今回はMidjourneyと並んで話題の画像生成AI、Stable Diffusionを試してみました。Hugging Faceのトークンの作成から画像生成までを行う手順を解説していきたいともいます。

当ブログ内のStable Diffusionに関する記事を以下のページでまとめていますので、あわせてご覧ください。

以下のページで自然言語処理モデルGPT-3を使ったライティングツールCatchyで、Stable DiffusionのPromptを自動生成する方法について解説していますので、あわせてご覧ください。

Stable Diffusionとは
Stable Diffusion(ステーブル・ディフュージョン)は、オープンソースとして2022年8月に無償公開された画像生成AIです。Midjourneyと同様に描いてほしい画像のキーワードを指定することでそれに応じた画像を生成させることができます。
Stable Diffusionはオンライン上の研究コミュニティであるConpVisとLAION、およびロンドンを本拠とするAI企業Stability AIによって開発が行なっており、オープンソースコミュニティHugging Faceで公開されています。
出典:wikipedia


Hugging Faceのトークンを作成する
さてここからは実際にStable Diffusion使うための手順を解説していきます。
以下のHugging Faceのサイトにアクセスします。

ライセンスに関する説明が表示されますので、内容を確認したら「Access repository」をクリックします。
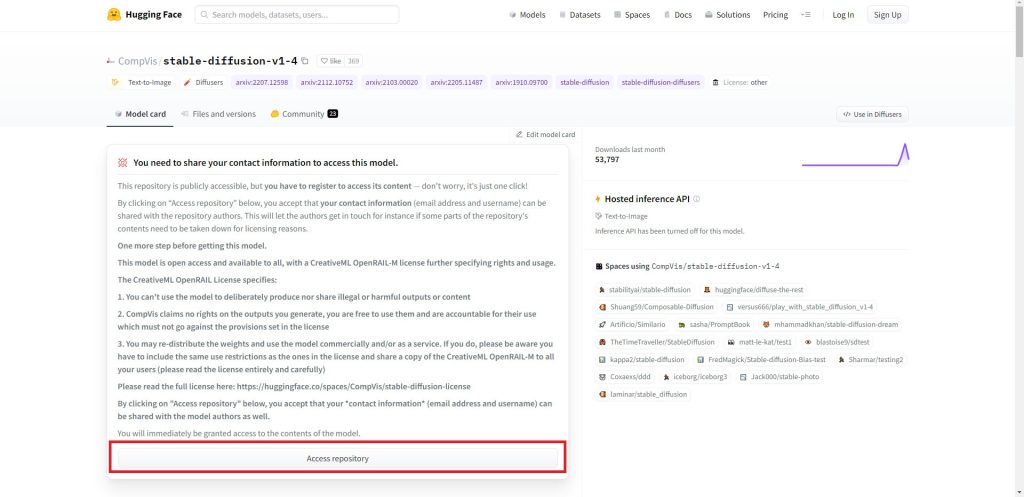
ログイン画面が表示されたらメールアドレスとパスワードを入力してログインします。ユーザー登録をされていない場合はSign Upからユーザー登録を行ってください。
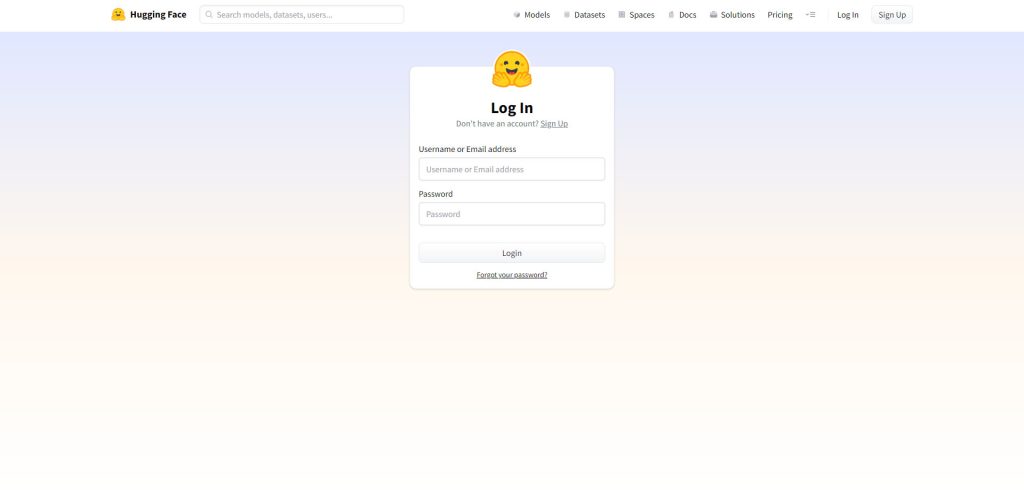
画面左側のメニューから「Settings」をクリックします。
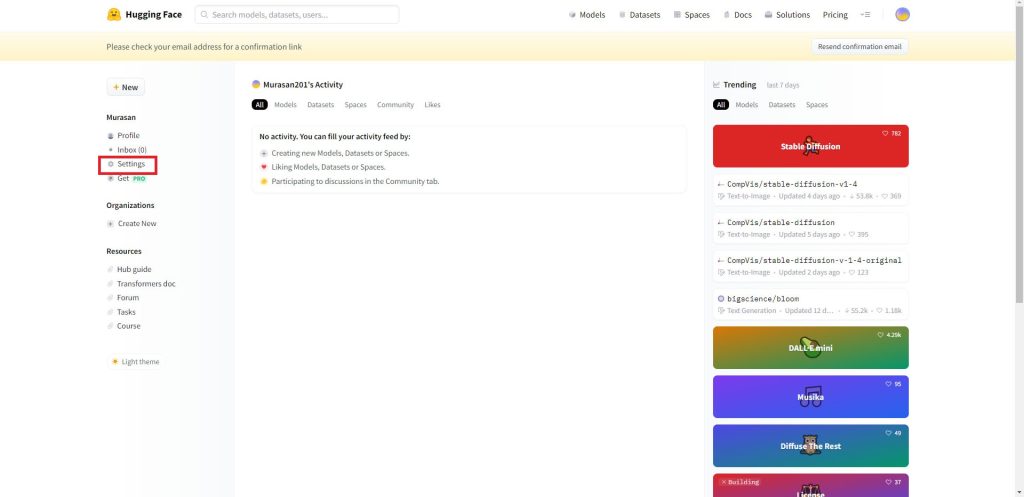
画面左側のメニューから「Access Tokens」をクリックします。
Access Tokensの画面が表示されたら、「New token」のボタンをクリックします。ボタンが押せない場合は登録したメールアドレスに認証の依頼が来ていますので、そちらを認証してから再度このページで確認してみてください。
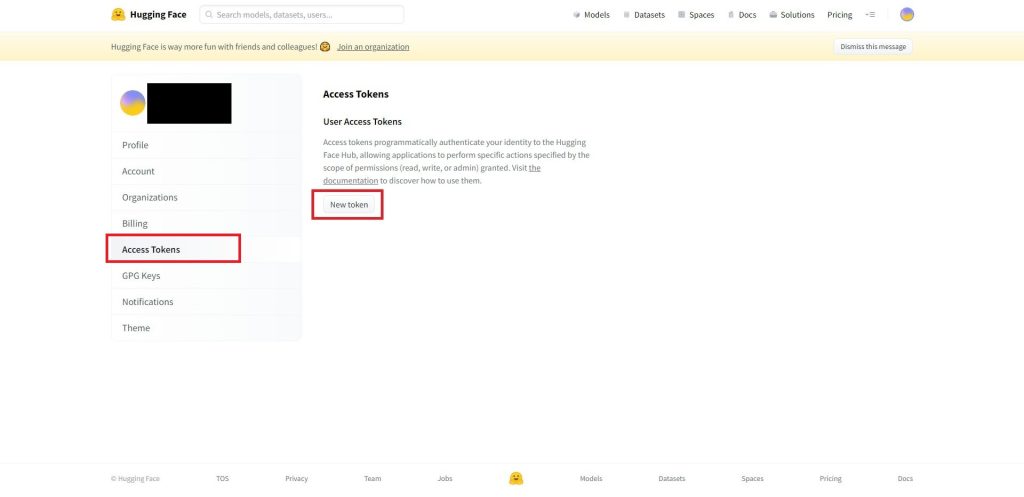
アクセストークンの名前を「Name」に登録します。忘れない名前を適当に入力すればOKです。Roleは「read」のままで「Generate a token」のボタンをクリックします。
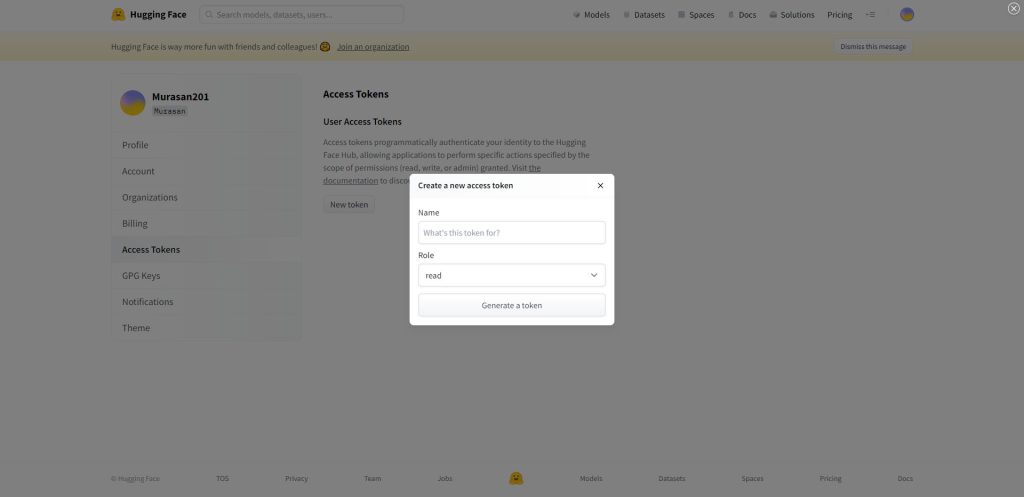
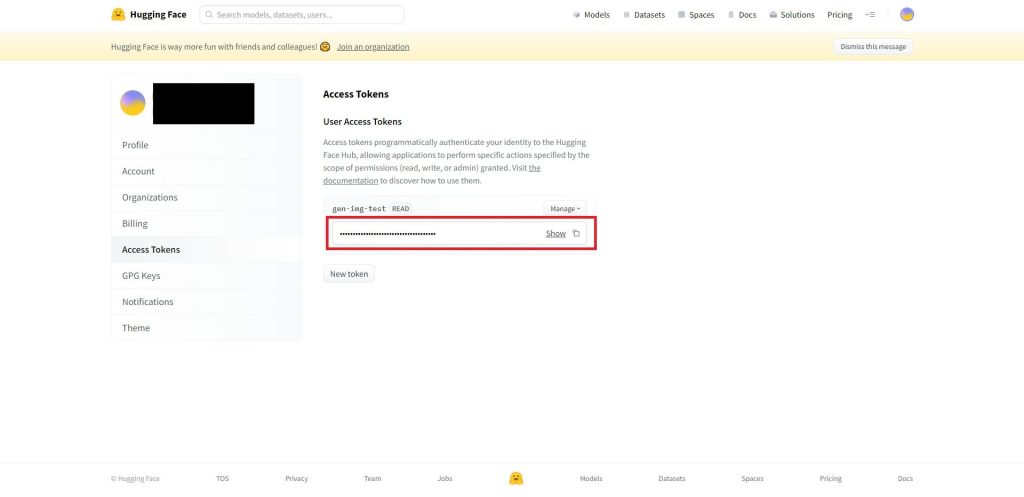
以下の画面のようにトークンが生成されますので、こちらをコピーしたらトークンの作成は完了です。
Stable Diffusionのインストール
以下のコマンドを実行します。
pip install diffusers==0.2.4 transformers scipy ftfy以下のようにインストールされたバージョンが表示されたらインストール完了です。
Successfully installed diffusers-0.2.4 ftfy-6.1.1 huggingface-hub-0.9.1 tokenizers-0.12.1 transformers-4.22.0あとは次の項目で紹介するPythonのコードを実行すればイラストを生成することができます。

作成したソースコード
ここからは実際にStable Diffusionに絵を描かせるためのコードを実装していきます。
ソースコード解説
先ほどHuggingFaceのサイトで生成したトークンを定数として設定します。
HF_TOKEN = "〇〇"画像生成に使用するデバイスを設定します。今回は私の環境ではグラボのないノートPCで使用したため「cpu」で設定しましたが、生成にものすごく時間がかかりました。
グラボを積んでいるPCかGoogle ColaboratoryなどGPUが使える環境では「cuda」と設定してください。
pipe.to("cpu")ここが一番重要な部分で、どのような画像を生成したいかを指示します。〇〇の部分に単語、もしくは英文で指示を記述します。単語、英文の間は「,」で区切って複数のキーワードで指定できます。
今回は「”a girl standing in a futuristic city, soft light, 8 k, cyberpunk colour palette, dramatic composition, dramatic lighting”」というキーワードで設定してみました。
prompt = "〇〇"実際に画像を生成する処理です。
どのような絵を描くかという指示のpromptと合わせて、「height」、「width」のパラメータで画像の出力サイズを指示することができます。ただモデル自体が512×512に最適化されているようで、この設定が一番高品質な絵が生成されるようです。
image = pipe(prompt, height=512, width=768)["sample"][0]作成した全体のソースコード
以下が全体のソースコードです。
from diffusers import StableDiffusionPipeline
from datetime import datetime
#HuggingFaceのトークン
HF_TOKEN = "〇〇"
#StableDiffusionパイプライン設定
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=HF_TOKEN)
#使用するデバイスを設定
#pipe.to("cuda")
pipe.to("cpu")
#生成したい画像を指示
prompt = "〇〇"
#画像生成
image = pipe(prompt)["sample"][0]
#生成した画像をファイル出力
date = datetime.now().strftime("%Y%m%d_%H%M%S") #現在の日時を取得
path = date + ".png" #ファイル名を生成した日時にする
image.save(path)「pipe.to(“cpu”)」の行までは初回のみでOKで、2回目以降はprompt = “〇〇”からだけで生成できますので、キーワードを色々変更して試してみてください。
発生したエラー
私の環境では実行時に以下のようなエラーが発生しました。
発生個所
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=HF_TOKEN)エラー内容
OSError: [WinError 1314] クライアントは要求された特権を保有していません。対策
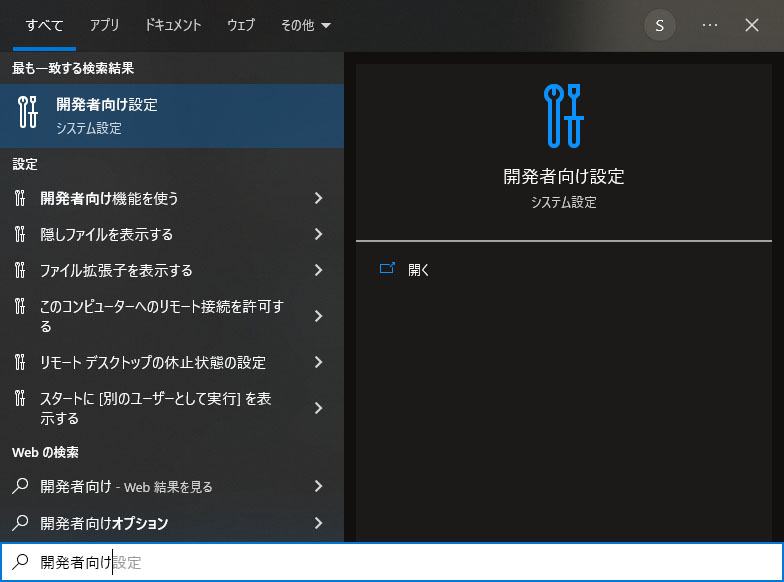
windowsの開発者向け設定を変更することで解決しました。
スタートメニューから開発者向け設定を検索して開きます。
「開発者モード」の設定をオンに変更します。
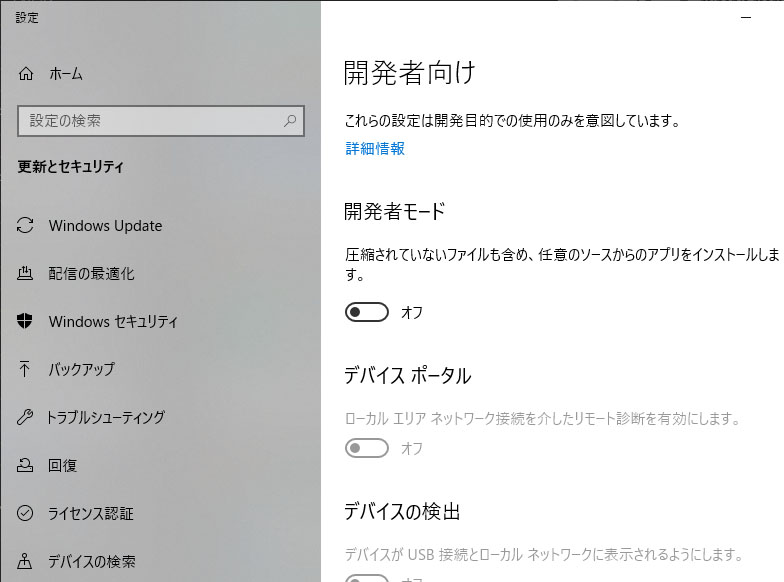
変更後、再度実行したらエラーは発生しませんでした。
実行結果
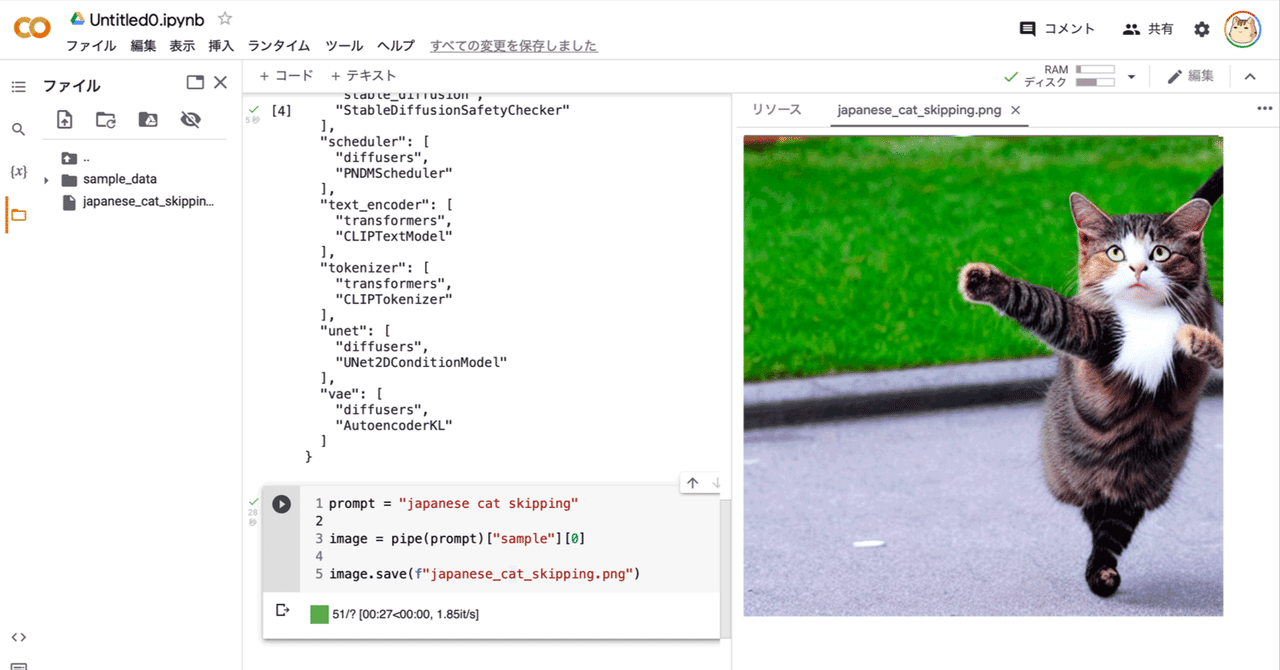
ソースコードの解説にも書きましたが、今回のテストでは以下のようなキーワードを試してみました。
a girl standing in a futuristic city, soft light, 8 k, cyberpunk colour palette, dramatic composition, dramatic lightingこのキーワードで実行したら以下のような画像が生成されました。

Stable Diffusionのテクニックを効率よく学ぶには?
 カピパラのエンジニア
カピパラのエンジニアStable Diffusionを使ってみたいけど、ネットで調べた情報を試してもうまくいかない…
 猫のエンジニア
猫のエンジニアそんな時は、操作方法の説明が動画で見られるUdemyがおすすめだよ!
動画学習プラットフォームUdemyでは、画像生成AIで高品質なイラストを生成する方法や、AIの内部で使われているアルゴリズムについて学べる講座が用意されています。
Udemyは講座単体で購入できるため安価で(セール時1500円くらいから購入できます)、PCが無くてもスマホでいつでもどこでも手軽に学習できます。
Stable Diffusionに特化して学ぶ
Stable Diffusionに特化し、クラウドコンピューティングサービスPaperspaceでの環境構築方法から、モデルのマージ方法、ControlNetを使った構図のコントロールなど、中級者以上のレベルを目指したい方に最適な講座です。
画像生成AIの仕組みを学ぶ
画像生成AIの仕組みについて学びたい方には、以下の講座がおすすめです。
画像生成AIで使用される変分オートエンコーダやGANのアーキテクチャを理解することで、よりクオリティの高いイラストを生成することができます。
まとめ
今回は画像生成AIであるStable Diffusionについて解説してみました。
私も何枚か試しに生成してみましたが、これだけのクオリティの画像を生成できるAIが無料で使えるというのは本当に驚きです。またStable Diffusionは商用利用が可能というのもうれしいですね。
2次元キャラクターの成功率を向上させるモデル、Waifu Difussionの使い方についても以下の記事で解説していますので、あわせてご覧ください。

以下のページで自然言語処理モデルGPT-3を使ったライティングツールCatchyで、Stable DiffusionのPromptを自動生成する方法について解説していますので、あわせてご覧ください。
また、以下の記事で効率的にPythonのプログラミングスキルを学べるプログラミングスクールの選び方について解説しています。最近ではほとんどのスクールがオンラインで授業を受けられるようになり、仕事をしながらでも自宅で自分のペースで学習できるようになりました。
スキルアップや副業にぜひ活用してみてください。

スクールではなく、自分でPythonを習得したい方には、いつでもどこでも学べる動画学習プラットフォームのUdemyがおすすめです。
講座単位で購入できるため、スクールに比べ非常に安価(セール時1200円程度~)に学ぶことができます。私も受講しているおすすめの講座を以下の記事でまとめていますので、ぜひ参考にしてみてください。

それでは、また次の記事でお会いしましょう。



参考










コメント