
 猫のサラリーマン
猫のサラリーマン最近、Stable Diffusionっていう画像系AIが話題だよね
使ってみたいけど、どうすればいいんだろう?
 猫のエンジニア
猫のエンジニアStable Diffusionはオープンソースだから、自分でPythonのコードをダウンロードして自宅のPCやGoogle Colabで使えるんだよ。
画像を描画できるAI、Stable Diffusionについて、当ブログでも過去に何度か取り上げてきました。
今回はStable Diffusionのインストールから拡張機能の使い方まで、それらの使用方法についてまとめたいと思います。
- Stable Diffusionの概要
- Stable Diffusionの導入方法
- Stable Diffusionの拡張機能の使い方
- Stable Diffusionで使えるモデルとプロンプト(呪文)
Stable Diffusionとは
Stable Diffusion(ステーブル・ディフュージョン)は2022年8月に無償公開された描画AIです。ユーザーがテキストでキーワードを指定することで、それに応じた画像が自動生成される仕組みとなっています。
GPUを搭載していれば、ユーザ自身でStable Diffusionをインストールしローカル環境で実行することも可能です。
(出典:wikipedia)


高機能WebUI AUTOMATIC1111
Stable Diffusionの主要機能をほとんど網羅している超高機能Web UI、AUTOMATIC1111。
Pythonなどプログラミングを一切必要とせず、GUIからモデルの変更やパラメータ設定など、Steble Diffusionの機能を使用できます。
猫のエンジニアStable Diffusionを始めるなら、まずはAUTOMATIC1111のインストールからだね。
AUTOMATIC1111のインストール
WebUI AUTOMATIC1111は主にローカルPC、Paperspace、Google Colaboratoryなどの環境で使用することができます。
 カピパラのエンジニア
カピパラのエンジニア自宅に高性能なPCが無くても、クラウドコンピューティングサービスを利用すればStable Diffusionが使えるよ。
各環境でのインストール方法を以下の記事で解説しています。
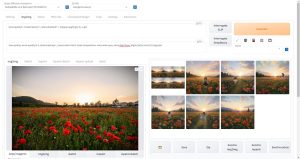
ControlNet Stable Diffusionの拡張機能
AUTOMATIC1111で使用できるStable Diffusionの代表的な拡張機能にControlNetがあります。
Stable Diffusionの推論の前段に別のニューラルネットワークを組み合わせることにより、生成される画像を細かくコントロールすることができます。
- 人間のポーズの指定: ControlNetを使用して特定の人間のポーズを生成できます。
- 他の画像からの構図のコピー: 既存の画像から構図をコピーして新しい画像を生成することができます。
- 類似画像の生成: 既存の画像に似た新しい画像を生成することができます。
- ラフな下書きをプロフェッショナルな画像に変換: ラフな下書きを高品質な画像に変換することができます。
- プリプロセッサとモデルの選択: OpenPose, CannyDepth, Line Artなど、多数のプリプロセッサとモデルから選択できます。
猫のエンジニアControlNetを導入することで、絵のクオリティが劇的に向上するよ。
ControlNetの各機能の使い方について、以下の記事で詳しく解説していきます。

ControlNet以外の拡張機能
ControlNet以外にも、AUTOMATIC1111には様々な拡張機能がリリースされています。
生成した画像のブラウジングや、WebUIの日本語化など、便利な機能を以下の記事で解説しています。

画像をアップスケールして高精細化する
Web上で公開されている有名なAI絵師さんの超高精細の画像をよく見かけると思います。
そういったAI絵師さんの画像は、一度生成した画像をアップスケーラを使って高解像度化したり、ディティールアップ(書き込み量を増やす)していることが多いです。
以下はtile_resampleというアップスケーラを使用した例です。

全く同じモデル、プロンプトを使って生成した画像ですが、アップスケール前後で劇的に書き込み量が増えているのが確認できます。
カピパラのエンジニア書き込み量の違いは一目瞭然だね!
以下の記事でおすすめのアップスケーラを紹介しています。

追加学習LoRA(Low-Rank Adaptation)
LoRAとは、Stable Diffusionの学習済みモデルを追加学習させることにより局所的にチューニングを行う仕組みです。
- 新しいコンセプトの追加: LoRAは既存のStable Diffusionモデルに新しいコンセプトを追加することができます。これには、特定の人物や服装、絵のタッチなどが含まれます。
- 効率的なファインチューニング: LoRAは大規模な言語モデルや画像生成モデルを効率的にファインチューニングするために開発されました。
- ハードウェア要件が低い: LoRAは小さいファイルサイズであり、ハードウェア要件が低いため、短時間で訓練することができます。
- プロンプトでの使用: LoRAはプロンプトに特定のテキスト(トリガーワード)を追加することで、出力に影響を与えることができます。
- 複数のLoRAの組み合わせ: 一つのプロンプトで複数のLoRAを使用することができます。
猫のエンジニアLoRAを使うことで、キャラクターの顔や服装を固定して生成することができるよ。
また、LoRAは自分で環境構築して追加学習を行わなくても、他のユーザーが学習させたLoRAファイルをCivitaiなどのモデル共有サイトからダウンロードすることで、すぐにその効果を使用できます。
追加学習の手順や、AUTOMATIC1111のWebUIでLoRAファイルを使用する方法を以下の記事で解説しています。

マージモデルを作成する
AUTOMATIC1111のCheckpoint Mergerを使うと、お気に入りのモデルを組み合わせてマージモデルを作成することが可能です。
Checkpoint Mergerの使用方法を以下の記事で解説しています。

Stable Diffusionで使用できるモデル
Stable Diffusionでは、アニメ系、フォトリアル系など様々なモデルが日々作成され、公開されています。
どのモデルを使うかによって、同じプロンプト(呪文)パラメータを使用しても、生成される画像は大きく変わります。
Stable Diffusionで使用できるおすすめのモデルを、以下の記事でジャンルごとに紹介しています。

Stable Diffusionで使用できるプロンプト(呪文)
Stable Diffusionでどのような画像を生成するかを指示する文章をプロンプト、または呪文と呼びます。
このプロンプトをどのように使うかによって、生成される画像のクオリティが大きく変わります。また、アニメ系、フォトリアル系などのジャンルによってもキーワードが大きく異なります。
生成したい画像に近づけるためのプロンプト作成テクニックを以下の記事で解説しています。

自然言語モデル(LLM)によるプロンプト生成
英文の呪文を一から考えるのは大変ですが、自然言語モデルを使ったAIに日本語で作成したい画像のイメージを伝えると、それを元に呪文を自動生成することが可能です。
OpenAIの自然言語モデルGPT-3を生成AIのプロンプト用にチューニングされたモデルを使った生成方法を以下で解説しています。

Catchyを使って生成したプロンプトのサンプル集を以下の記事で紹介しています。

Stable Diffusionのテクニックを効率よく学ぶには?
カピパラのエンジニアStable Diffusionを使ってみたいけど、ネットで調べた情報を試してもうまくいかない…
猫のエンジニアそんな時は、操作方法の説明が動画で見られるUdemyがおすすめだよ!
動画学習プラットフォームUdemyでは、画像生成AIで高品質なイラストを生成する方法や、AIの内部で使われているアルゴリズムについて学べる講座が用意されています。
Udemyは講座単体で購入できるため安価で(セール時1500円くらいから購入できます)、PCが無くてもスマホでいつでもどこでも手軽に学習できます。
Stable Diffusionに特化して学ぶ
Stable Diffusionに特化し、クラウドコンピューティングサービスPaperspaceでの環境構築方法から、モデルのマージ方法、ControlNetを使った構図のコントロールなど、中級者以上のレベルを目指したい方に最適な講座です。
画像生成AIの仕組みを学ぶ
画像生成AIの仕組みについて学びたい方には、以下の講座がおすすめです。
画像生成AIで使用される変分オートエンコーダやGANのアーキテクチャを理解することで、よりクオリティの高いイラストを生成することができます。
まとめ
今回はStable Diffusionの使用方法についてまとめてみました。
現在、公式新モデルであるSDXL2.0も公開されており、今後もモデルの進化が楽しみです。
また、Stable Diffusionのテクニックをさらに向上させたい方には、スマホの動画で学べるUdemyの講座を紹介していますので、あわせてご覧ください。

それでは、また次の記事でお会いしましょう。













コメント