
今回はStable DiffusionでLoRAの追加学習を行う際に使用できるデータセットと、パラメータ設定による学習結果の違いについて解説します。
LoRAで追加学習を行うためには、学習させたいキャラクターや衣装が描かれている画像を少なくとも20枚程度用意する必要があります。
しかし、一般に公開されているアニメのキャラクターや芸能人の画像などは著作権の問題から使用することができないため、学習用のデータセットを用意するのに苦労します。
そこで、まずLoRAで学習する手順をマスターしたいと思っている方に最適なデータセットを紹介します。
今回、紹介するSSS合同会社が公開している東北ずん子というキャラクターは非商用であれば無料で利用でき、LoRA追加学習用にキャプションファイルまでセットで公開されています。

東北ずん子のキャラクターは非商用では無料で使用でき、LoRA学習用のキャプションファイルを含むデータが用意されている。
LoRA初心者の方でも、データセットの作成に苦労することなくすぐに試すことができますので、ぜひ活用してみてください。
また、当ブログのStable Diffusionに関する記事を以下のページでまとめていますので、あわせてご覧ください。

Stable Diffusionの導入方法から応用テクニックまでを動画を使って習得する方法についても以下のページで紹介しています。

Stable Diffusionとは
Stable Diffusion(ステーブル・ディフュージョン)は2022年8月に無償公開された描画AIです。ユーザーがテキストでキーワードを指定することで、それに応じた画像が自動生成される仕組みとなっています。
NVIDIAのGPUを搭載していれば、ユーザ自身でStable Diffusionをインストールし、ローカル環境で実行することも可能です。
(出典:wikipedia)
Stable DiffusionのWeb UI AUTOMATIC1111
AUTOMATIC1111はStable Diffusionをブラウザから利用するためのWebアプリケーションです。
AUTOMATIC1111を使用することで、プログラミングを一切必要とせずにStable Diffusionで画像生成を行うことが可能になります。
Web UI AUTOMATIC1111のインストール方法
Web UIであるAUTOMATIC1111を実行する環境は、ローカル環境(自宅のゲーミングPCなど)を使用するか、クラウドコンピューティングサービスを利用する2通りの方法があります。
以下の記事ではそれぞれの環境構築方法について詳し解説していますので、合わせてご覧ください。
LoRA(Low-Rank Adaptation)とは
LoRA(Low-Rank Adaptation)は、既存のStable Diffusionモデルを20枚程度の画像を用いて追加学習させることにより微調整することができる仕組みです。LoRAを用いることにより、キャラクターや服装などの特徴を固定して画像生成することが可能になります。
LoRAの詳細については以下の記事で解説していますので、あわせてご覧ください。


LoRAで追加学習を行うツール sd-scripts
LoRAで追加学習を行うためにはsd-scriptsというツールが必要となります。
ツールの導入方法について、以下の記事で解説しています。

sd-scriptsを使って追加学習を行う手順
追加学習を行い、LoRAファイルを作成する手順を、以下の記事で解説しています。



東北ずん子とは
東北ずん子は、東北企業が無償で商用利用できるキャラクターです。
声優の佐藤聡美さんが声を担当しており、17歳の高校生という設定です。趣味はずんだ餅作りやずんだ餡を利用した創作料理作りで、そのキャラクター性が反映されています。
このキャラクターは、東北企業であれば無料で商用利用が可能で、クリエイターは非商用であれば無料で利用できます。そのため、東北地方の自治体や公共団体でも、イベントやふるさと納税、広報などの目的で利用されています。
また、東北ずん子関連の公式グッズは、公式ウェブサイトのショップで取り扱われています。3Dモデルや音声素材なども提供されており、これらも商用利用が可能です。
公式サイトは以下となります。

東北ずん子のデータセットを入手する方法
先ほど紹介した東北ずん子の公式サイトにアクセスします。
以下のトップページが表示されますので、下方向にスクロールします。

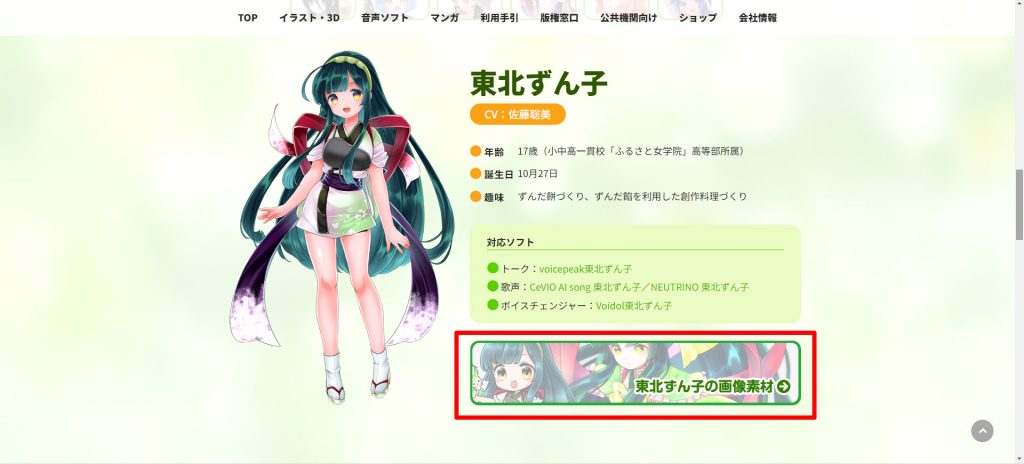
東北ずん子のプロフィールが表示されたら、東北ずん子の画像素材をクリックします。
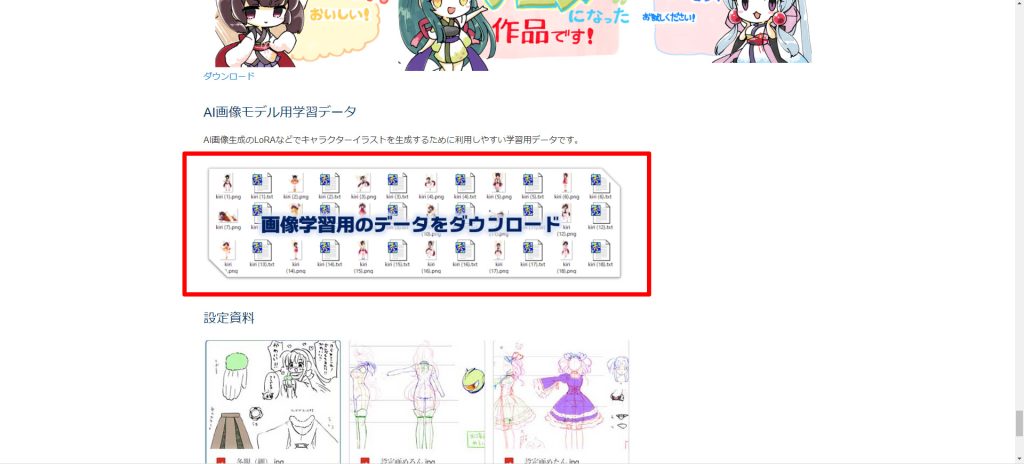
素材ページが開いたら、下方向にスクロールします。画像学習用のデータをダウンロードをクリックします。
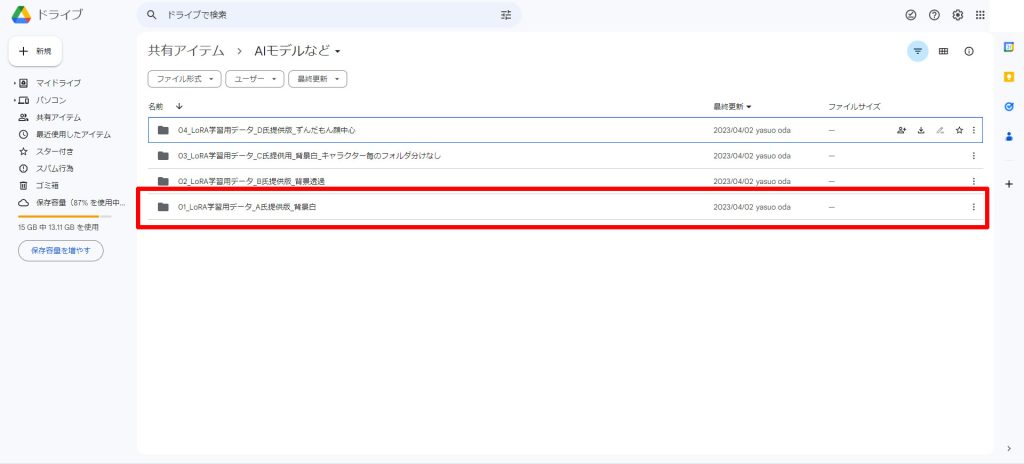
Google Driveが開きますので、01_LoRA学習用データA氏提供版背景白を右クリックします。
メニューのダウンロードをクリックします。
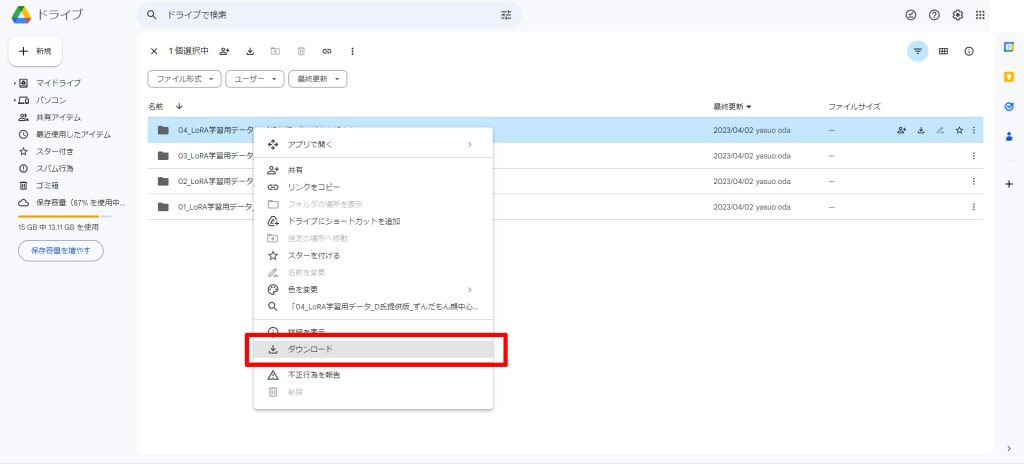
東北ずん子のデータセット
先ほどダウンロードしたファイルを解凍すると以下のようなファイルが展開されます。
以下のように61枚の画像ファイルに連番で名前が付けられており、そのままLoRAで学習することができる状態になっています。
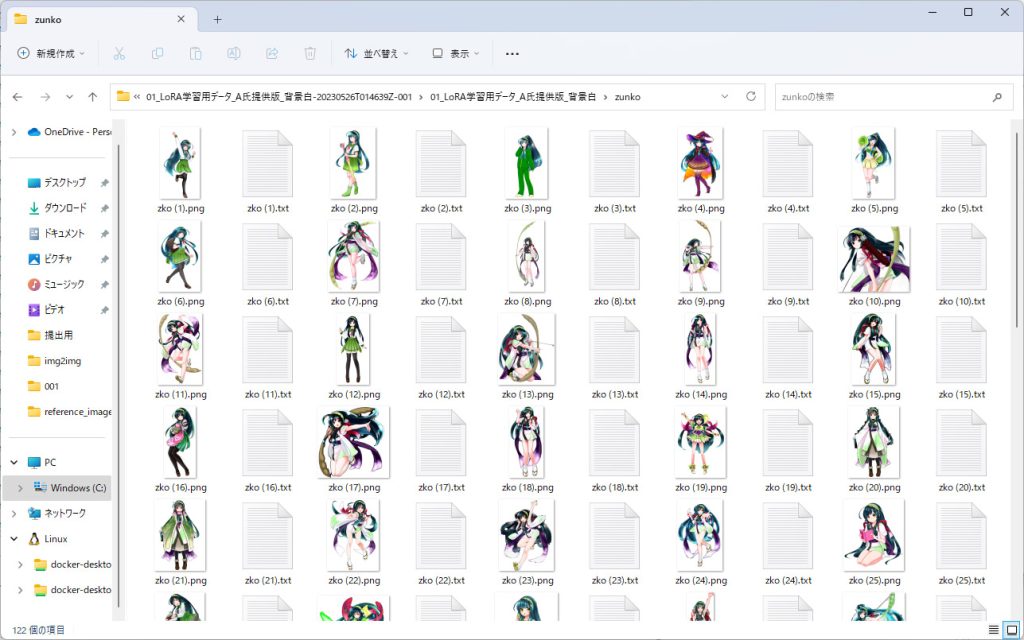
また、画像とセットでLoRAの学習時に必要となるキャプションファイルまで用意されています。
例として1枚目の画像と対になるキャプションファイルzko (1).txtを開いてみます。
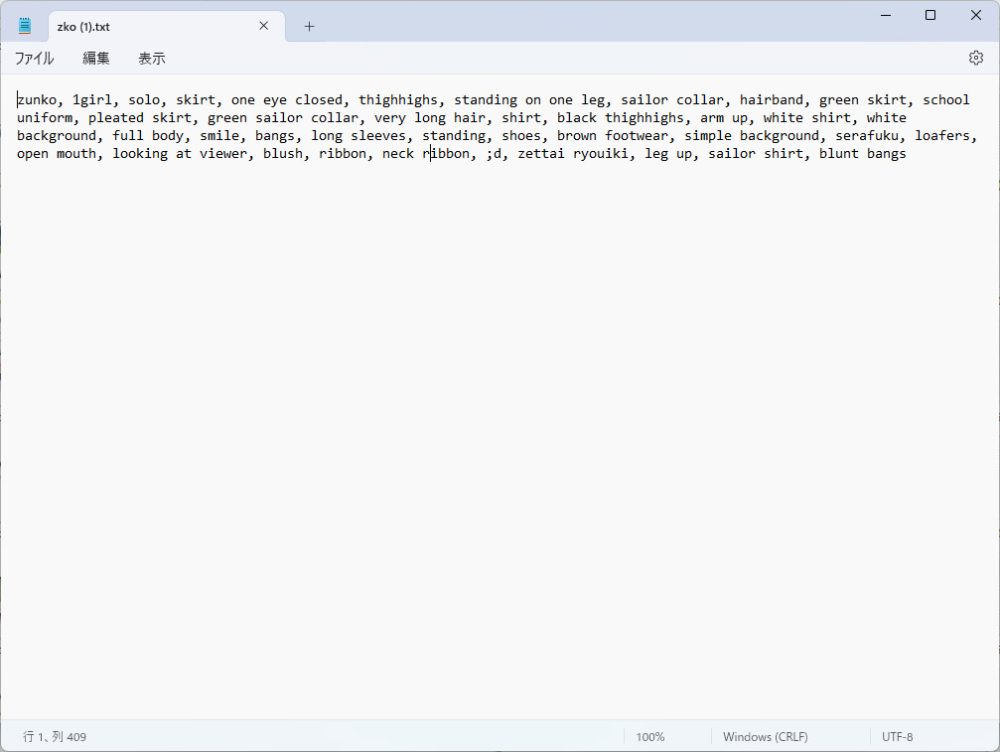
先頭にはトリガーワードになるzunkoが定義されています。
キャプションファイルには髪とひと瞳の色などの情報がが含まれていないため、それらの特徴がトリガーワードのzunkoに関連付けられていることがわかります。
LoRAで追加学習を行う手順
LoRAで追加学習を行う手順は以下の記事で解説していますので、参考にしてください。
ディレクトリ構造もこちらの記事の内容をもとに説明します。

先ほどダウンロードした東北ずん子のファイルをそのまま学習用画像を格納するreference_imageのフォルダにコピーします。
/notebooks/ (ルートディレクトリ)
└── TrainingData
├── reference_image (素材画像)
├── regularized_image (正則化画像)
├── outputs (出力ファイル)
└── datasetconfig.toml今回は以下のようにPaperspaceのディレクトリにアップロードしました。ファイルを一切加工することなく即LoRAの学習に使用できます。

LoRA追加学習に使用した環境
LoRAの追加学習では膨大な量の計算を行う必要があるため、高速なGPUが必要となります。
今回はNVIDIAのNVIDIA Quadro P5000というグラフィックアクセラレータを使用して、学習時間を計測します。ブーストクロック時8.86 TFLOPSの性能を出す高性能GPUです。

Quadro P5000のスペック
| 項目 | 値 |
|---|---|
| GPU名 | GP104 |
| アーキテクチャ | Pascal |
| 製造プロセス | 16 nm |
| ベースクロック | 1607 MHz |
| ブーストクロック | 1733 MHz |
| 浮動小数点演算性能 | 8.86 TFLOPS(= 2560コア * 2FLOP/コア * 1733MHz) |
| メモリサイズ | 16 GB |
| メモリタイプ | GDDR5X |
| メモリクロック | 1251 MHz (10 Gbps effective) |
| バンド幅 | 320 GB/s |
| バス幅 | 256 bit |
LoRA追加学習に関するパラメータの設定 繰り返し:2、エポック数:3
パラメータの設定
datasetconfig.tomlの設定
datasetconfig.tomlで定義している繰り返し回数num_repeatsを2に変更します。
[general]
[[datasets]]
[[datasets.subsets]]
image_dir = '/notebooks/TrainingData/reference_image'
caption_extension = '.txt'
num_repeats = 2accelerate launchコマンド
accelerate launchコマンドのパラメータとして設定するエポック数max_train_epochsを3に変更します。
accelerate launch --num_cpu_threads_per_process 1 train_network.py --pretrained_model_name_or_path=/notebooks/stable-diffusion-webui/models/Stable-diffusion/breakdomain_M2000.safetensors --output_dir=/notebooks/TrainingData/outputs --output_name=zunko_breakdomain_M2000_repeats2_epochs3 --dataset_config=/notebooks/TrainingData/datasetconfig.toml --train_batch_size=1 --max_train_epochs=3 --resolution=512,512 --optimizer_type=AdamW8bit --learning_rate=1e-4 --network_dim=128 --network_alpha=64 --enable_bucket --bucket_no_upscale --lr_scheduler=cosine_with_restarts --lr_scheduler_num_cycles=4 --lr_warmup_steps=500 --keep_tokens=1 --shuffle_caption --caption_dropout_rate=0.05 --save_model_as=safetensors --clip_skip=2 --seed=42 --color_aug --xformers --mixed_precision=fp16 --network_module=networks.lora --persistent_data_loader_workersLoRA追加学習の実行結果
学習結果が以下となります。
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/paths.py:27: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('/usr/local/lib/python3.10/dist-packages/cv2/../../lib64')}
warn(
CUDA SETUP: CUDA runtime path found: /usr/local/cuda-11.6/lib64/libcudart.so
CUDA SETUP: Highest compute capability among GPUs detected: 6.1
CUDA SETUP: Detected CUDA version 116
CUDA SETUP: Loading binary /usr/local/lib/python3.10/dist-packages/bitsandbytes/libbitsandbytes_cuda116_nocublaslt.so...
use 8-bit AdamW optimizer | {}
override steps. steps for 3 epochs is / 指定エポックまでのステップ数: 366
running training / 学習開始
num train images * repeats / 学習画像の数×繰り返し回数: 122
num reg images / 正則化画像の数: 0
num batches per epoch / 1epochのバッチ数: 122
num epochs / epoch数: 3
batch size per device / バッチサイズ: 1
gradient accumulation steps / 勾配を合計するステップ数 = 1
total optimization steps / 学習ステップ数: 366
steps: 0%| | 0/366 [00:00<?, ?it/s]
epoch 1/3
steps: 33%|███████████████████████████████████████████████████▋ | 122/366 [02:39<05:18, 1.31s/it, loss=0.103]
epoch 2/3
steps: 67%|██████████████████████████████████████████████████████████████████████████████████████████████████████▋ | 244/366 [05:24<02:42, 1.33s/it, loss=0.0896]
epoch 3/3
steps: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 366/366 [08:10<00:00, 1.34s/it, loss=0.0806]
saving checkpoint: /notebooks/TrainingData/outputs/zunko_breakdomain_M2000_repeats2_epochs3.safetensors
model saved.
steps: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 366/366 [08:13<00:00, 1.35s/it, loss=0.0806]学習時間
学習ステップ数: 366となり、学習時間は08:13かかりました。
LoRAを使って生成した画像
こちらがLoRAを使って生成された画像です。
ステップ数が少なく学習が弱いので、ベースモデルのbreakdomain_M2000のタッチが強いイラストとなっていますが、ずん子さんの瞳や髪の色、髪飾りが描かれています。

LoRA追加学習に関するパラメータの設定 繰り返し:10、エポック数:10
パラメータの設定
datasetconfig.tomlの設定
datasetconfig.tomlで定義している繰り返し回数num_repeatsを10に変更します。
[general]
[[datasets]]
[[datasets.subsets]]
image_dir = '/notebooks/TrainingData/reference_image'
caption_extension = '.txt'
num_repeats = 10accelerate launchコマンド
accelerate launchコマンドのパラメータとして設定するエポック数max_train_epochsを10に変更します。
accelerate launch --num_cpu_threads_per_process 1 train_network.py --pretrained_model_name_or_path=/notebooks/stable-diffusion-webui/models/Stable-diffusion/breakdomain_M2000.safetensors --output_dir=/notebooks/TrainingData/outputs --output_name=zunko_breakdomain_M2000_repeats10_epochs10 --dataset_config=/notebooks/TrainingData/datasetconfig.toml --train_batch_size=1 --max_train_epochs=10 --resolution=512,512 --optimizer_type=AdamW8bit --learning_rate=1e-4 --network_dim=128 --network_alpha=64 --enable_bucket --bucket_no_upscale --lr_scheduler=cosine_with_restarts --lr_scheduler_num_cycles=4 --lr_warmup_steps=500 --keep_tokens=1 --shuffle_caption --caption_dropout_rate=0.05 --save_model_as=safetensors --clip_skip=2 --seed=42 --color_aug --xformers --mixed_precision=fp16 --network_module=networks.lora --persistent_data_loader_workersLoRA追加学習の実行結果
学習結果が以下となります。
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/paths.py:27: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('/usr/local/lib/python3.10/dist-packages/cv2/../../lib64')}
warn(
CUDA SETUP: CUDA runtime path found: /usr/local/cuda-11.6/lib64/libcudart.so
CUDA SETUP: Highest compute capability among GPUs detected: 6.1
CUDA SETUP: Detected CUDA version 116
CUDA SETUP: Loading binary /usr/local/lib/python3.10/dist-packages/bitsandbytes/libbitsandbytes_cuda116_nocublaslt.so...
use 8-bit AdamW optimizer | {}
override steps. steps for 10 epochs is / 指定エポックまでのステップ数: 6100
running training / 学習開始
num train images * repeats / 学習画像の数×繰り返し回数: 610
num reg images / 正則化画像の数: 0
num batches per epoch / 1epochのバッチ数: 610
num epochs / epoch数: 10
batch size per device / バッチサイズ: 1
gradient accumulation steps / 勾配を合計するステップ数 = 1
total optimization steps / 学習ステップ数: 6100
steps: 0%| | 0/6100 [00:00<?, ?it/s]
epoch 1/10
steps: 10%|██████████████▉ | 610/6100 [13:41<2:03:13, 1.35s/it, loss=0.0849]
epoch 2/10
steps: 20%|█████████████████████████████▌ | 1220/6100 [27:28<1:49:53, 1.35s/it, loss=0.0813]
epoch 3/10
steps: 30%|████████████████████████████████████████████▍ | 1830/6100 [41:13<1:36:11, 1.35s/it, loss=0.0841]
epoch 4/10
steps: 40%|███████████████████████████████████████████████████████████▏ | 2440/6100 [54:57<1:22:26, 1.35s/it, loss=0.0751]
epoch 5/10
steps: 50%|█████████████████████████████████████████████████████████████████████████ | 3050/6100 [1:08:42<1:08:42, 1.35s/it, loss=0.0777]
epoch 6/10
steps: 58%|█████████████████████████████████████████████████████████████████████████████████████▌ | 3526/6100 [1:19:24<57:58, 1.35s/it, loss=0.0769]steps: 60%|████████████████████████████████████████████████████████████████████████████████████████▊ | 3660/6100 [1:22:27<54:58, 1.35s/it, loss=0.0738]
epoch 7/10
steps: 70%|███████████████████████████████████████████████████████████████████████████████████████████████████████▌ | 4270/6100 [1:36:11<41:13, 1.35s/it, loss=0.0698]
epoch 8/10
steps: 80%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▍ | 4880/6100 [1:49:54<27:28, 1.35s/it, loss=0.0701]
epoch 9/10
steps: 90%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ | 5490/6100 [2:03:38<13:44, 1.35s/it, loss=0.0713]
epoch 10/10
steps: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6100/6100 [2:17:24<00:00, 1.35s/it, loss=0.0703]
saving checkpoint: /notebooks/TrainingData/outputs/zunko_breakdomain_M2000_repeats10_epochs10.safetensors
model saved.
steps: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 6100/6100 [2:17:26<00:00, 1.35s/it, loss=0.0703]学習時間
学習ステップ数: 6100となり、学習時間は2:17:26かかりました。
LoRAを使って生成した画像
こちらがLoRAを使って生成された画像です。
学習のステップ数をかなり増やしたため、学習に使用した画像のずん子さんがほぼそのまま描かれているようなイラストになりました。
学習用画像のキャラクターや人物を再現したい場合には、ステップ数を増やすことが有効であることが確認できました。

Stable Diffusionのテクニックを効率よく学ぶには?
 カピパラのエンジニア
カピパラのエンジニアStable Diffusionを使ってみたいけど、ネットで調べた情報を試してもうまくいかない…
 猫のエンジニア
猫のエンジニアそんな時は、操作方法の説明が動画で見られるUdemyがおすすめだよ!
動画学習プラットフォームUdemyでは、画像生成AIで高品質なイラストを生成する方法や、AIの内部で使われているアルゴリズムについて学べる講座が用意されています。
Udemyは講座単体で購入できるため安価で(セール時1500円くらいから購入できます)、PCが無くてもスマホでいつでもどこでも手軽に学習できます。
Stable Diffusionに特化して学ぶ
Stable Diffusionに特化し、クラウドコンピューティングサービスPaperspaceでの環境構築方法から、モデルのマージ方法、ControlNetを使った構図のコントロールなど、中級者以上のレベルを目指したい方に最適な講座です。
画像生成AIの仕組みを学ぶ
画像生成AIの仕組みについて学びたい方には、以下の講座がおすすめです。
画像生成AIで使用される変分オートエンコーダやGANのアーキテクチャを理解することで、よりクオリティの高いイラストを生成することができます。
まとめ
今回はStable DiffusionでLoRAの追加学習を行う際に使用できるデータセットと、パラメータ設定による学習結果の違いについて解説しました。
東北ずん子のデータセットを使うと、ファイルを学習用データのディレクトリにコピーするだけで、即LoRAの追加学習を実行できます。
また、学習をステップを6000まで増やすことで学習させたキャラクターを忠実に再現することができました。
LoRAを使う際の参考にしてみてください。
また、以下の記事で効率的にPythonのプログラミングスキルを学べるプログラミングスクールの選び方について解説しています。最近ではほとんどのスクールがオンラインで授業を受けられるようになり、仕事をしながらでも自宅で自分のペースで学習できるようになりました。
スキルアップや副業にぜひ活用してみてください。

スクールではなく、自分でPythonを習得したい方には、いつでもどこでも学べる動画学習プラットフォームのUdemyがおすすめです。
講座単位で購入できるため、スクールに比べ非常に安価(セール時1200円程度~)に学ぶことができます。私も受講しているおすすめの講座を以下の記事でまとめていますので、ぜひ参考にしてみてください。

それでは、また次の記事でお会いしましょう。













コメント