
 カピパラのエンジニア
カピパラのエンジニアグラボのVRAMが少ないから、サイズの小さい画像しか生成できないのがつらい…
 猫のエンジニア
猫のエンジニア小さいサイズだとキャラの顔が崩れちゃうんだよね
今回はこんな時に便利なStable DiffusionのWebUI、AUTOMATIC1111の拡張機能として使えるMultiDiffusionを紹介します。
MultiDiffusionはimg2imgで画像生成する際にも使用できるアップスケーラで、元の画像の構図やタッチを保ったまま画像サイズを拡大、高精細化することができます。
MultiDiffusionは、VRAM容量が少ない環境でも高品質な画像を生成できるように工夫されています。
特に、分割してアップスケールする機能や、VRAM使用量を抑えるための設定が用意されています。
これにより、低スペックのマシンでも手軽に高品質な画像生成を行うことが可能です。
img2imgで元の構図を維持したまま高精細化が可能。
今回はアニメ調画像を例に解説しますが、アップスケーラの種類を変更することでフォトリアル系の画像にも使えますので、ぜひ活用してみてください。
- MultiDiffusionの概要
- MultiDiffusionのインストール方法
- MultiDiffusionの使用方法とその効果
また、当ブログのStable Diffusionに関する記事を以下のページでまとめていますので、あわせてご覧ください。

Stable Diffusionの導入方法から応用テクニックまでを動画を使って習得する方法についても以下のページで紹介しています。

Stable Diffusionとは
Stable Diffusion(ステーブル・ディフュージョン)は2022年8月に無償公開された描画AIです。ユーザーがテキストでキーワードを指定することで、それに応じた画像が自動生成される仕組みとなっています。
NVIDIAのGPUを搭載していれば、ユーザ自身でStable Diffusionをインストールし、ローカル環境で実行することも可能です。
(出典:wikipedia)
Stable DiffusionのWeb UI AUTOMATIC1111
AUTOMATIC1111はStable Diffusionをブラウザから利用するためのWebアプリケーションです。
AUTOMATIC1111を使用することで、プログラミングを一切必要とせずにStable Diffusionで画像生成を行うことが可能になります。
Web UI AUTOMATIC1111のインストール方法
Web UIであるAUTOMATIC1111を実行する環境は、ローカル環境(自宅のゲーミングPCなど)を使用するか、クラウドコンピューティングサービスを利用する2通りの方法があります。
以下の記事ではそれぞれの環境構築方法について詳し解説していますので、合わせてご覧ください。
img2img(Image-to-Image Translation)とは
Stable Diffusionのimg2img(Image-to-Image)機能は、入力画像とテキストプロンプトに基づいて新しいAI画像を生成する手法です。
この機能の特徴として、出力画像は入力画像の色と構図を維持します。
背景と人物の位置関係など、文章では指示が難しい構図に対する指示も画像で簡単に指示できる。
入力画像は詳細である必要はなく、重要なのは色と構図ですので、紙に簡単に描いた落書きのような絵をスマホで撮影し、それを元に精細なイラストを生成するといった使い方も可能です。
- 簡単なスケッチから高品質な画像を生成: img2imgは、簡単な手書きのスケッチのようなラフな画像を高品質なイラストに変換することができます。
- 色と構図の維持: 出力画像は、入力画像の色と構図を維持するため、元の画像に忠実に画像を生成できます。複雑なプロンプトを書かずに詳細な指示が可能です。
- ユーザーフレンドリーなUI: AUTOMATIC1111 GUIを使用すると、参照させたい画像をWebUI上にドラッグ&ドロップするだけで指示が完了します。
img2imgについては以下の記事で詳細を解説しています。

MultiDiffusionとは
MultiDiffusionはimg2imgモデルの拡張版で、高解像度の画像を高速に生成する機能です。
MultiDiffusionは、大きな画像を小さな領域に分割し、それぞれを個別に処理してから再度結合するタイル状のVAEを採用しています。
各タイルは独立して処理されるため、計算リソースを効率的に使用でき、全体としての処理速度が向上します。また、各タイルでの処理が独立しているため、並列処理が可能です。
このアプローチにより、少ないVRAMのグラフィックボードでも高解像度の画像生成が可能で、かつ推論処理を高速に実行できます。
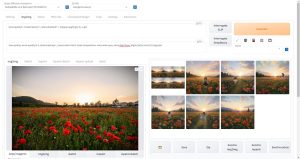
以下の画像はNVIDIA Quadro P4000というVRAM8GBのグラフィックボードを使用してMultiDiffusionで生成しました。解像度は1152×1152です。

Stable Diffusionで使用するグラフィックボードのVRAMは最低でも12GB程度以上推奨と言われていますが、MultiDiffusionではVRAM8GBでもこのように充分なサイズの画像を生成することができます。
MultiDiffusionのインストール
AUTOMATIC1111のWebUIにMultiDiffusionをインストールする手順を解説します。
AUTOMATIC1111のWebUIを起動したら、Extensionsタブをクリックします。
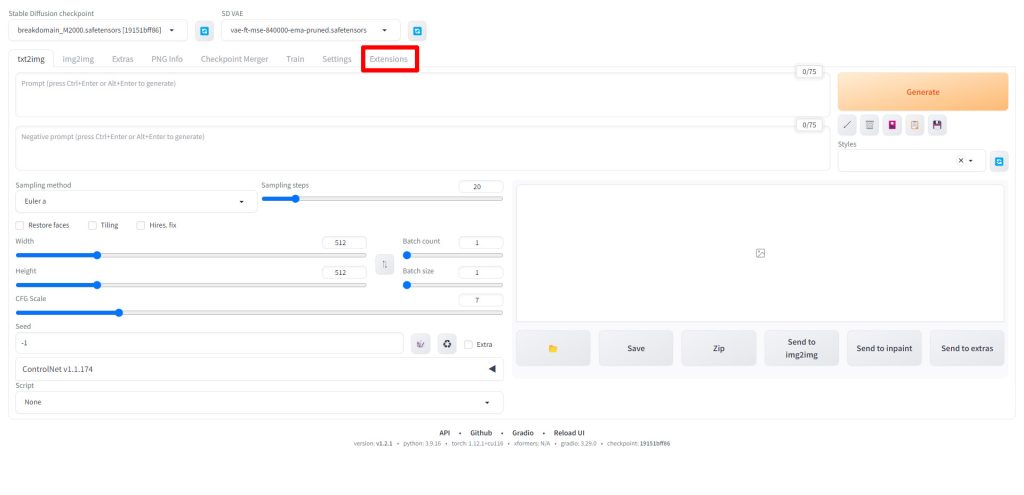
Install from URLタブをクリックします。
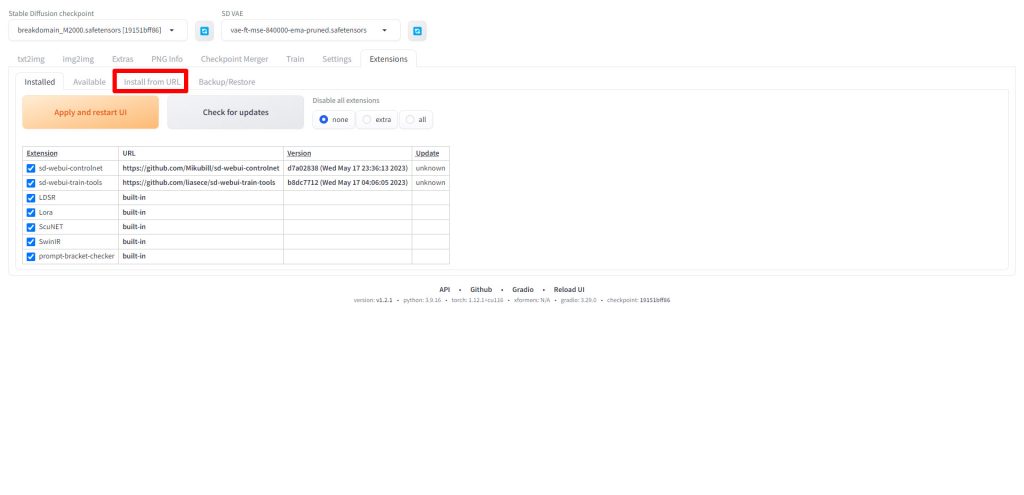
URL for extension's git repositoryに以下のURLを入力してください。
https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111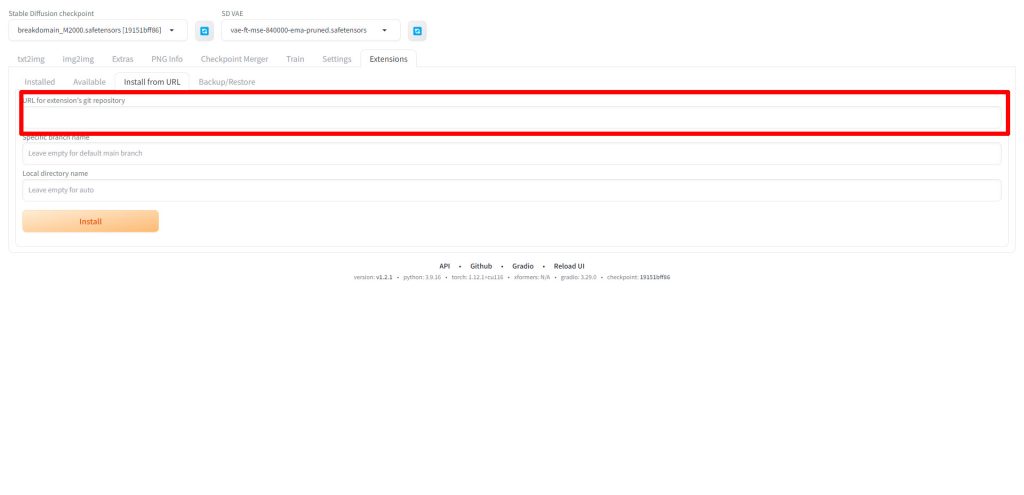
URLを入力したらInstallをクリックします。
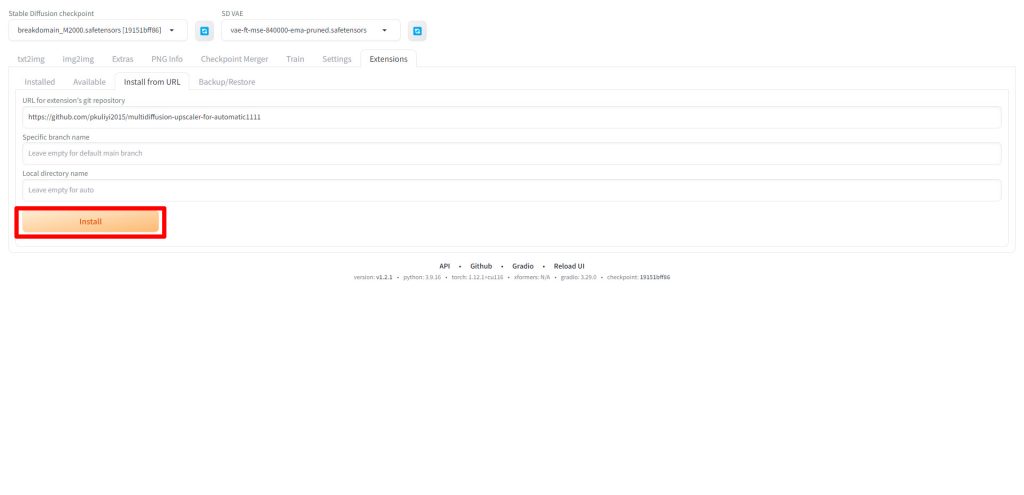
以下のようにメッセージが表示されたらインストールが完了です。


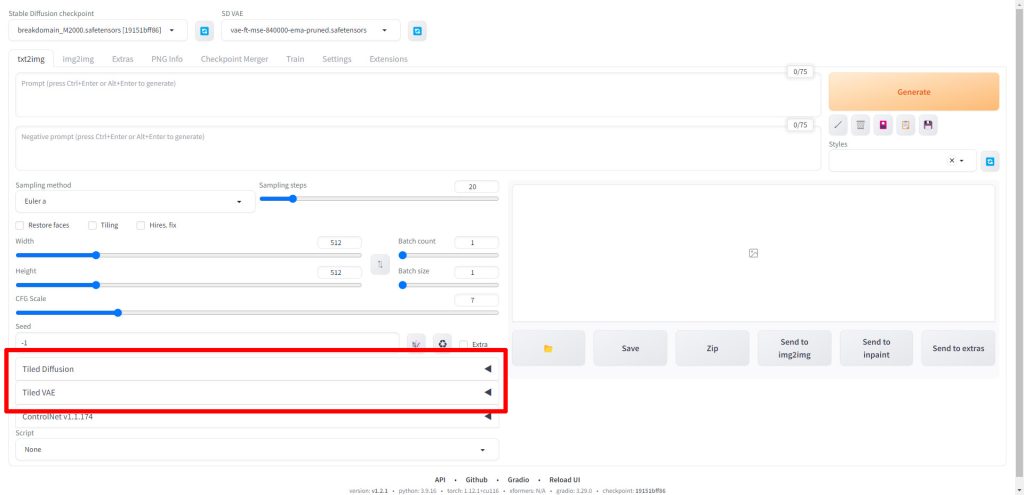
MultiDiffusionを使ってアップスケール(高画質)する
MultiDiffusionをインストール後、WebUIを再起動すると以下のようにTiled DiffusionとTiled VAEの項目が追加されています。
今回はimg2imgでのアップスケールを試しますので、まずはtxt2imgで画像を生成します。
プロンプトの作成が難しいと思われている方には、AIでプロンプトを自動生成するのがおすすめです。「StableDiffusionのプロンプト(呪文)を自然言語処理モデルGPT-3(Catchy)で自動生成する方法」で詳細を解説しています。
プロンプトとパラメータを入力したら、Generateをクリックして画像を生成します。
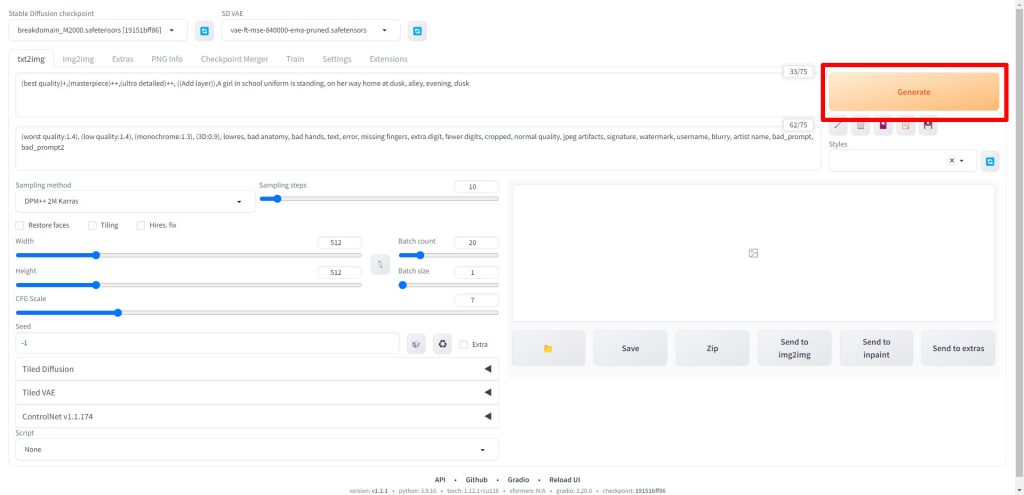
画像生成が完了したら、気に入った画像を選択し、Send to img2imgをクリックします。
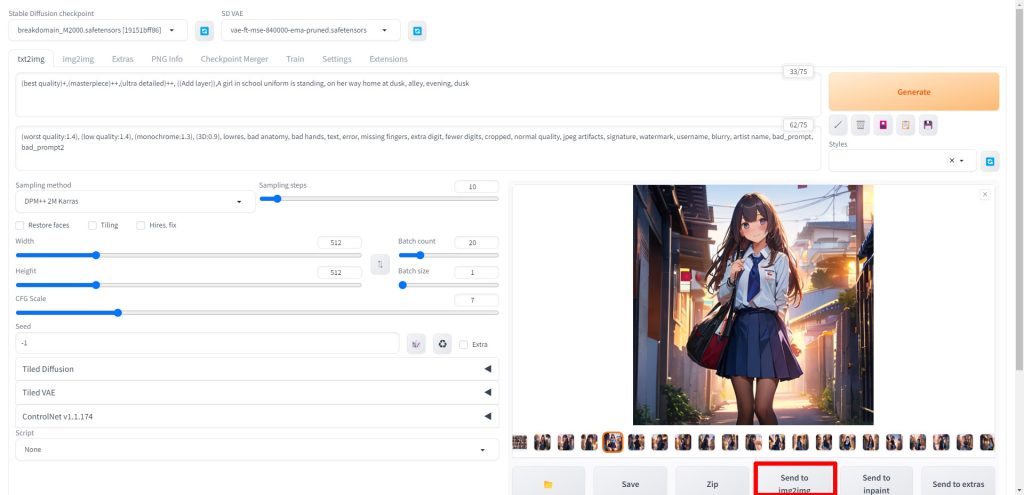
img2imgの画面に先ほどの画像が転送されたら、画面を下にスクロールします。
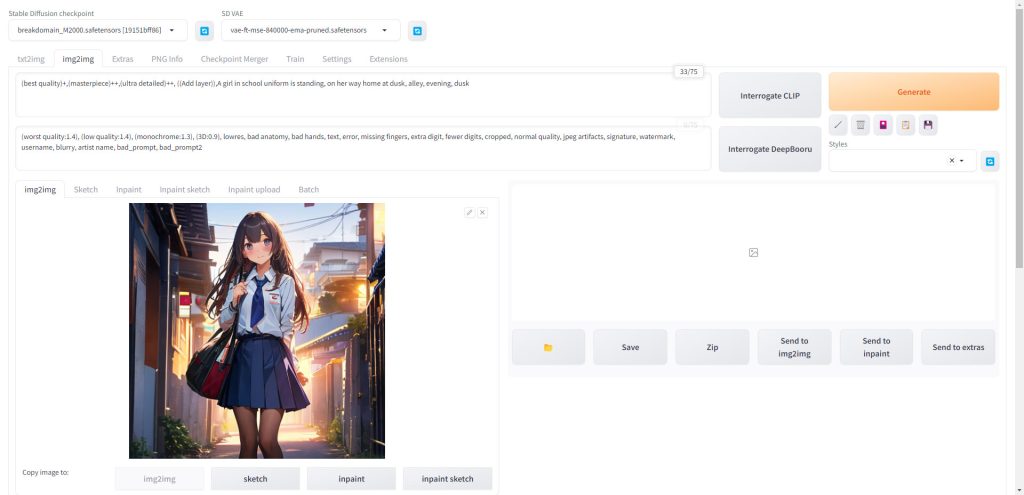
まずは通常通りSampling methodを選択します。今回はimg2imgの元画像と同様にDPM++ 2M Karrasを選択します。
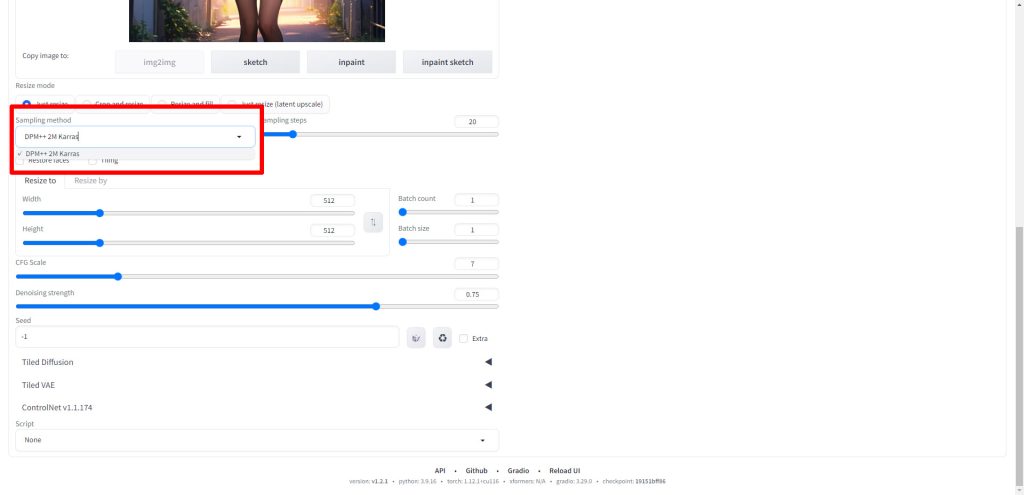
続いてSampling stepsを設定します。今回は30に設定しました。
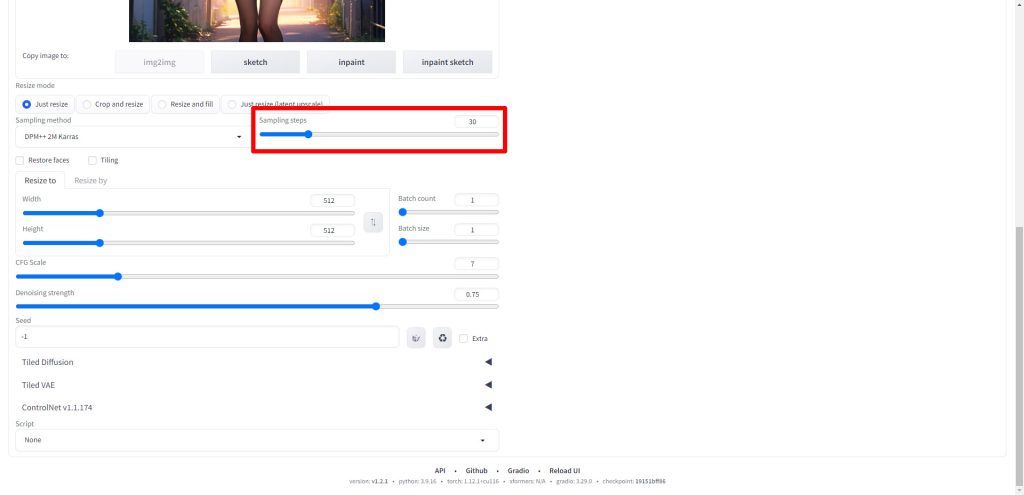
Tiled Diffusionの項目をクリックします。
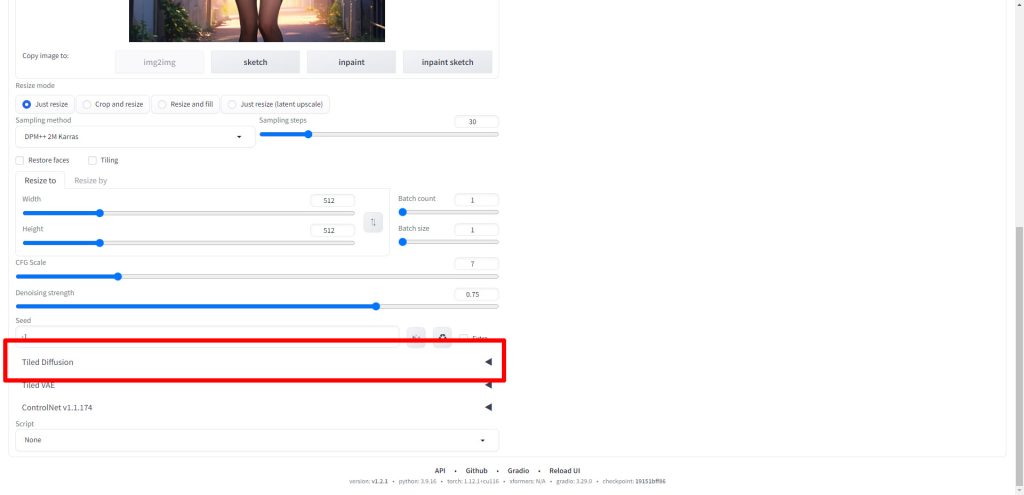
以下のようにMultiDiffusionの設定項目が展開されます。
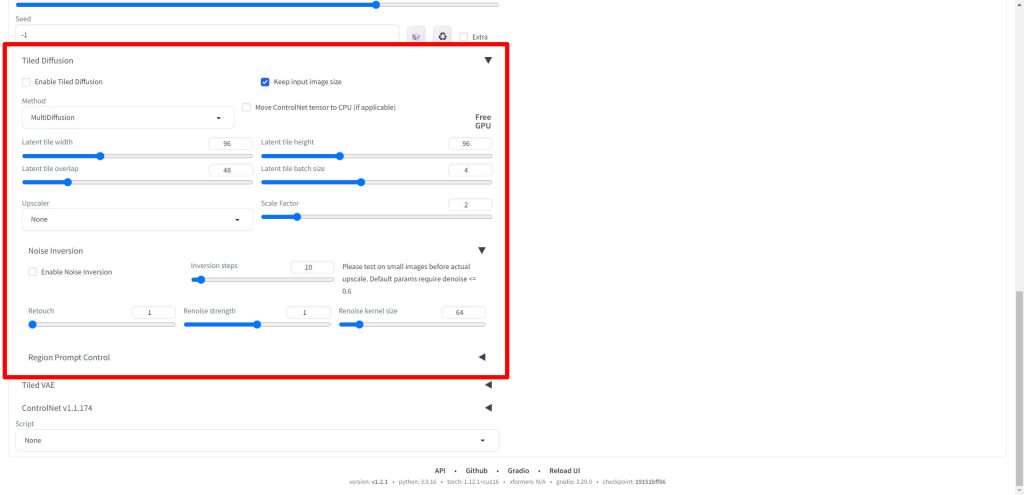
Enable Tiled DiffusionとKeep input image sizeにチェックを入れます。
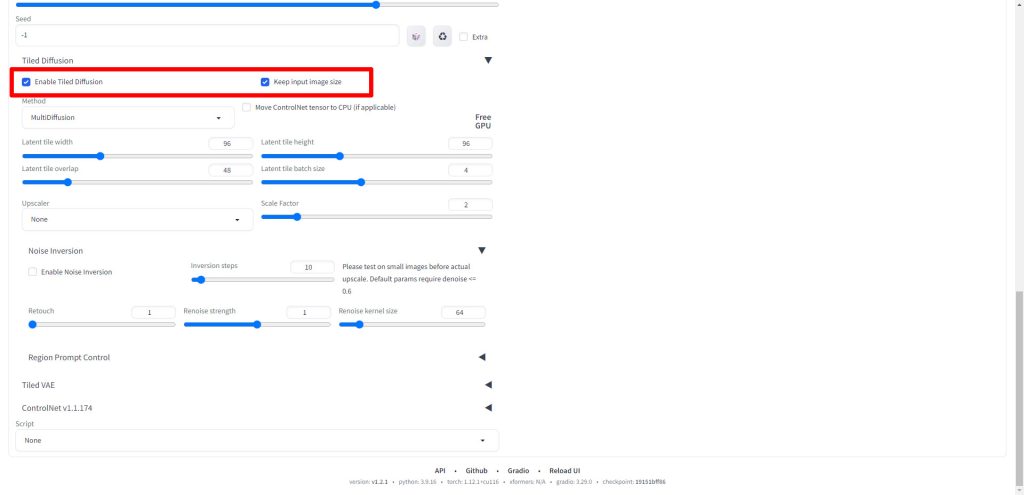
MethodはデフォルトのMultiDiffusionのままに設定します。
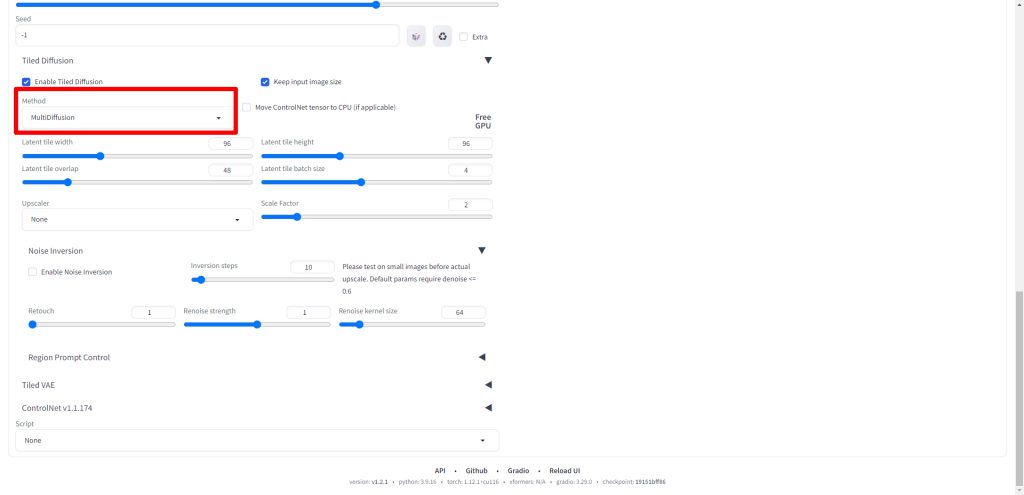
Upscalerは今回はR-ESRGAN 4x+ Anime6Bを選択しました。フォトリアル系ではR-ESRGAN 4x+など必要に応じて変更してください。
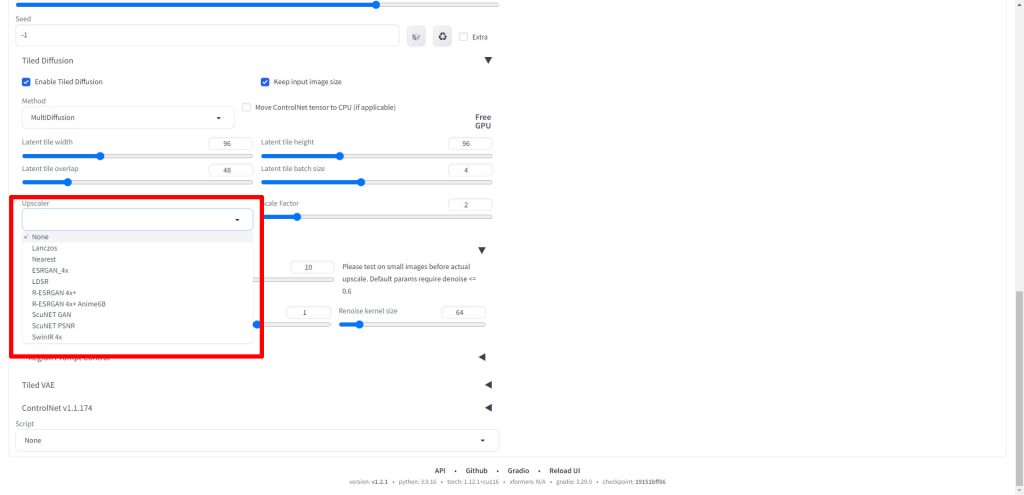
Scale Factorは元の入力画像に対して、何倍に拡張するかを設定する項目になります。今回は元画像が512*512のサイズであるため、2に設定しました。
出力画像は2倍の1024*1024となります。
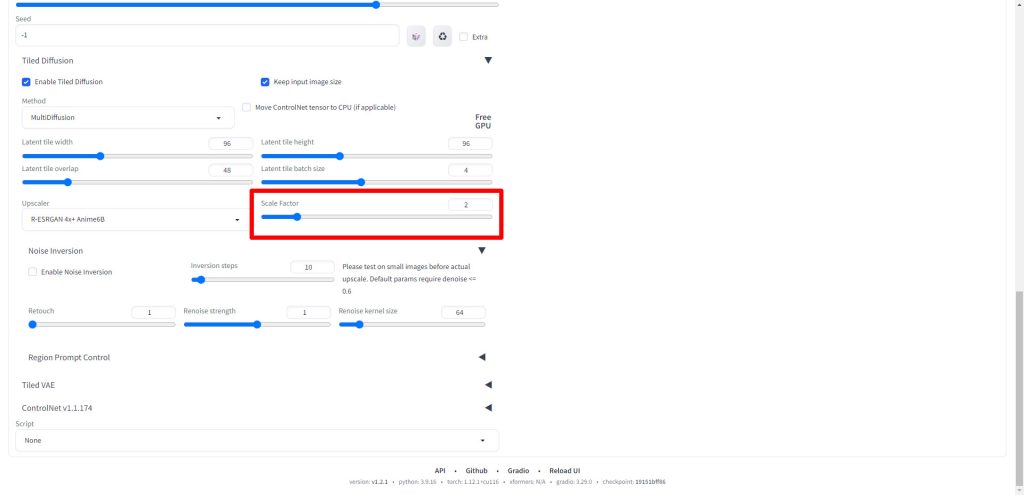
それ以外の項目は今回はデフォルト値のままとしました。
設定が完了したら、Generateをクリックして画像を生成します。
以下のようにMultiDiffusionによってアップスケールされた画像が生成されました。
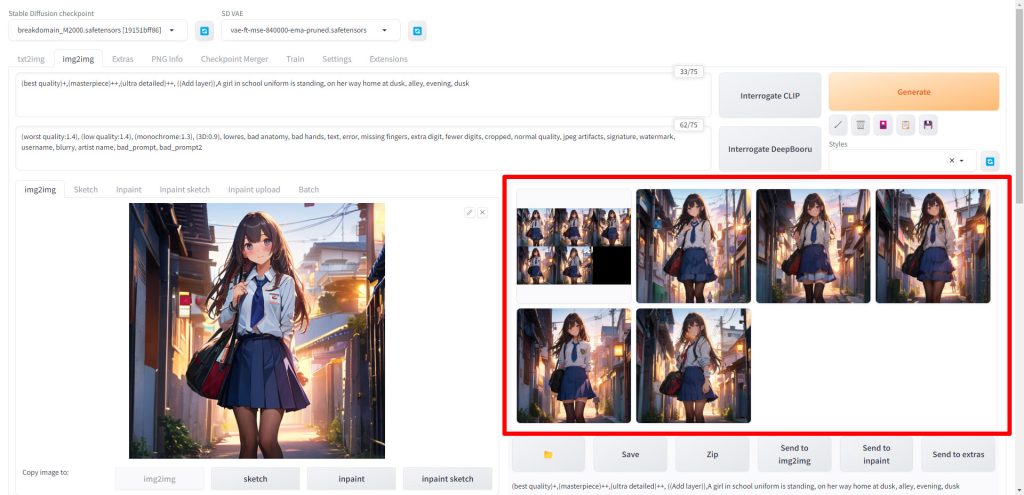
img2imgで画像生成時のMultiDiffusionアップスケール実行結果
j実際にMultiDiffusionを使ったアップスケール前後の画像を比較してみます。
アップスケール前の画像
アップスケール前の画像は512*512のサイズの画像です。
プロンプト
(best quality)+,(masterpiece)++,(ultra detailed)++, ((Add layer)),A girl in school uniform is standing, on her way home at dusk, alley, evening, duskネガティブプロンプト
(worst quality:1.4), (low quality:1.4), (monochrome:1.3), (3D:0.9), lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist name, bad_prompt, bad_prompt2モデル
今回、画像生成に使用したモデルはBreakDomain_m2000です。
モデルの入手先は以下のページで解説しています。

生成された画像

MultiDiffusionでアップスケール後の画像
こちらがMultiDiffusionでアップスケールした画像です。
画像サイズが大きくなっただけでなく、書き込み量も増えて高精細な画像になりました。

Stable Diffusionのテクニックを効率よく学ぶには?
カピパラのエンジニアStable Diffusionを使ってみたいけど、ネットで調べた情報を試してもうまくいかない…
猫のエンジニアそんな時は、操作方法の説明が動画で見られるUdemyがおすすめだよ!
動画学習プラットフォームUdemyでは、画像生成AIで高品質なイラストを生成する方法や、AIの内部で使われているアルゴリズムについて学べる講座が用意されています。
Udemyは講座単体で購入できるため安価で(セール時1500円くらいから購入できます)、PCが無くてもスマホでいつでもどこでも手軽に学習できます。
Stable Diffusionに特化して学ぶ
Stable Diffusionに特化し、クラウドコンピューティングサービスPaperspaceでの環境構築方法から、モデルのマージ方法、ControlNetを使った構図のコントロールなど、中級者以上のレベルを目指したい方に最適な講座です。
画像生成AIの仕組みを学ぶ
画像生成AIの仕組みについて学びたい方には、以下の講座がおすすめです。
画像生成AIで使用される変分オートエンコーダやGANのアーキテクチャを理解することで、よりクオリティの高いイラストを生成することができます。
まとめ
今回はStable DiffusionのWebUI、AUTOMATIC1111の拡張機能として使えるMultiDiffusionを紹介しました。
AUTOMATIC1111では、今回紹介したMultiDiffusion以外にもアップスケールする拡張機能が用意されています。


用途に応じた拡張機能を選択してみてください。
また、以下の記事で効率的にPythonのプログラミングスキルを学べるプログラミングスクールの選び方について解説しています。最近ではほとんどのスクールがオンラインで授業を受けられるようになり、仕事をしながらでも自宅で自分のペースで学習できるようになりました。
スキルアップや副業にぜひ活用してみてください。

スクールではなく、自分でPythonを習得したい方には、いつでもどこでも学べる動画学習プラットフォームのUdemyがおすすめです。
講座単位で購入できるため、スクールに比べ非常に安価(セール時1200円程度~)に学ぶことができます。私も受講しているおすすめの講座を以下の記事でまとめていますので、ぜひ参考にしてみてください。

それでは、また次の記事でお会いしましょう。













コメント