
 カピパラのエンジニア
カピパラのエンジニアLoRAの追加学習やってみたいけど難しそう…
 猫のエンジニア
猫のエンジニア手順は多いけど1つずつ説明通りにこなしていけば簡単だよ。
今回は画像生成AIであるStable Diffusionで、LoRAによる学習を実行する方法を解説します。
追加学習を行って自作のLoRAを作る作業は一見難しそうですが、今回解説するステップを1つずつこなしていけば誰でも作成することができます。
一度LoRAを作ってしまえば、お気に入りのキャラクターで生成し放題!
前回の記事「sd-scriptsのインストール方法を解説 | LoRA学習環境をPaperspace、Google Colaboratoryで構築」でLoRA追加学習を行うためのツール、sd-scriptsのインストール方法を解説しました。
今回はその続編として、実際にLoRAで用意した画像データを学習させる方法について解説します。
GUIではなくコマンドラインでの操作が少しややこしいですが、習得すれば自分が学習させたキャラクターの画像を存分に生成できますので、ぜひ活用してみてください。
- 追加学習LoRAの概要
- 追加学習に必要なデータセットの入手方法
- 追加学習を行うための手順
また、当ブログのStable Diffusionに関する記事を以下のページでまとめていますので、あわせてご覧ください。

Stable Diffusionの導入方法から応用テクニックまでを動画を使って習得する方法についても以下のページで紹介しています。

Stable Diffusionとは
Stable Diffusion(ステーブル・ディフュージョン)は2022年8月に無償公開された描画AIです。ユーザーがテキストでキーワードを指定することで、それに応じた画像が自動生成される仕組みとなっています。
NVIDIAのGPUを搭載していれば、ユーザ自身でStable Diffusionをインストールし、ローカル環境で実行することも可能です。
(出典:wikipedia)
Stable DiffusionのWeb UI AUTOMATIC1111
AUTOMATIC1111はStable Diffusionをブラウザから利用するためのWebアプリケーションです。
AUTOMATIC1111を使用することで、プログラミングを一切必要とせずにStable Diffusionで画像生成を行うことが可能になります。
Web UI AUTOMATIC1111のインストール方法
Web UIであるAUTOMATIC1111を実行する環境は、ローカル環境(自宅のゲーミングPCなど)を使用するか、クラウドコンピューティングサービスを利用する2通りの方法があります。
以下の記事ではそれぞれの環境構築方法について詳し解説していますので、合わせてご覧ください。
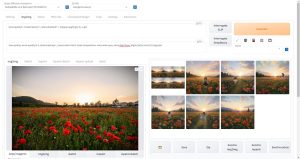
LoRA(Low-Rank Adaptation)とは
LoRA(Low-Rank Adaptation)は、既存のStable Diffusionモデルを20枚程度の画像を用いて追加学習させることにより微調整することができる仕組みです。LoRAを用いることにより、キャラクターや服装などの特徴を固定して画像生成することが可能になります。
LoRAの詳細については以下の記事で解説していますので、あわせてご覧ください。

LoRA(Low-Rank Adaptation)を使用することで、学習させたキャラクターや衣装を固定して画像生成が可能。

LoRA(Low-Rank Adaptation)の学習環境を用意する
LoRAで学習を行うためにKohya S.さんが公開されているsd-scriptsというツールを使用します。
sd-scriptsのインストール方法を以下の記事で解説していますので、事前に済ませておいてください。

LoRA(Low-Rank Adaptation)の学習方式
sd-scriptで使用できるLoRAの学習方式には以下の3つがあります。
- Dreambooth class+identifier
- Dreambooth キャプション
- fine tuning
Dreambooth class+identifierでは学習内容を細かく指定するのが難しく、fine tuningは学習コストが高いため、今回はDreambooth キャプションを使って学習を行います。
尚、今回紹介する学習手順はテルルとロビン【てるろび】旧やすらぼさんがYouTubeで公開されている「日本一わかりやすいLoRA学習!sd-scripts導入から学習実行まで解説!東北ずん子LoRAを作ってみよう!【Stable Diffusion】」を参考にさせて頂きました。
LoRA学習で使用するディレクトリ構造
学習に使用する作業フォルダとしてTrainingDataを作成し、その中に必要なデータを配置します。
/notebooks/ (ルートディレクトリ)
└── TrainingData
├── reference_image (素材画像)
├── regularized_image (正則化画像)
├── outputs (出力ファイル)
└── datasetconfig.toml/notebooks/がルートフォルダで、その下にTrainingDataフォルダがあります。そしてTrainingDataの下には役割が明示されたreference_image, regularized_image, outputsという3つのサブフォルダと、datasetconfig.tomlというファイルがあります。datasetconfig.tomlは最後に作成しますので、まずはフォルダ構造だけを以下のように作成してください。
ルートディレクトリはPaperspace場合ですので、他の環境の場合は任意のディレクトリに置き換えてください。
LoRAで学習を行う手順
LoRAで追加学習を行うまでの作業の流れは以下の通りです。
LoRAで学習させる画像のデータセットを用意します。学習させたい要素が含まれる画像を、最低20枚程度用意します。
用意したデータセットの個々の画像に対して、学習させたくない内容を定義するキャプションファイルを作成します。
stable-diffusion-webui-wd14-taggerというツールを使って、データセットの画像を表現するプロンプトを自動生成し、そこから学習させたいプロンプトを削除します。
設定ファイル「datasetconfig.toml」を作成し、データセットが格納されているディレクトリや、学習の繰り返し回数を定義します。
Accelerateは、PyTorchやTensorFlowの分散トレーニングを容易にするライブラリです。Accelerateを使用してLoRAの追加学習を実行するために必要なパラメータを定義します。
STEP4で作成したAccelerateを元に、追加学習を実行します。
①学習用の画像素材を用意する
今回、学習に使用するデータはsd-scripts製作者のKohya S.さんが公開されているカエルの画像をお借りしました。

サンプルデータの中からランダムに6枚ほど選んで使用します。
画像をreference_imageのディレクトリに配置します。
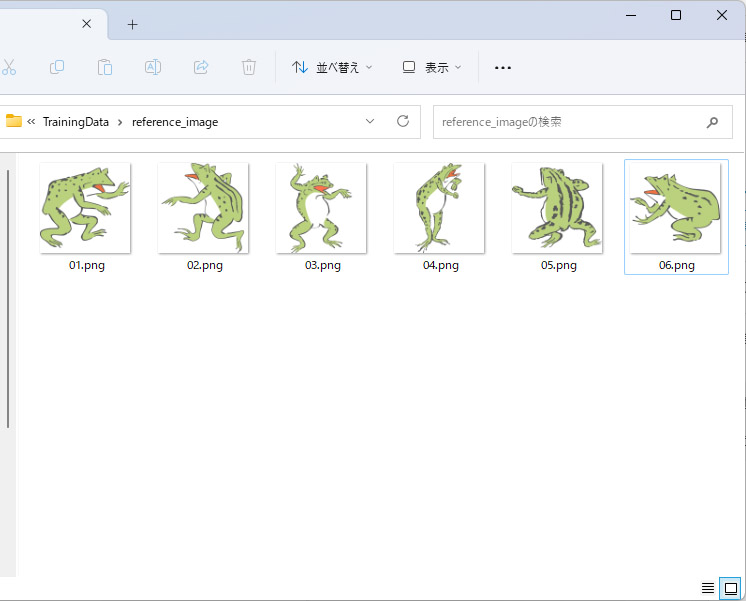
LoRAの練習におすすめのデータセット
今回は手順を覚えて頂くために、少ない画像を手作業で用意しますが、手順を覚えて後にもう少し実践的なデータで練習したいという方向けに、無料で使用できる最適なデータセットを以下の記事で解説しています。

②キャプションファイルを作成する
続いて学習内容を指定するためのキャプションファイルを作成思案す。
stable-diffusion-webui-wd14-taggerのインストール
キャプションファイルの作成には、AUTOMATIC1111 Web UIの拡張機能として使用できるstable-diffusion-webui-wd14-taggerというツールを使用します。

stable-diffusion-webui-wd14-taggerは、読み込んだ画像ファイルを解析し、その画像を表現するプロンプトをテキストファイルとして生成するツールです。
インストール手順
Web UIを起動したらExtensions→Install from URLと進み、以下のURLを入力してください。
https://github.com/toriato/stable-diffusion-webui-wd14-tagger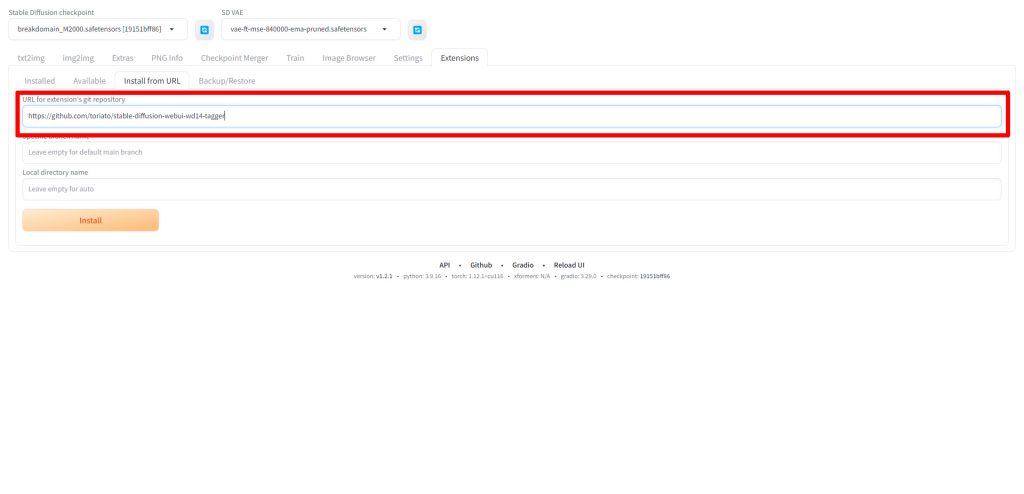
URLを入力したら、Installをクリックしてtaggerをインストールします。
インストールが完了したらWeb UIを再起動します。
taggerでのキャプション生成手順
Web UIが再起動したら、Taggerのタブが追加されていますのでクリックします。
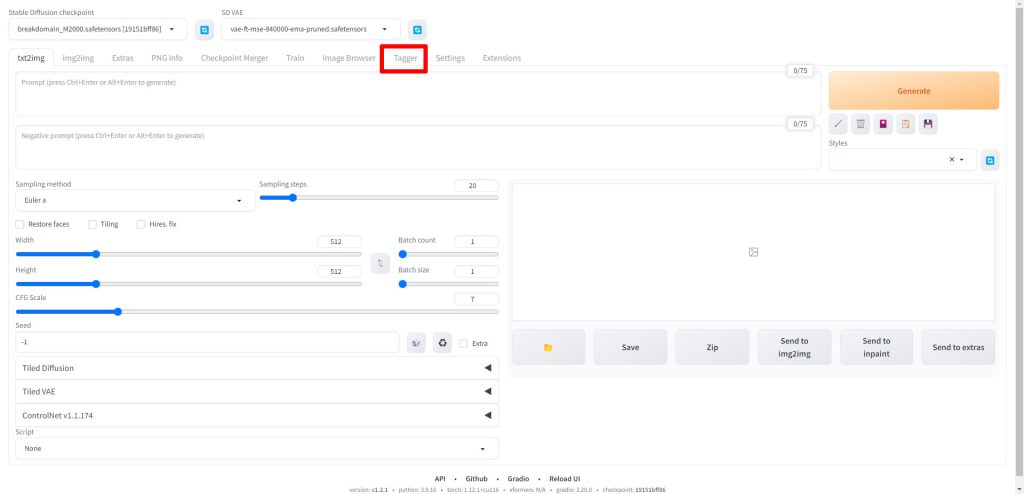
Batch from directoryのタブをクリックします。
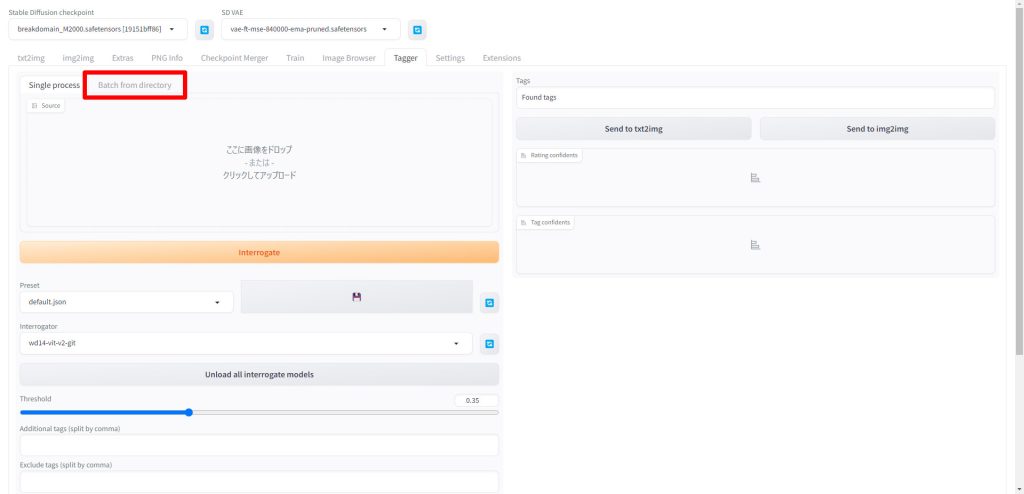
Input directoryとOutput directoryに学習用画像が配置されているディレクトリのパスを入力します。
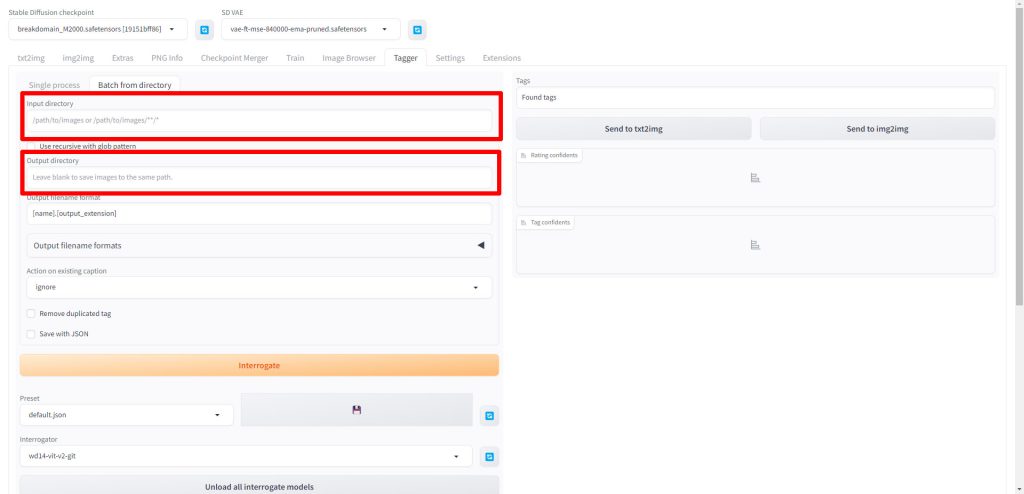
Additional tags(split by comma)にトリガーワードに使用したい文字列を設定します。今回はカエルの画像を学習させるためkero_chanとしました。
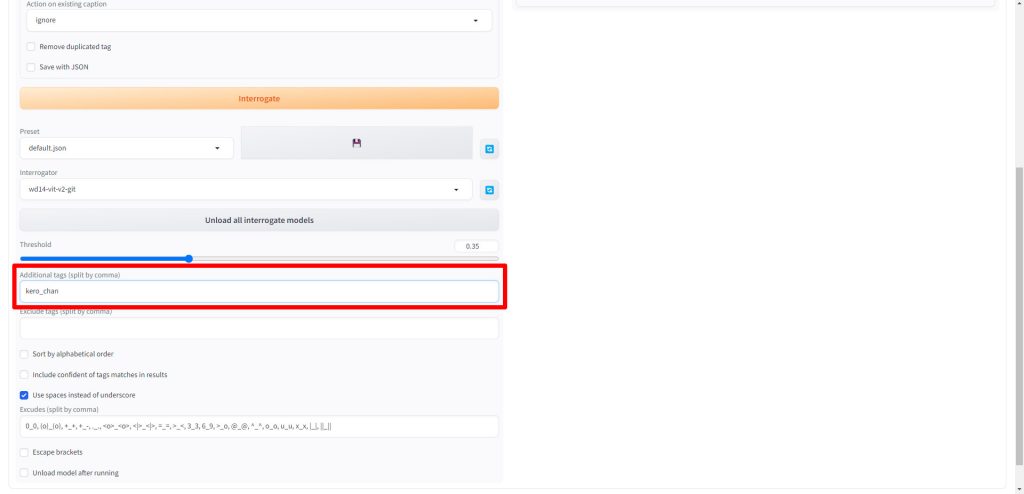
最後にInterrogateをクリックします。
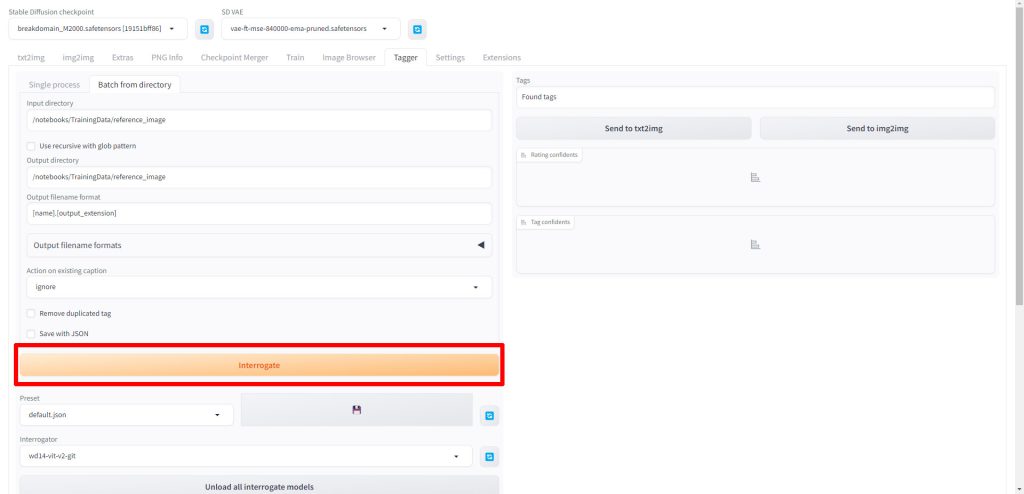
以下のようにメッセージが表示されたら、キャプションの生成が完了しました。
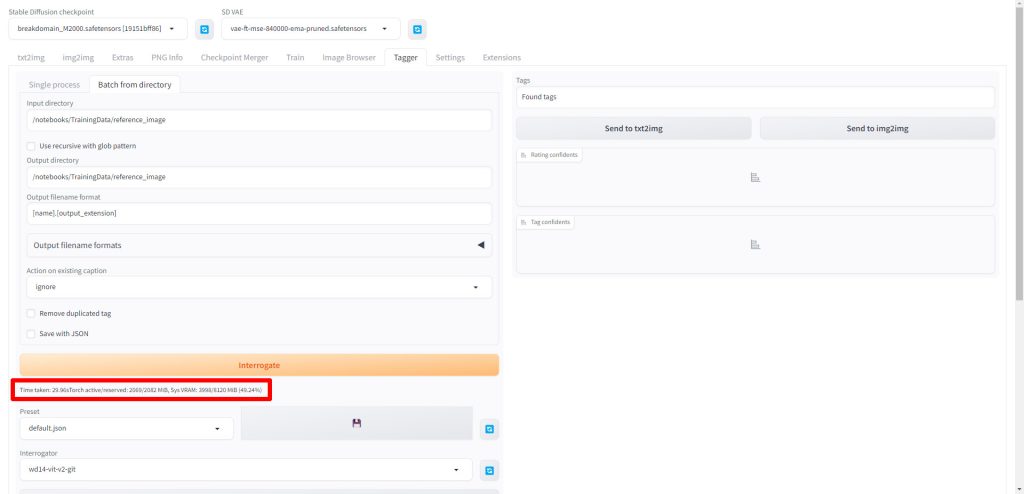
先ほど指定したディレクトリを確認すると、学習用の画像ファイルと同じ名前のテキストファイルが生成されていることが確認できました。
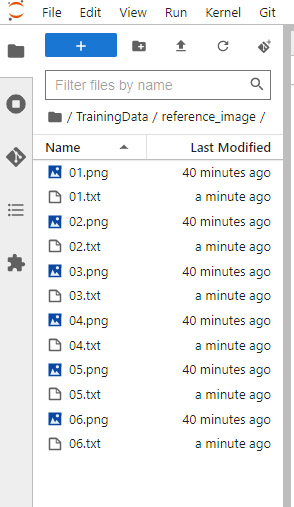
キャプションファイルを修正する
生成されたタグ
今回は例として01.txtのファイルを確認してみます。以下のような内容となっています。
先頭には先ほど設定したトリガーワードが定義されています。
kero chan, no humans, white background, simple background, solo, open mouth, full body, dinosaur, from side, clawsこのファイルは先ほど読み込んだ01.pngのカエルの画像を表現する文字列が並んでいます。
キャプションファイルは過学習を防止するための情報を保持するファイルであるため、学習させたくない内容を定義しておくものになります。
逆に、学習させたい内容を表す文字列はキャプションファイルから削除する必要があります。
学習させたい内容はキャプションファイルから削除する。
[素材]-[キャプション]=[学習データ]
修正後のタグ
01.txtの内容を以下のように、トリガーワードと学習させたくない内容だけに編集しました。
kero chan, white background, simple background, dinosaur同様の作業を他の全てのキャプションファイルにも実施します。
③datasetconfig.tomlを作成する
続いて学習に必要な設定ファイルdatasetconfig.tomlを作成します。
テンプレートを作成する
まず以下のテンプレートをメモ帳などにコピーしてください。
[general]
[[datasets]]
[[datasets.subsets]]
image_dir = '\notebooks\TrainingData\reference_image'
caption_extension = '.txt'
num_repeats = 1パラメータを変更する
image_dirの行に学習に使用する画像ファイルが格納されているディレクトリを指定します。
image_dir = '\notebooks\TrainingData\reference_image'num_repeats繰り返し学習する回数を指定します。
num_repeats = 1ファイル名と拡張子を変更する
最後にファイルをdatasetconfig.tomlという名前で保存します。
その際、エンコードを必ずUTF-8に設定して保存してください。
④Accelerateのコマンドを作成する
今回使用するAccelerateは、PyTorchやTensorFlowの分散トレーニングを容易にするライブラリです。
このAccelerateを実行するためのコマンドに渡すパラメータを設定することにより、LoRAで学習する内容に対する指示を行います。
LoRAの学習はMeta社が開発したPyTorchというライブラリによって実行されます。
PyTorchは、Pythonで記述されたオープンソースの機械学習ライブラリで、旧Facebookの人工知能研究グループにより開発されています。accelerate launchコマンドの詳細は以下のページを参考にしてください。

コマンドテンプレート
まず、以下のaccelerate launchコマンドのテンプレートをメモ帳などにコピーしてください。
accelerate launch --num_cpu_threads_per_process 1 train_network.py
--pretrained_model_name_or_path=X:\YOUR_FAVORITE_MODEL_PATH.safetensors
--output_dir=D:\TrainingData\outputs
--output_name=FILE_NAME_HERE
--dataset_config=D:\TrainingData\datasetconfig.toml
--train_batch_size=1
--max_train_epochs=10
--resolution=512,512
--optimizer_type=AdamW8bit
--learning_rate=1e-4
--network_dim=128
--network_alpha=64
--enable_bucket
--bucket_no_upscale
--lr_scheduler=cosine_with_restarts
--lr_scheduler_num_cycles=4
--lr_warmup_steps=500
--keep_tokens=1
--shuffle_caption
--caption_dropout_rate=0.05
--save_model_as=safetensors
--clip_skip=2
--seed=42
--color_aug
--xformers
--mixed_precision=fp16
--network_module=networks.lora
--persistent_data_loader_workersそして必要な個所のパラメータを変更します。
今回は手順を覚えて頂くという目的であるため、最低限の項目のみ解説します。
コマンド解説
学習に使用するモデルを指定します。実際にLoRAを使って画像生成を行う際に使用するモデルを設定してください。
ここはLoRAファイルを指定するのではなく、SDで画像生成する際に使用したいモデル(ベースとなるモデル)を指定します。
例えばリアル系であればChilloutMix、アニメ系であればSukiyakiMixV1などです。
LoRAは既存のStable Diffusionのモデルに対して局所的に追加学習を行うという形になるため、使いたいモデルごとにLoRAファイルを用意する必要になります。
--pretrained_model_name_or_path=X:\YOUR_FAVORITE_MODEL_PATH.safetensors作成したLoRAファイルを出力するディレクトリのパスを指定します。
--output_dir=D:\TrainingData\outputs先ほど作成したdatasetconfig.tomlファイルが配置されているパスを指定します。
--dataset_config=D:\TrainingData\datasetconfig.tomltrain_batch_sizeは使用できるメモリに余裕がある場合は、高い数値を設定すると学習の速度が向上します。
--train_batch_size=1今回、紹介した以外の項目は、必要に応じて変更してください。
実際に使用するコマンドを作成する
先ほどのコマンドのテンプレートを実際に使用できる形に整形します。
- 全ての改行を削除する
- コマンド間は半角一文字分のスペースを入れる
整形後のコマンド例
整形後のコマンド例です。
整形後は以下のように全てのコマンドが1行に集約されます。
今回はPaperspaceで実行する場合の例として作成しました。パスなどは各環境に合わせて変更してください。
accelerate launch --num_cpu_threads_per_process 1 train_network.py --pretrained_model_name_or_path=/notebooks/stable-diffusion-webui/models/Stable-diffusion/breakdomain_M2000.safetensors --output_dir=/notebooks/TrainingData/outputs --output_name=FILE_NAME_HERE --dataset_config=/notebooks/TrainingData/datasetconfig.toml --train_batch_size=1 --max_train_epochs=10 --resolution=512,512 --optimizer_type=AdamW8bit --learning_rate=1e-4 --network_dim=128 --network_alpha=64 --enable_bucket --bucket_no_upscale --lr_scheduler=cosine_with_restarts --lr_scheduler_num_cycles=4 --lr_warmup_steps=500 --keep_tokens=1 --shuffle_caption --caption_dropout_rate=0.05 --save_model_as=safetensors --clip_skip=2 --seed=42 --color_aug --xformers --mixed_precision=fp16 --network_module=networks.lora --persistent_data_loader_workers⑤LoRA学習を実行する
accelerateコマンドを実行して学習を行います。
accelerate launchコマンドを実行する
まず、コマンドラインを起動したらsd-scriptsのディレクトリに移動します。
(ルートディレクトリは環境に応じて変更してください)
cd /notebooks/sd-scripts/コマンドラインに先ほどのaccelerate launchコマンドとパラメータを貼り付け、実行します。
accelerate launch --num_cpu_threads_per_process 1 train_network.py --pretrained_model_name_or_path=/notebooks/stable-diffusion-webui/models/Stable-diffusion/breakdomain_M2000.safetensors --output_dir=/notebooks/TrainingData/outputs --output_name=FILE_NAME_HERE --dataset_config=/notebooks/TrainingData/datasetconfig.toml --train_batch_size=1 --max_train_epochs=10 --resolution=512,512 --optimizer_type=AdamW8bit --learning_rate=1e-4 --network_dim=128 --network_alpha=64 --enable_bucket --bucket_no_upscale --lr_scheduler=cosine_with_restarts --lr_scheduler_num_cycles=4 --lr_warmup_steps=500 --keep_tokens=1 --shuffle_caption --caption_dropout_rate=0.05 --save_model_as=safetensors --clip_skip=2 --seed=42 --color_aug --xformers --mixed_precision=fp16 --network_module=networks.lora --persistent_data_loader_workers実行結果
正常に学習が実行されると以下のように学習ログが出力されます。
/usr/local/lib/python3.10/dist-packages/bitsandbytes/cuda_setup/paths.py:27: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('/usr/local/lib/python3.10/dist-packages/cv2/../../lib64')}
warn(
CUDA SETUP: CUDA runtime path found: /usr/local/cuda-11.6/lib64/libcudart.so
CUDA SETUP: Highest compute capability among GPUs detected: 6.1
CUDA SETUP: Detected CUDA version 116
CUDA SETUP: Loading binary /usr/local/lib/python3.10/dist-packages/bitsandbytes/libbitsandbytes_cuda116_nocublaslt.so...
use 8-bit AdamW optimizer | {}
override steps. steps for 10 epochs is / 指定エポックまでのステップ数: 60
running training / 学習開始
num train images * repeats / 学習画像の数×繰り返し回数: 6
num reg images / 正則化画像の数: 0
num batches per epoch / 1epochのバッチ数: 6
num epochs / epoch数: 10
batch size per device / バッチサイズ: 1
gradient accumulation steps / 勾配を合計するステップ数 = 1
total optimization steps / 学習ステップ数: 60
steps: 0%| | 0/60 [00:00<?, ?it/s]
epoch 1/10
steps: 10%|███████████████▎ | 6/60 [00:11<01:39, 1.83s/it, loss=0.0698]
epoch 2/10
steps: 20%|██████████████████████████████▍ | 12/60 [00:20<01:20, 1.68s/it, loss=0.0577]
epoch 3/10
steps: 30%|█████████████████████████████████████████████▌ | 18/60 [00:29<01:08, 1.62s/it, loss=0.0535]
epoch 4/10
steps: 40%|████████████████████████████████████████████████████████████▊ | 24/60 [00:38<00:57, 1.60s/it, loss=0.0265]
epoch 5/10
steps: 50%|████████████████████████████████████████████████████████████████████████████ | 30/60 [00:47<00:47, 1.58s/it, loss=0.0506]
epoch 6/10
steps: 60%|███████████████████████████████████████████████████████████████████████████████████████████▏ | 36/60 [00:56<00:37, 1.57s/it, loss=0.0424]
epoch 7/10
steps: 70%|██████████████████████████████████████████████████████████████████████████████████████████████████████████▍ | 42/60 [01:05<00:28, 1.57s/it, loss=0.0388]
epoch 8/10
steps: 80%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▌ | 48/60 [01:14<00:18, 1.56s/it, loss=0.0404]
epoch 9/10
steps: 90%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▊ | 54/60 [01:24<00:09, 1.56s/it, loss=0.0353]
epoch 10/10
steps: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 60/60 [01:33<00:00, 1.55s/it, loss=0.0642]
saving checkpoint: /notebooks/TrainingData/outputs/kero_chan01.safetensors
model saved.
steps: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 60/60 [01:35<00:00, 1.60s/it, loss=0.0642]
root@XXXXXXX:/notebooks/sd-scripts# 最後にsaving checkpointとしてモデル名が表示されたら学習完了です。
saving checkpoint: /notebooks/TrainingData/outputs/kero_chan01.safetensors最初に作成したoutputsフォルダの中にkero_chan01.safetensorsが生成されています。
これでLoRAファイルの作成は完了です。
作成したLoRAファイルを使って画像を生成する
LoRAファイルが完成したら、最後にLoRAファイルを使って画像生成を行います。
実際にStable DiffusionでLoRAファイルを使って画像を生成する方法は、以下の記事で解説しています。

Stable Diffusionのテクニックを効率よく学ぶには?
カピパラのエンジニアStable Diffusionを使ってみたいけど、ネットで調べた情報を試してもうまくいかない…
猫のエンジニアそんな時は、操作方法の説明が動画で見られるUdemyがおすすめだよ!
動画学習プラットフォームUdemyでは、画像生成AIで高品質なイラストを生成する方法や、AIの内部で使われているアルゴリズムについて学べる講座が用意されています。
Udemyは講座単体で購入できるため安価で(セール時1500円くらいから購入できます)、PCが無くてもスマホでいつでもどこでも手軽に学習できます。
Stable Diffusionに特化して学ぶ
Stable Diffusionに特化し、クラウドコンピューティングサービスPaperspaceでの環境構築方法から、モデルのマージ方法、ControlNetを使った構図のコントロールなど、中級者以上のレベルを目指したい方に最適な講座です。
画像生成AIの仕組みを学ぶ
画像生成AIの仕組みについて学びたい方には、以下の講座がおすすめです。
画像生成AIで使用される変分オートエンコーダやGANのアーキテクチャを理解することで、よりクオリティの高いイラストを生成することができます。
まとめ
今回はsd-scriptsを使って実際にLoRA学習を実行する方法を解説しました。
実行する環境や内容によってさらにパラメータを調整することで良い結果を得られるようになりますので、データセットやパラメータを工夫してみてください。
LoRAに関するトピックを以下の記事でまとめています。
また、以下の記事で効率的にPythonのプログラミングスキルを学べるプログラミングスクールの選び方について解説しています。最近ではほとんどのスクールがオンラインで授業を受けられるようになり、仕事をしながらでも自宅で自分のペースで学習できるようになりました。
スキルアップや副業にぜひ活用してみてください。

スクールではなく、自分でPythonを習得したい方には、いつでもどこでも学べる動画学習プラットフォームのUdemyがおすすめです。
講座単位で購入できるため、スクールに比べ非常に安価(セール時1200円程度~)に学ぶことができます。私も受講しているおすすめの講座を以下の記事でまとめていますので、ぜひ参考にしてみてください。

それでは、また次の記事でお会いしましょう。













コメント