
今回はモデル共有サイトであるCivitaiで開催された、SDXLをベースとしたコンテストで入賞したStable Diffusionモデルを紹介します。
私自身も実際にこれらのモデルを使って生成してみた画像を掲載していますが、ハイクオリティなモデルばかりですので、ぜひ試してみてください。
- Civitai SDXLコンテストで入賞したモデル
- 各モデルで生成できるサンプルイメージ
- 各モデルの入手先
今回紹介するSDXLコンテスト入賞モデル以外のモデルについては、以下の記事で紹介しています。

また、当ブログのStable Diffusionに関する記事を以下のページでまとめていますので、あわせてご覧ください。

Stable Diffusionの導入方法から応用テクニックまでを動画を使って習得する方法についても以下のページで紹介しています。

Stable Diffusionとは
Stable Diffusion(ステーブル・ディフュージョン)は2022年8月に無償公開された描画AIです。ユーザーがテキストでキーワードを指定することで、それに応じた画像が自動生成される仕組みとなっています。
NVIDIAのGPUを搭載していれば、ユーザ自身でStable Diffusionをインストールし、ローカル環境で実行することも可能です。
(出典:wikipedia)
SDXLの超軽量GUI Fooocus
SDXLをベースとしたモデルは、非常に多くのVRAMを使用するため、ハイスペックなグラフィックボードを必要とします。
VRAMの容量の制約でSDXLが実行できる環境がない方には、最小4GBのVRAMでも動作する軽量GUIであるFooocusでSDXLベースモデルを使用することをお勧めします。

Stable DiffusionのWeb UI AUTOMATIC1111
AUTOMATIC1111はStable Diffusionをブラウザから利用するためのWebアプリケーションです。
AUTOMATIC1111を使用することで、プログラミングを一切必要とせずにStable Diffusionで画像生成を行うことが可能になります。
Web UI AUTOMATIC1111のインストール方法
Web UIであるAUTOMATIC1111を実行する環境は、ローカル環境(自宅のゲーミングPCなど)を使用するか、クラウドコンピューティングサービスを利用する2通りの方法があります。
以下の記事ではそれぞれの環境構築方法について詳し解説していますので、合わせてご覧ください。
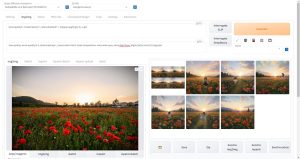
Crystal Clear XL
SDXL1.0をベースとしたCrystal Clear最新モデルです。フォトリアル、3Dグラフィックス、アニメ調と全ての領域で高い精度を発揮するモデルです。
日本人風の人物はあまり得意ではないよう(人物自体の描写は非常にリアルです)ですが、アート系のグラフィックスが特にクオリティの高い画像を生成できます。

配布先

DucHaiten-AIart-SDXL
SDXL1.0をベースの3Dグラフィックス、アニメ調画像でクオリティの高い画像を生成できるモデルです。今回私が生成したロボットの画像ですが、LoRAなしでここまでクオリティの高いロボットを描画することができます。
Unreal Engine(アンリアルエンジン)で作成されたゲームのようなグラフィックを生成したい方におすすめのモデルです。

配布先
Juggernaut XL
SDXL1.0をベースにしたフォトリアル系の人物に強いモデルで、非常にリアルな肌の質感などを再現できます。
プロンプト次第ではハイクオリティなアジア系の人物を描画することも可能です。

配布先
Anime Changeful XL
SDXL1.0をベースのアニメ調に特化したモデルです。
30000枚のアニメ調画像のデータセットと、Naive AIと同じアルゴリズムでトレーニングされたモデルで、2023年9月現在公開されているのはβバージョンのようですが、ハイクオリティなアニメ系画像を生成できます。
美少女だけではなくイケメンにも対応可能です。

配布先
Animagine XL
「Animagine XL」については以下の記事で解説しています。

CounterfeitXL
「CounterfeitXL」については以下の記事で解説しています。

モデルをWebUIで設定する方法
ここからは、入手したモデルファイルをWebUIで使用する方法について解説します。
モデルの設定方法
ダウンロードしたモデルをStable Diffusionのディレクトリに配置します。
実行環境により配置方法が異なりますので、ご利用の環境の項目を参考にしてください。
ローカル環境
ローカル環境で使用する場合は、ローカルPCの以下のディレクトリにモデルファイルを配置してください。
Google Colaboratory
Google Colaboratoryでモデルファイルを配置するディレクトリは以下となります。
Google Colaboratoryの場合は毎回モデルをダウンロードする必要がありますので、自動でダウンロードされるよう以下のコマンドを追加します。
!wget https://civitai.com/api/download/models/15980 -O /content/stable-diffusion-webui/models/Stable-diffusion/museV1_v1.safetensors詳細な追加方法については以下の記事で解説しています。
Paperspace
Paperspaceで使用する場合は、Paperspaceの仮想マシンの以下のディレクトリにモデルファイルを配置してください。
モデルの選択方法
モデルファイルを配置したら、WebUIのを起動します。
WebUIの画面左上のStable Diffusion checkpointと書かれている項目が、画像生成に使用されるモデルを指定する項目となります。
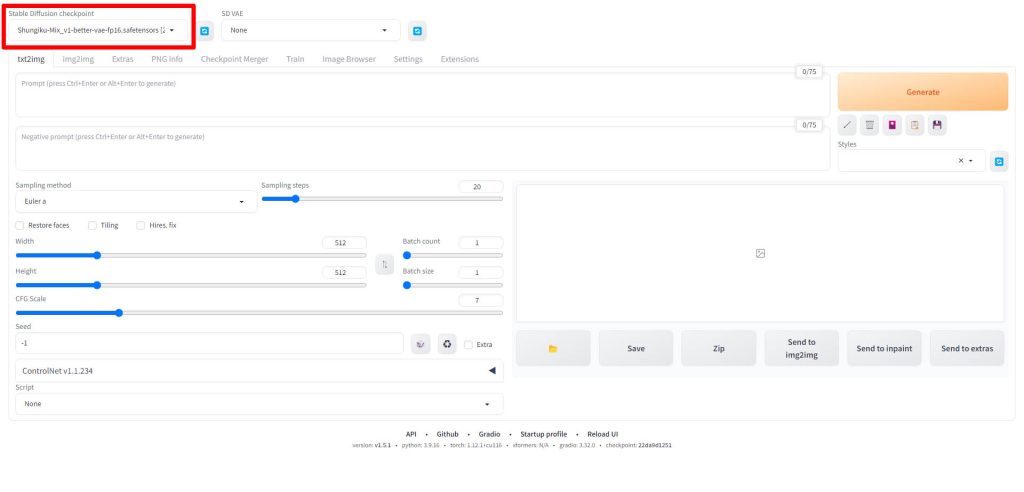
Stable Diffusion checkpointのドロップダウンリストをクリックすると、先ほどのモデルファイルを配置したディレクトリにあるファイルが一覧で表示されますので、使用したいモデルを選択してください。
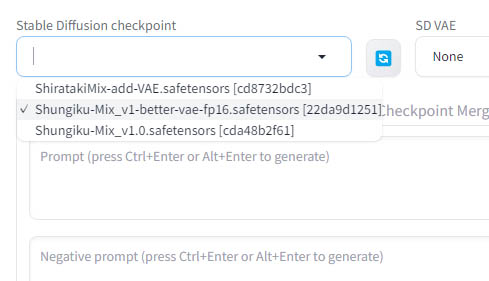
以上でモデルの設定は完了です。
Stable Diffusionのテクニックを効率よく学ぶには?
 カピパラのエンジニア
カピパラのエンジニアStable Diffusionを使ってみたいけど、ネットで調べた情報を試してもうまくいかない…
 猫のエンジニア
猫のエンジニアそんな時は、操作方法の説明が動画で見られるUdemyがおすすめだよ!
動画学習プラットフォームUdemyでは、画像生成AIで高品質なイラストを生成する方法や、AIの内部で使われているアルゴリズムについて学べる講座が用意されています。
Udemyは講座単体で購入できるため安価で(セール時1500円くらいから購入できます)、PCが無くてもスマホでいつでもどこでも手軽に学習できます。
Stable Diffusionに特化して学ぶ
Stable Diffusionに特化し、クラウドコンピューティングサービスPaperspaceでの環境構築方法から、モデルのマージ方法、ControlNetを使った構図のコントロールなど、中級者以上のレベルを目指したい方に最適な講座です。
画像生成AIの仕組みを学ぶ
画像生成AIの仕組みについて学びたい方には、以下の講座がおすすめです。
画像生成AIで使用される変分オートエンコーダやGANのアーキテクチャを理解することで、よりクオリティの高いイラストを生成することができます。
まとめ
今回はモデル共有サイトであるCivitaiで開催された、SDXLコンテストで入賞したモデルを紹介してみました。
ベースとなるSDXL1.0自体がまだリリースされて間もないため、どのモデルも発展途上とのことですが、既に非常にハイクオリティな画像を生成することができます。
今後のさらなるアップデートに期待しましょう。
また、以下の記事で効率的にPythonのプログラミングスキルを学べるプログラミングスクールの選び方について解説しています。最近ではほとんどのスクールがオンラインで授業を受けられるようになり、仕事をしながらでも自宅で自分のペースで学習できるようになりました。
スキルアップや副業にぜひ活用してみてください。

スクールではなく、自分でPythonを習得したい方には、いつでもどこでも学べる動画学習プラットフォームのUdemyがおすすめです。
講座単位で購入できるため、スクールに比べ非常に安価(セール時1200円程度~)に学ぶことができます。私も受講しているおすすめの講座を以下の記事でまとめていますので、ぜひ参考にしてみてください。

それでは、また次の記事でお会いしましょう。













コメント