
今回は画像生成AIであるStable Diffusionのローカル環境を構築する方法について解説します。
Stable Diffusionのローカル環境構築には、初期投資(高性能なPCなど)が必要になりますが、一度構築してしまえば、制約無く存分に画像生成を楽しむことができます。
今回はハードウェアを用意からインストール、拡張機能までを紹介しますので、参考にしてみてください。
また、当ブログのStable Diffusionに関する記事を以下のページでまとめていますので、あわせてご覧ください。

Stable Diffusionの導入方法から応用テクニックまでを動画を使って習得する方法についても以下のページで紹介しています。

ハードウェア(グラフィックボード)を用意する
Stable Diffusionをローカル環境で実行するためには、画像生成やモデルの追加に必要な膨大な数値計算処理を高速に実行するGPUを搭載したグラフィックボードが必要です。
お使いのPCに実装するグラフィックボードの性能によって、画像生成にかかる時間や、最大画像サイズが変わってきますので、グラフィックボードの選定は重要なポイントになります。
Stable Diffusionを実行するのに必要なグラフィックボードの選定基準について、以下の記事で解説しています。

Stable DiffusionのWeb UI(AUTOMATIC1111)をインストールする
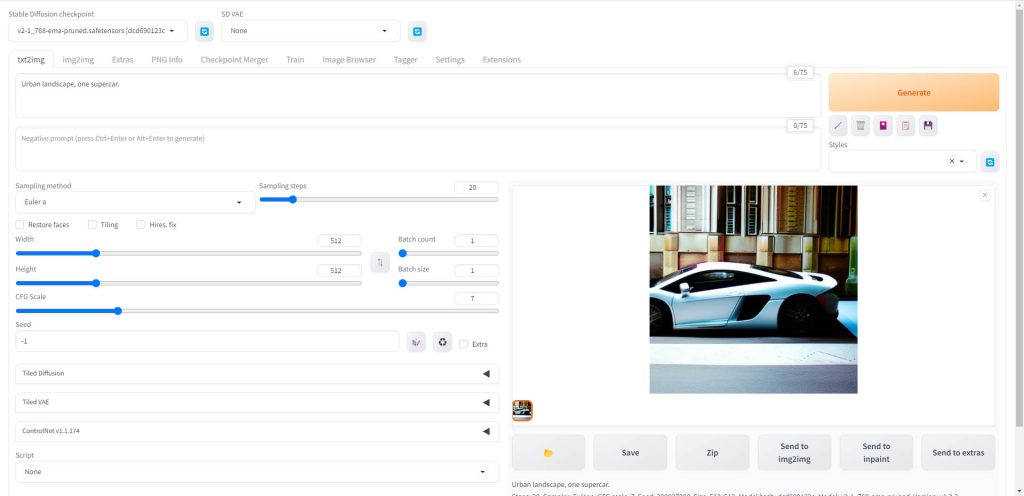
Stable Diffusionを実行するハードウェアを用意したら、次はそのPCにStable Diffusionをインストールします。
Stable Diffusionはオープンソースのプロジェクトで、ソースコードが無料で公開されているのですが、それをそのまま使うには、高度なプログラミングスキルが必要となります。
そこで、AUTOMATIC氏が公開しているWeb UI、AUTOMATIC1111というアプリケーションを使用します。
AUTOMATIC1111をブラウザ上で使用できるグラフィカルユーザーインタフェース(GUI)となっており、プログラミングに関する知識が一切なくてもStable Diffusionを利用できます。
AUTOMATIC1111のインストールから、基本的な使用方法までを以下の記事で解説しています。
PCに直接インストールする
PCに直接Stable Diffusionをインストールする手順を以下の記事で解説しています。

Dockerを使ってインストールする
Dockerを使ってインストールする方法を以下の記事で解説しています。既にDockerを導入済みの方には、数行のコマンドで実行できるためおすすめです。


Stable Diffusion 超軽量GUI fooocusをインストールする
Stable Diffusionの開発元であるStability AIからリリースされた公式モデルSDXL1.0とSDXLベースのカスタムモデルは非常にクオリティの高い画像が生成できる反面、VRAM16GBのメモリを搭載したグラフィックボードでも動作しなことがあるほど高性能な実行環境が必要とされます。
この問題を解決するため、ControlNetの開発者であるlllyasviel氏によってStable Diffusionの超軽量GUI、fooocusが開発されました。
fooocusはVRAM4GBというロースペック環境でも動作するよう設計されているため、自宅のゲーミングPCなどで手軽にSDXLベースのモデルを使用することができます。
fooocusのインストールから使用方法までを、以下の記事で解説しています。

モデルを入手する
Stable Diffusionを利用できる環境が整ったら、次は画像生成に使用するモデルを用意します。
画像AIで画像を生成するには、事前に大量の画像をデータセットとして学習させたモデルが必要となります。そしてこのモデルがどのような画像を学習させているかによって、同じ条件でも出力される画像の内容が大きく変わります。
Stable Diffusionで使用できるおすすめのモデルを、フォトリアル系、アニメ系それぞれについて、以下の記事で紹介しています。


プロンプト(呪文)を作成する
Stable Diffusionの実行環境とモデルを用意したら、いよいよ画像の内容を指示するためのプロンプト(呪文)を作成して画像生成を実行します。
画像を指示するプロンプトについても、フォトリアル系とアニメ系でテクニックがことなります。
それぞれのプロンプト生成の方法について、以下の記事で解説しています。

また、大規模言語モデルを使ってプロンプトを自動生成する方法についても、以下の記事で解説しています。

拡張機能ControlNetを利用する
画像生成AIでは、ランダム性が高く、出力される画像をプロンプトとモデルだけでコントロールすることは困難です。
そんな時に役立つのが、Stable Diffusionの拡張機能であるControlNetです。
ControlNetでは、他の機械学習モデルなどの組み合わせることにより、生成される画像の構図やキャラクターのポーズなどを細かく制御することが可能です。
ControlNetの機能と使い方を、以下の記事で解説しています。

LoRAでモデルを追加学習する
先ほど紹介したControlNetによって、生成される画像をかなり細部までコントロールすることができます。
しかし、ControlNetでもお気に入りのキャラクターや衣装などを固定して、ストーリー性のある画像を何枚も出力する、といったようなことを実現することはできません。
キャラクターや衣装を固定して画像生成を実行したい場合は、LoRAという追加学習の仕組みを使って、モデルをチューニングすることで実現することができます。
LoRAの使い方について、以下の記事で解説しています。

Stable Diffusionで生成される画像のクオリティを上げる
動画学習プラットフォームUdemyでは、画像生成AIで高品質なイラストを生成する方法や、AIの内部で使われているアルゴリズムについて学べる講座が用意されています。
Udemyは講座単体で購入できるため安価で(セール時1500円くらいから購入できます)、PCが無くてもスマホでいつでもどこでも手軽に学習できます。
画像生成AIの使い方を学ぶ
Stable DiffusionやMidjourneyなどを使ったAIアート全般について勉強したい方には、以下の講座がおすすめです。
Stable Diffusionに特化して学ぶ
Stable Diffusionに特化し、クラウドコンピューティングサービスPaperspaceでの環境構築方法から、モデルのマージ方法、ControlNetを使った構図のコントロールなど、中級者以上のレベルを目指したい方に最適な講座です。
画像生成AIの仕組みを学ぶ
画像生成AIの仕組みについて学びたい方には、以下の講座がおすすめです。
画像生成AIで使用される変分オートエンコーダやGANのアーキテクチャを理解することで、よりクオリティの高いイラストを生成することができます。
まとめ
今回はStable Diffusionのローカル環境について解説しました。
クラウドコンピューティング環境とは異なり、ローカル環境ではいつでも好きな時に好きなだけ画像生成を行うことができる理想的な環境となりますので、ぜひ挑戦してみてください。
また、以下の記事で効率的にPythonのプログラミングスキルを学べるプログラミングスクールの選び方について解説しています。最近ではほとんどのスクールがオンラインで授業を受けられるようになり、仕事をしながらでも自宅で自分のペースで学習できるようになりました。
スキルアップや副業にぜひ活用してみてください。

スクールではなく、自分でPythonを習得したい方には、いつでもどこでも学べる動画学習プラットフォームのUdemyがおすすめです。
講座単位で購入できるため、スクールに比べ非常に安価(セール時1200円程度~)に学ぶことができます。私も受講しているおすすめの講座を以下の記事でまとめていますので、ぜひ参考にしてみてください。

それでは、また次の記事でお会いしましょう。













コメント