
Stable Diffusionは、画像生成の世界を革命的に変える可能性を秘めたAI技術です。しかし、その潜在的な力を最大限に引き出すには、その使い方を理解し、適切なツールを活用する必要があります。
今回はStable Diffusion初心者の方向けに、インストールから高品質化のテクニックまで、順を追って解説します。これからStable Diffusionを学びたいと考えている方はぜひ挑戦してみてください。
また、当ブログのStable Diffusionに関する記事を以下のページでまとめていますので、あわせてご覧ください。

Stable Diffusionの導入方法から応用テクニックまでを動画を使って習得する方法についても以下のページで紹介しています。

Stable Diffusionとは
Stable Diffusion(ステーブル・ディフュージョン)は2022年8月に無償公開された描画AIです。ユーザーがテキストでキーワードを指定することで、それに応じた画像が自動生成される仕組みとなっています。
NVIDIAのGPUを搭載していれば、ユーザ自身でStable Diffusionをインストールし、ローカル環境で実行することも可能です。
(出典:wikipedia)


Web UI AUTOMATIC1111と実行環境の選び方とインストール
Stable Diffusionを始めるにあたって、まずは実行環境を決める必要があります。
midjourneyのようなWebサービスとして提供されている画像AIとはことなり、Stable Diffusionはオープンソースのプロジェクトとして、ソースコードが無料で公開されています。
そのソースコードを自分で用意した環境で実行することで画像生成を行うことができます。
AUTOMATIC1111の環境を選ぶ
Stable Diffusionをブラウザから利用できるAUTOMATIC1111というWeb UIが公開されています。このWeb UIを使って利用するのが最も主流の方法となります。
Stable Diffusionの実行環境の選び方と、AUTOMATIC1111のインストール方法を以下の記事で解説しています。
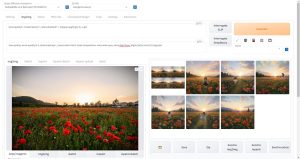
Stable Diffusionを実行するハードウェア
Stable Diffusionを自宅のPCで使用したい場合、グラフィックボードの性能に生成速度や画像サイズが大きく影響を受けます。
費用と要求スペックに応じて、おすすめのグラフィックボードを以下の記事で解説しています。


Stable Diffusionのモデルを選ぶ
Stable DiffusionのWebUI、AUTOMATIC1111をインストールしたら、次は画像生成に必要な学習済みモデルを入手します。Stable Diffusionでは、使用する学習済みモデルの選択によって、出力される画像のクオリティが大きく異なります。
モデルの入手方法
フォトリアル系のモデルでは、実写に近いリアルな風景や人物を生成することができます。

一方で、アニメ系のモデルでは、アニメ風のキャラクターや背景を生成することができます。

これらのモデルは、様々な用途に特化しており、ユーザーはお気に入りのモデルを選んで使用することができます。
VAEの設定
また、学習済みモデルと合わせて、VAE(変分オートエンコーダ)が指定されているケースがあります。(詳細は、利用したいモデルの配布サイトの解説を参照してください)
AUTOMATIC1111 WebUI上でVAEを設定する方法を、以下の記事で解説しています。

Stable Diffusionで使用するプロンプト(呪文)
Stable Diffusionでは、ユーザーがテキストでキーワードを指定することで、それに応じた画像が自動生成されます。このプロセスで重要なのが、画像生成の指示となる「プロンプト」です。
プロンプトの作成方法
プロンプトは、画像のクオリティを大きく左右するため、その作成は非常に重要です。フォトリアル系やアニメ系など、使用するモデルに合わせて、特化したプロンプトを作成する必要があります。
以下の記事では、フォトリアル系、アニメ系それぞれのプロンプトの作成方法について解説しています。

LLMを使ったプロンプトの自動生成
また、自然言語モデルを使用してプロンプトを自動生成する方法もあります。これにより効率的に高品質な画像を生成することができます。

またLLMで生成したプロンプトのサンプルを以下の記事で公開しています。

Stable Diffusionのアップスケーリング:高解像度画像生成の秘訣
Stable Diffusionで生成される画像を高画質化するテクニックとしてUpscaler(アップスケーラ)を使用する方法があります。画像のサイズを拡大するだけでなく、書き込み量を増やして高精細な画像を生成することが可能です。
Stable Diffusionには、様々なUpscalerが用意されており、それぞれに特徴があります。
例として、hires.fixは小さいサイズの画像をアップスケールして高精細な画像を作成する機能であり、ControlNet tile_resampleは元の画像の絵柄を保ちながら書き込み量を増やす機能です。
用途に応じたアップスケーラの使用方法を、以下の記事で解説しています。

これらのUpscalerを活用することで、Stable Diffusionで生成される画像の品質を大幅に向上させることができます。
上級編
ここからは、上級者向けのテクニックとして、生成される画像にオリジナリティを出すための方法について解説します。
オリジナルのマージモデルを作成する
2つ以上のモデルを組み合わせてオリジナルのマージモデルを作成することが可能です。
マージする際に使用するモデルについては、モデルの配布元のライセンスをよく確認してください。(リークモデルなど、リスクのあるモデルが混入しないようご注意ください)
マージモデルの作成方法は、以下の記事で解説しています。

LoRAでキャラクターやコスチュームを追加学習する
特定のキャラクタや服装などを、LoRA(Low-Rank Adaptation)という仕組みを使って、追加学習させることで、キャラクタや服装を固定して様々な画像を生成することが可能です。
LoRAファイルの作成と使用方法を、以下の記事で解説しています。

Stable Diffusionのテクニックを効率よく学ぶには?
 カピパラのエンジニア
カピパラのエンジニアStable Diffusionを使ってみたいけど、ネットで調べた情報を試してもうまくいかない…
 猫のエンジニア
猫のエンジニアそんな時は、操作方法の説明が動画で見られるUdemyがおすすめだよ!
動画学習プラットフォームUdemyでは、画像生成AIで高品質なイラストを生成する方法や、AIの内部で使われているアルゴリズムについて学べる講座が用意されています。
Udemyは講座単体で購入できるため安価で(セール時1500円くらいから購入できます)、PCが無くてもスマホでいつでもどこでも手軽に学習できます。
Stable Diffusionに特化して学ぶ
Stable Diffusionに特化し、クラウドコンピューティングサービスPaperspaceでの環境構築方法から、モデルのマージ方法、ControlNetを使った構図のコントロールなど、中級者以上のレベルを目指したい方に最適な講座です。
画像生成AIの仕組みを学ぶ
画像生成AIの仕組みについて学びたい方には、以下の講座がおすすめです。
画像生成AIで使用される変分オートエンコーダやGANのアーキテクチャを理解することで、よりクオリティの高いイラストを生成することができます。
まとめ
Stable Diffusionは、テキスト入力に基づいて高品質な画像を生成する強力なAIです。この記事では、Stable Diffusionのインストール方法、基本的な利用方法、およびアップスケーリング技術に焦点を当てて解説しました。
これらの知識を活用することで、初学者でもStable Diffusionを使って驚くほどの画像を生成することができます。ぜひ活用してみてください。
また、以下の記事で効率的にPythonのプログラミングスキルを学べるプログラミングスクールの選び方について解説しています。最近ではほとんどのスクールがオンラインで授業を受けられるようになり、仕事をしながらでも自宅で自分のペースで学習できるようになりました。
スキルアップや副業にぜひ活用してみてください。

スクールではなく、自分でPythonを習得したい方には、いつでもどこでも学べる動画学習プラットフォームのUdemyがおすすめです。
講座単位で購入できるため、スクールに比べ非常に安価(セール時1200円程度~)に学ぶことができます。私も受講しているおすすめの講座を以下の記事でまとめていますので、ぜひ参考にしてみてください。

それでは、また次の記事でお会いしましょう。













コメント