今回はStable Diffusionを使って風景写真からimg2imgでイラストを生成する方法について解説します。文章では指示が難しい構図もimg2imgを使用することで実現できますので、ぜひ参考にしてみてください。
また、当ブログのStable Diffusionに関する記事を以下のページでまとめていますので、あわせてご覧ください。

Stable Diffusionとは
Stable Diffusion(ステーブル・ディフュージョン)は2022年8月に無償公開された描画AIです。ユーザーがテキストでキーワードを指定することで、それに応じた画像が自動生成される仕組みとなっています。
NVIDIAのGPUを搭載していれば、ユーザ自身でStable Diffusionをインストールし、ローカル環境で実行することも可能です。
(出典:wikipedia)
Stable Diffusion 2.0の使い方は以下のページで解説しています。



Img2Img (Image-to-Image Translation) とは
従来の文章での指示をAIに入力して画像を生成する方法をtxt2img(Text-to-Image Translation)と言います。
それに対し、img2imgでは画像+文字を入力して画像を生成します。
これにより、文字だけでは難しい詳細な構図を、あらかじめ用意した写真や画像を使って指示することができます。
Stable Diffusionではimg2imgを使ったイラスト生成の機能も備えていますので、今回はPythonでimg2imgを使って生成する方法を解説します。
また、Stable DiffusionのWebUIであるAUTOMATIC1111でimg2imgを使う手順については、以下の記事で解説しています。
StableDiffusion 2.xのセットアップ
以下のコマンドを実行してパッケージをインストールします。
pip install diffusers[torch]==0.9 transformers
pip install --upgrade --pre tritonStableDiffusionのリポジトリを取得してインストールします。
pip install --upgrade git+https://github.com/huggingface/diffusers.git transformers accelerate scipy以上でStableDiffusion 2.0のセットアップは完了です。
作成したソースコード
ここからは実際にStable Diffusionを使って、img2imgでイラストを生成するためのPythonコードを実装する方法について解説します。
Pythonコード解説
ライブラリのインポート
必要なライブラリをインポートします。
img2imgの場合はパイプラインのメソッドが「StableDiffusionImg2ImgPipeline」に変更になります。
また、指示画像を読み込むため、画像処理ライブラリPILが必要になります。
from diffusers import EulerDiscreteScheduler, StableDiffusionImg2ImgPipeline
from PIL import Image学習済みモデルの指定
Stable Diffusionで使用する学習済みモデルを指定します。
今回はアニメ調のイラストを出力するため、「andite/anything-v4.0」を指定しています。従来のStable Diffusion標準モデルを使いたい場合は「stabilityai/stable-diffusion-2」に変更してください。
#使用するモデルを設定
model_id = "andite/anything-v4.0"画像の読み込み
イラストの構図を指示する画像を読み込み、リサイズを行います。この指示画像のサイズと同じサイズの画像が出力されます。(openメソッドの引数には画像のパスを指定してください)
#初期画像を取得
init_image = Image.open("/content/base-img/fall-3186876_1920.jpg")
init_image = init_image.convert("RGB")
init_image = init_image.resize((768, 768))pipeのパラメータ
イラストを生成するための推論処理を実行します。2つ目のパラメーターに指示画像を設定します。
text2imgではpipeメソッドで画像サイズを指定しましたが、img2imgの場合は指示画像のサイズにより生成画像のサイズが決まりますので、pipeメソッドのパラメータでサイズの指定はできません。
image = pipe(prompt, image=init_image).images[0]ソースコード全体
作成した全体のソースコードは以下の通りです。
from datetime import datetime
from diffusers import EulerDiscreteScheduler, StableDiffusionImg2ImgPipeline
import torch
from PIL import Image
#使用するモデルを設定
model_id = "stabilityai/stable-diffusion-2"
#StableDiffusionパイプライン設定
scheduler = EulerDiscreteScheduler.from_pretrained(model_id, subfolder="scheduler")
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(model_id, scheduler=scheduler, torch_dtype=torch.float16)
#使用する計算機を設定(GPUがない場合は"cpu"に変更)
pipe = pipe.to("cuda")
#初期画像を取得
init_image = Image.open("(img2imgで使用したい画像のパスを指定)")
init_image = init_image.convert("RGB")
init_image = init_image.resize((768, 512))
#画像生成の指示(呪文)
prompt = "A girl standing in beautiful nature."
#描画する回数を設定
num_images = 3
#イラスト生成
for i in range(num_images):
#推論実行
image = pipe(prompt, image=init_image).images[0]
#生成日時をファイル名にして保存
date = datetime.now().strftime("%Y%m%d_%H%M%S")
path = date + ".png"
image.save(path)\ Pythonを自宅で好きな時に学べる! /

実行結果
先ほどのPythonのコードを実行してイラストを生成してみます。
今回は画像の指示がイラストに反映されるかが目的となりますので、プロンプト(Prompt)はシンプルに「美しい自然の中に佇む一人の少女。」とします。英語に訳すと以下のようになります。
A girl standing in beautiful nature.また、指示に使う画像はフリー素材のサイトの風景の写真を用意しました。
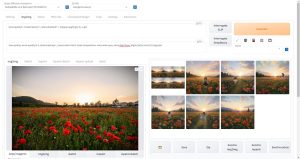
指示画像1
まず1つ目の画像はこちらです。
指示画像

紅葉が綺麗な森の中の道の写真です。
生成された画像
先ほどの画像を指定して、Pythonコードを実行したところ以下のようなイラストが生成されました。


指示画像のように日の光が差し込む森に佇む少女のイラストが生成されました。
指示画像2
2つ目の画像はこちらです。
指示画像

緑に囲まれたログハウスの写真です。
生成された画像
今回は指示画像を768×512の長方形にリサイズしてみました。
Pythonコードを実行したところ以下のイラストが生成されました。



Stable Diffusionのテクニックを効率よく学ぶには?
 カピパラのエンジニア
カピパラのエンジニアStable Diffusionを使ってみたいけど、ネットで調べた情報を試してもうまくいかない…
 猫のエンジニア
猫のエンジニアそんな時は、操作方法の説明が動画で見られるUdemyがおすすめだよ!
動画学習プラットフォームUdemyでは、画像生成AIで高品質なイラストを生成する方法や、AIの内部で使われているアルゴリズムについて学べる講座が用意されています。
Udemyは講座単体で購入できるため安価で(セール時1500円くらいから購入できます)、PCが無くてもスマホでいつでもどこでも手軽に学習できます。
Stable Diffusionに特化して学ぶ
Stable Diffusionに特化し、クラウドコンピューティングサービスPaperspaceでの環境構築方法から、モデルのマージ方法、ControlNetを使った構図のコントロールなど、中級者以上のレベルを目指したい方に最適な講座です。
画像生成AIの仕組みを学ぶ
画像生成AIの仕組みについて学びたい方には、以下の講座がおすすめです。
画像生成AIで使用される変分オートエンコーダやGANのアーキテクチャを理解することで、よりクオリティの高いイラストを生成することができます。
まとめ
今回はStable Diffusionで風景写真からimg2imgでイラストを生成する方法について解説しました。使用したモデルのAnything V4の出来が良いこともあり、写真の風景に近い美しいイラストを生成することができました。
ぜひ手持ちのお気に入りの写真で試してみてください。
また、Stable DiffusionのプロンプトをGPT-3を使って生成する方法についても以下の記事で解説していますので、あわせてご覧ください。

また、以下の記事で効率的にPythonのプログラミングスキルを学べるプログラミングスクールの選び方について解説しています。最近ではほとんどのスクールがオンラインで授業を受けられるようになり、仕事をしながらでも自宅で自分のペースで学習できるようになりました。
スキルアップや副業にぜひ活用してみてください。

スクールではなく、自分でPythonを習得したい方には、いつでもどこでも学べる動画学習プラットフォームのUdemyがおすすめです。
講座単位で購入できるため、スクールに比べ非常に安価(セール時1200円程度~)に学ぶことができます。私も受講しているおすすめの講座を以下の記事でまとめていますので、ぜひ参考にしてみてください。

それでは、また次の記事でお会いしましょう。













コメント