリックすることで、使用するモデルを切り替えることができます。
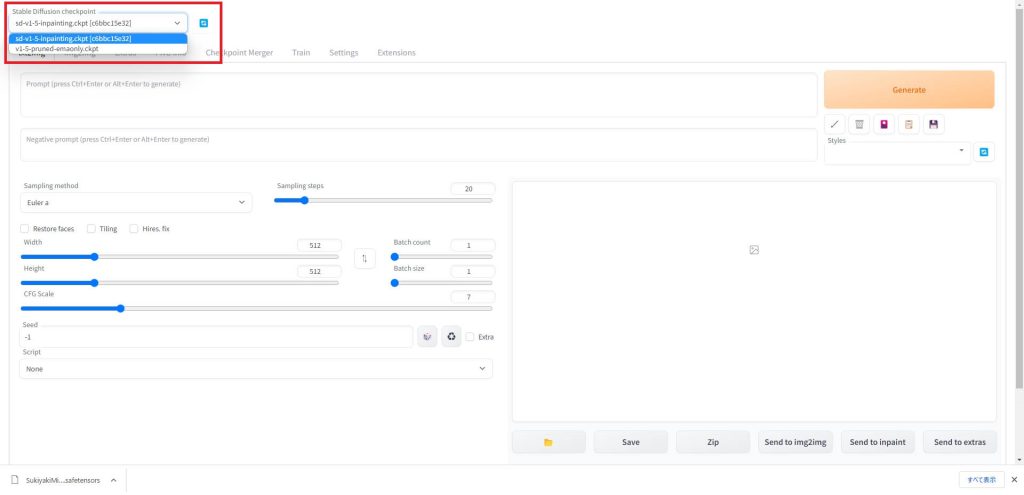
リストからモデルを選択したら、モデルの切り替えは完了です。
また、私が使用しているおすすめのモデルについても以下の記事で紹介していますので、あわせてご覧ください。
Stability AI公式
Stable Diffusionの開発元であるStability AI公式モデルです。
2023年7月にリリースされたモデルSDXL1.0の使い方を、以下の記事で解説しています。

Stable Diffusion 2.1の使い方を、以下の記事で解説しています。

アニメ調モデル
アニメ調に特化したモデルを、以下の記事で解説しています。

リアル系モデル
フォトリアル系に特化したモデルを、以下の記事で解説しています。

VAE(Auto-Encoder)を変更する
VAE(Variational Autoencoder、変分自己符号化器)は、データの次元圧縮や生成、および特徴抽出に利用される深層学習の手法の一つです。
イラストを生成する際、各モデルごとに推奨されているVAEに変更することで、イラストのクオリティを大幅に向上させることができます。(モデル配布サイトの解説に記載されています)
VAEを変更したい場合は、設定方法を以下の記事で解説しています。


パラメータを設定する
使用する学習済みモデルを選択したら、プロンプトとパラメータを入力していきます。
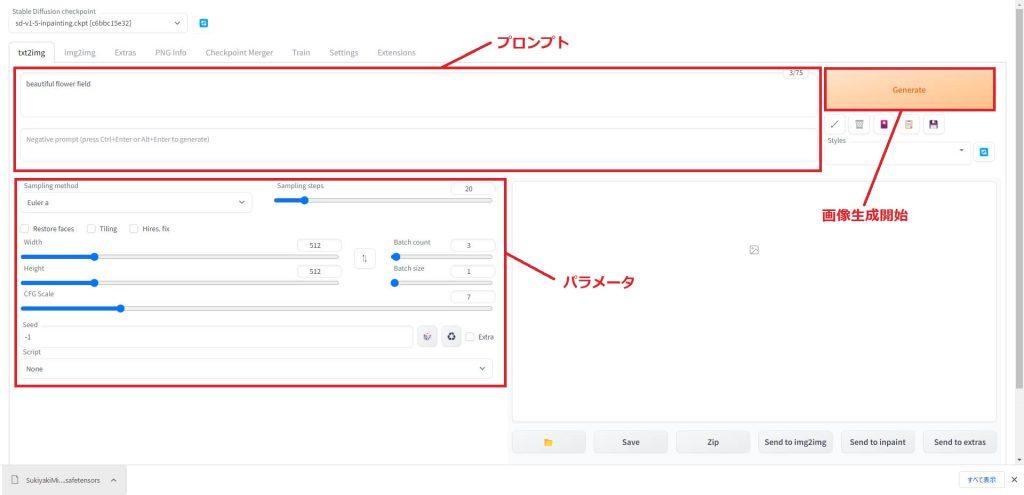
効果的なプロンプトの作成例を以下の記事で解説していますので、あわせてご覧ください。
アニメ調プロンプト

フォトリアル系プロンプト

パラメータ
Stable Diffusionのパラメータが画像にどのように影響するかについては、以下の記事で詳細を解説しています。

こちらの記事のパラメータの解説を見ながら、とりあえずはSampling method(サンプラー)、Sampling steps(ステップ数)、Batch count(生成枚数)、CFG Scale(スケール)、Seed(シード)の5つのパラメータだけを入力すればOKです。
Seedは「-1」が入力されると毎回ランダムな値で生成されます。
パラメータとプロンプトを入力し終わったら、画面右上の「Generate」ボタンをクリックすると画像生成が始まります。
プロンプトの作成が難しいと思われている方には、AIでプロンプトを自動生成するのがおすすめです。「StableDiffusionのプロンプト(呪文)を自然言語処理モデルGPT-3(Catchy)で自動生成する方法」で詳細を解説しています。
イラストを生成する
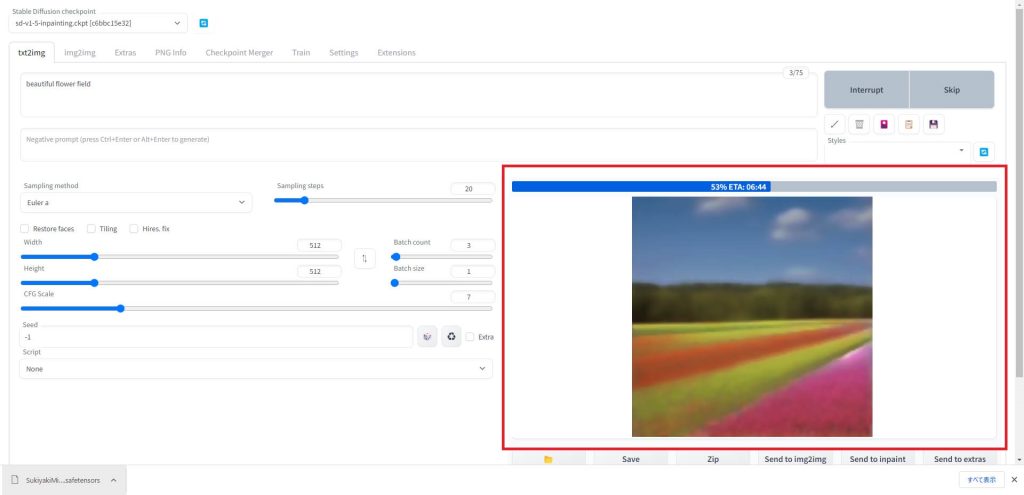
画像生成が始まると右側のウィンドウに生成中の画像と、プログレスバーに進行度が表示されます。
進行度が100%になると画像生成が完了します。
生成が完了すると、画像の一覧が表示されます。今回は3枚の画像を生成してみました。
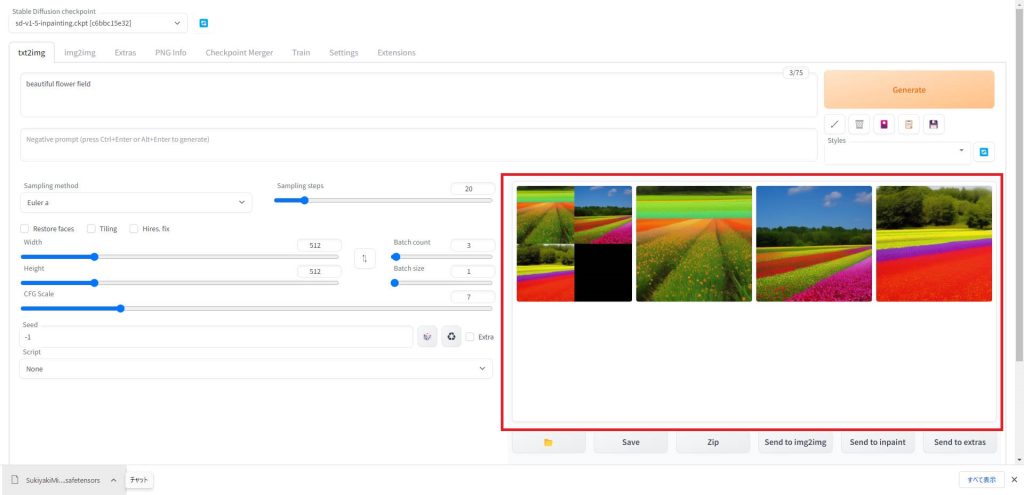
画像を保存したい場合は、画像が表示されている部分の下にある「Save」ボタンをクリックします。
現在、表示されている画像のダウンロードリンクが表示されますので、クリックします。
ウィンドウ左下に画像がダウンロードされましたので、任意のディレクトリに保存してください。
イラストを高精細化する
パラメータでStepsの値を大きくすると、高精細な画像が生成できますが、その分生成に時間がかかってしまいます。
そのため、まず最初はStepsの数値を低め(私の場合は10~20)くらいにして、大量に画像を生成し、好きな構図やキャラクターが出てくるまで回します。
Seed値を固定して再生成する
お気に入りの画像が生成されたら、右の画像ウィンドウで画像を選択します。
すると下の画面の赤枠の部分にSeed値が表示されます。
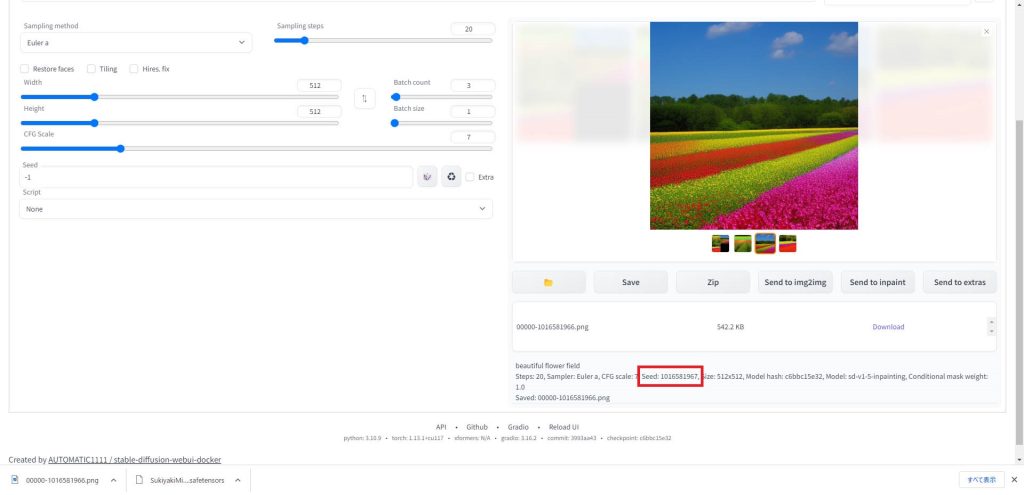
気に入った絵のSeed値をコピーし、左下のSeed入力欄に貼り付けます。これで絵の構図やキャラクターをある程度固定して画像を生成することができます。
Seedを入力したら、今度はStepsの値を高い値(最大150)に変更して、1枚だけ画像を生成します。(Seed値が固定されているため、2枚以上生成しても同じ絵が出てきます)
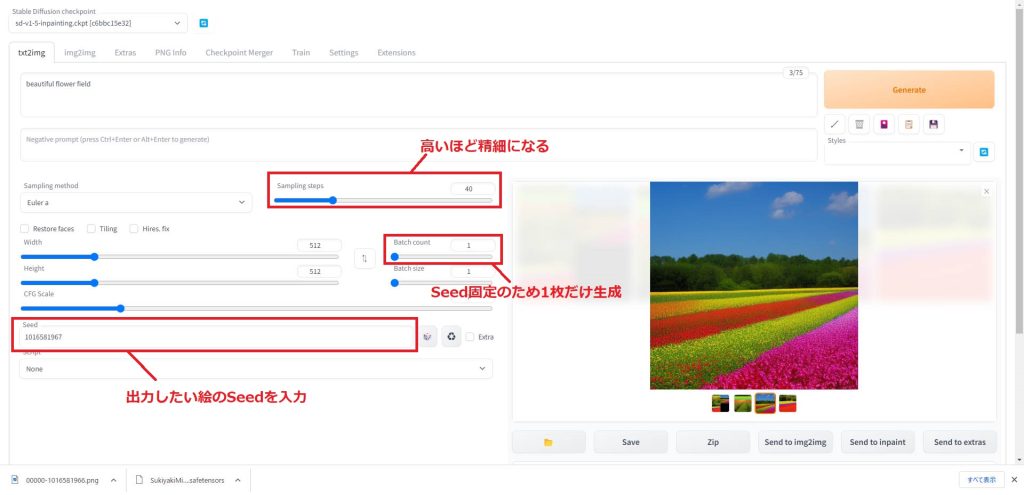
Generateをクリックすると、高精細な画像が生成されました。
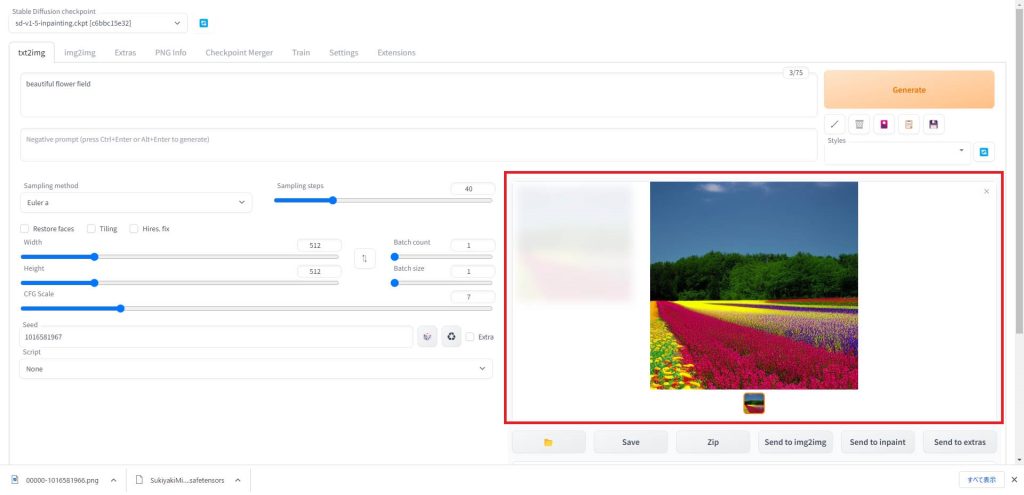
以上のような手順を踏むことで、効率よく理想的な画像を生成することができます。
画像比較
同じプロンプト、Seed値でStepsだけを変更して生成した画像を比較してみました。
Steps-20
1枚目はStepsを20に設定して生成した画像です。

Steps-40
2枚目はStepsを40に設定して生成した画像です。

Stepsの値を高く設定した方が、1本1本の花や木の葉が精細に描画されていることが確認できました。
img2imgで高精細化する
もう1つの高精細化の手段として、img2imgを使う方法があります。img2imgはプロンプト+画像で指示を与える方法となりますので、低いSteps値で回してお気に入りの画像が生成されたら、それをimg2imgに送って高Steps、大サイズで再生成することで、高精細化できます。
具体的な手順は以下の記事で解説しています。
アップスケーラーで高精細化する
AUTOMATIC1111 WebUIでは、様々なアップスケーラーが公開されており、これらを活用して高解像度化とディティールを精細化することが可能です。
アップスケーラーの種類と使い方については、以下の記事で解説しています。

応用編:AUTOMATIC1111の拡張機能を活用する
ここからは、応用編としてAUTOMATIC1111の拡張機能を使った画像生成のテクニックを紹介します。拡張機能を使用することで、より画像生成の自由度が向上します。
構図やキャラクターのポーズを指定して生成する
これまで解説してきた手順で、プロンプトから画像を生成できるようになりました。しかし、プロンプトだけでは、どのようなポーズのキャラクターが出力されるかはガチャ的な要素であり、かなり試行回数を踏まなければ理想的なイラストは出力できません。
そこで、AUTOMATIC1111の拡張機能でControlNetというツールを使用することで、イラストの構図やキャラクターのポーズを指定して生成できるようになります。
ControlNetを使った生成方法は以下のページで解説しています。

AUTOMATIC1111の拡張機能として使用できるOpenPose Editorがリリースされ、AUTOMATIC1111のUI内でポーズデータの作成から画像生成までを一貫して実行できるようになりました。
失敗した手の描写を修正する
せっかく気に入ったイラストが生成されたのに「手の部分の形状がおかしい」、「指の本数が多すぎるなど」手の描写は画像AIで人物を描く際の大きな失敗要因の1つです。
そんな時、Depthライブラリの拡張機能を使用することで、手の部分だけを綺麗に修正することができます。Depthライブラリの使い方は以下の記事で解説しています。

画像をアップスケールして高精細化する
画像全体をアップスケールする
画像全体をアップスケールしたい場合は、AUTOMATIC1111に標準搭載されているhires.fixという機能を使うことで実現することができます。
hires.fixの使い方は以下の記事で解説しています。

画像の一部だけにディティールを追加する
LLuL – Local Latent upscaLerという拡張機能を使用することで、生成した画像の一部だけにディティールを追加して高精細化することができます。
LLuL – Local Latent upscaLerのインストールと使用方法を以下の記事で解説しています。

マージモデルを作成する
AUTOMATIC1111のCheckpoint Mergerという機能を使用すると、自分でマージモデルを作成することができます。好きなモデルを組み合わせ、合成比率を設定するだけで簡単に新たなモデルを作成できます。
マージモデルを作成する方法については、以下の記事で解説しています。

LoRAでキャラクターを固定して画像を生成する
追加学習LoRAを使用することにより、キャラクターを固定して画像を生成することができます。AUTOMATIC1111でLoRAファイルを使用する方法を以下の記事で解説しています。

Stable Diffusionのテクニックを効率よく学ぶには?
 カピパラのエンジニア
カピパラのエンジニアStable Diffusionを使ってみたいけど、ネットで調べた情報を試してもうまくいかない…
 猫のエンジニア
猫のエンジニアそんな時は、操作方法の説明が動画で見られるUdemyがおすすめだよ!
動画学習プラットフォームUdemyでは、画像生成AIで高品質なイラストを生成する方法や、AIの内部で使われているアルゴリズムについて学べる講座が用意されています。
Udemyは講座単体で購入できるため安価で(セール時1500円くらいから購入できます)、PCが無くてもスマホでいつでもどこでも手軽に学習できます。
Stable Diffusionに特化して学ぶ
Stable Diffusionに特化し、クラウドコンピューティングサービスPaperspaceでの環境構築方法から、モデルのマージ方法、ControlNetを使った構図のコントロールなど、中級者以上のレベルを目指したい方に最適な講座です。
画像生成AIの仕組みを学ぶ
画像生成AIの仕組みについて学びたい方には、以下の講座がおすすめです。
画像生成AIで使用される変分オートエンコーダやGANのアーキテクチャを理解することで、よりクオリティの高いイラストを生成することができます。
まとめ
Stable Diffusionの高機能UI、AUTOMATIC1111のセットアップと画像の生成方法について解説しました。Pythonのコードで実装すると大変なモデルの切り替えなども簡単に行うことができますので、活用してみてください。
当ブログのStable Diffusionに関する記事を以下のページでまとめていますので、あわせてご覧ください。
また、以下の記事で効率的にPythonのプログラミングスキルを学べるプログラミングスクールの選び方について解説しています。最近ではほとんどのスクールがオンラインで授業を受けられるようになり、仕事をしながらでも自宅で自分のペースで学習できるようになりました。
スキルアップや副業にぜひ活用してみてください。

スクールではなく、自分でPythonを習得したい方には、いつでもどこでも学べる動画学習プラットフォームのUdemyがおすすめです。
講座単位で購入できるため、スクールに比べ非常に安価(セール時1200円程度~)に学ぶことができます。私も受講しているおすすめの講座を以下の記事でまとめていますので、ぜひ参考にしてみてください。

それでは、また次の記事でお会いしましょう。



参考










コメント