
今回は2023年8月現在にリリースされている最新のモデルについて解説します。
Stable Diffusionの開発元であるStability AIから、SDXL1.0がリリースされてから、これをベースとしたカスタムモデルが続々とリリースされています。
SDXL1.0ベースのおすすめモデルを紹介しますので、ぜひ試してみてください。
今回紹介するモデル以外にも過去にリリースされたモデルを以下の記事で紹介しています。

また、当ブログのStable Diffusionに関する記事を以下のページでまとめていますので、あわせてご覧ください。

Stable Diffusionの導入方法から応用テクニックまでを動画を使って習得する方法についても以下のページで紹介しています。

Stable Diffusionとは
Stable Diffusion(ステーブル・ディフュージョン)は2022年8月に無償公開された描画AIです。ユーザーがテキストでキーワードを指定することで、それに応じた画像が自動生成される仕組みとなっています。
NVIDIAのGPUを搭載していれば、ユーザ自身でStable Diffusionをインストールし、ローカル環境で実行することも可能です。
(出典:wikipedia)
SDXLの超軽量GUI Fooocus
SDXLをベースとしたモデルは、非常に多くのVRAMを使用するため、ハイスペックなグラフィックボードを必要とします。
VRAMの容量の制約でSDXLが実行できる環境がない方には、最小4GBのVRAMでも動作する軽量GUIであるFooocusでSDXLベースモデルを使用することをお勧めします。

Stable DiffusionのWeb UI AUTOMATIC1111
AUTOMATIC1111はStable Diffusionをブラウザから利用するためのWebアプリケーションです。
AUTOMATIC1111を使用することで、プログラミングを一切必要とせずにStable Diffusionで画像生成を行うことが可能になります。
Web UI AUTOMATIC1111のインストール方法
Web UIであるAUTOMATIC1111を実行する環境は、ローカル環境(自宅のゲーミングPCなど)を使用するか、クラウドコンピューティングサービスを利用する2通りの方法があります。
以下の記事ではそれぞれの環境構築方法について詳し解説していますので、合わせてご覧ください。
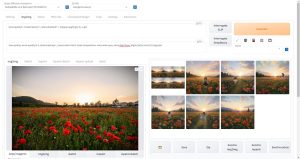
fuduki_mix
fuduki_mixは「yayoi_mix」「kisaragi_mix」の製作者、こたじろうさんが公開されているモデルです。SDXLをベースとしており、ハイクオリティなアジア人風の人物を描画できるフォトリアル系モデルです。

配布先


Animagine XL 1.0
Animagine XLはハイクオリティなアニメ調画像を使ってトレーニングされたモデルです。学習に用いられた画像は、1024×1024の高解像度なデータセットを使用しています。ベースモデルはSDXL1.0となります。

配布先


blue_pencil-XL
ぶるぺんさんが製作された、SDXLベースのアニメ調モデルモデルです。短いプロンプトで非常にクオリティの高いイラスを生成できます。Negative EmbeddingsはunaestheticXL (recommend v1)推奨です。

フォトリアル系も生成できるため、アニメ調の画像を生成したい場合には、プロンプトにanime girlなどのキーワードを入れてください。サンプルの画像は以下のプロンプトで生成しています。
配布先
プロンプトの作成が難しいと思われている方には、AIでプロンプトを自動生成するのがおすすめです。「StableDiffusionのプロンプト(呪文)を自然言語処理モデルGPT-3(Catchy)で自動生成する方法」で詳細を解説しています。
モデルをWebUIで設定する方法
ここからは、入手したモデルファイルをWebUIで使用する方法について解説します。
モデルの設定方法
ダウンロードしたモデルをStable Diffusionのディレクトリに配置します。
実行環境により配置方法が異なりますので、ご利用の環境の項目を参考にしてください。
ローカル環境
ローカル環境で使用する場合は、ローカルPCの以下のディレクトリにモデルファイルを配置してください。
Google Colaboratory
Google Colaboratoryでモデルファイルを配置するディレクトリは以下となります。
Google Colaboratoryの場合は毎回モデルをダウンロードする必要がありますので、自動でダウンロードされるよう以下のコマンドを追加します。
!wget https://civitai.com/api/download/models/15980 -O /content/stable-diffusion-webui/models/Stable-diffusion/museV1_v1.safetensors詳細な追加方法については以下の記事で解説しています。
Paperspace
Paperspaceで使用する場合は、Paperspaceの仮想マシンの以下のディレクトリにモデルファイルを配置してください。
モデルの選択方法
モデルファイルを配置したら、WebUIのを起動します。
WebUIの画面左上のStable Diffusion checkpointと書かれている項目が、画像生成に使用されるモデルを指定する項目となります。
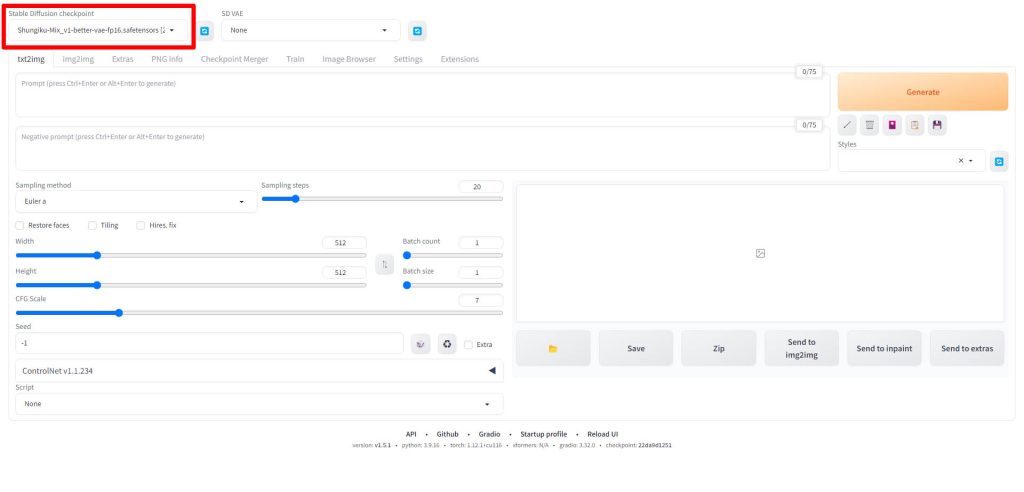
Stable Diffusion checkpointのドロップダウンリストをクリックすると、先ほどのモデルファイルを配置したディレクトリにあるファイルが一覧で表示されますので、使用したいモデルを選択してください。
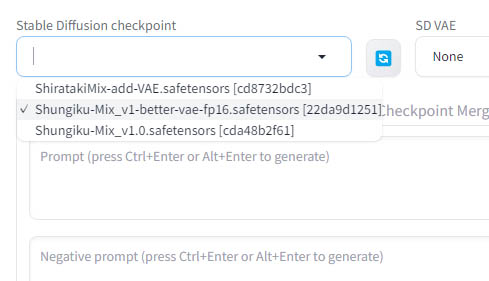
以上でモデルの設定は完了です。
Stable Diffusionのテクニックを効率よく学ぶには?
 カピパラのエンジニア
カピパラのエンジニアStable Diffusionを使ってみたいけど、ネットで調べた情報を試してもうまくいかない…
 猫のエンジニア
猫のエンジニアそんな時は、操作方法の説明が動画で見られるUdemyがおすすめだよ!
動画学習プラットフォームUdemyでは、画像生成AIで高品質なイラストを生成する方法や、AIの内部で使われているアルゴリズムについて学べる講座が用意されています。
Udemyは講座単体で購入できるため安価で(セール時1500円くらいから購入できます)、PCが無くてもスマホでいつでもどこでも手軽に学習できます。
Stable Diffusionに特化して学ぶ
Stable Diffusionに特化し、クラウドコンピューティングサービスPaperspaceでの環境構築方法から、モデルのマージ方法、ControlNetを使った構図のコントロールなど、中級者以上のレベルを目指したい方に最適な講座です。
画像生成AIの仕組みを学ぶ
画像生成AIの仕組みについて学びたい方には、以下の講座がおすすめです。
画像生成AIで使用される変分オートエンコーダやGANのアーキテクチャを理解することで、よりクオリティの高いイラストを生成することができます。
まとめ
今回はStability AIからリリースされたばかりのSDXLをベースとした最新モデルを紹介しました。以前のStable Diffusion 2.1と比較しても、短いプロンプトで非常にクオリティの高い画像が生成できるようになっています。
また、今回紹介した以外のモデルについても、以下の記事で紹介しています。
また、以下の記事で効率的にPythonのプログラミングスキルを学べるプログラミングスクールの選び方について解説しています。最近ではほとんどのスクールがオンラインで授業を受けられるようになり、仕事をしながらでも自宅で自分のペースで学習できるようになりました。
スキルアップや副業にぜひ活用してみてください。

スクールではなく、自分でPythonを習得したい方には、いつでもどこでも学べる動画学習プラットフォームのUdemyがおすすめです。
講座単位で購入できるため、スクールに比べ非常に安価(セール時1200円程度~)に学ぶことができます。私も受講しているおすすめの講座を以下の記事でまとめていますので、ぜひ参考にしてみてください。

それでは、また次の記事でお会いしましょう。













コメント