
今回はChatGPTを使って動画の内容を要約するPythonのプログラムの作成方法について解説します。
ネットでたくさんの動画コンテンツにアクセスできることになった反面、情報の取捨選択が難しくなっています。そこで、Pythonのプログラムで自動的に動画の音声データを抽出し、要約することで効率的に情報を得る方法を提案します。
FFmpegとOpenAIのWhisper、ChatGPTを組み合わせることにより、手間をかけずに動画から重要な情報を抽出できますので、ぜひ活用してみてください。
また、当ブログ内のChatGPTについての記事を以下のページでまとめていますので、あわせてご覧ください。
ChatGPTとは
ChatGPTは、OpenAIが提供する自然言語生成モデルです。GPT(Generative Pre-training Transformer)と呼ばれるモデルのアーキテクチャを採用しています。
GPTは、Transformerと呼ばれるニューラルネットワークを使用して、文書や言語処理タスクでのテキスト生成を行うモデルです。GPTは、大量のテキストデータを学習し、そのデータをもとに新しい文章を生成することができます。
ChatGPTは、GPTをもとにしたモデルであり、対話型システムやチャットボットなどで使われることを想定して開発されています。対話を続けることができるようになっており、ユーザーが入力するテキストに対して、自然で返答ができるようになっています。
OpenAI APIキーの取得
ChatGPTと後程、紹介するWhisperを使用するためには、OpenAIのAPIキーを取得する必要があります。取得の手順については以下の記事で解説しています。

音声認識システムWhisper
今回、動画から抽出した音声データを文字データに変換するために、OpenAIが提供しているWhisperのAPIを使用します。Whisperの使い方は以下の記事で解説しています。


FFmpegとは
FFmpegは、オープンソースで開発されているマルチメディアフレームワークで、動画や音声の変換、編集、ストリーミングなどの機能を提供しています。C言語で書かれており、様々なプラットフォーム(Windows、macOS、Linuxなど)で利用できます。高速で効率的な処理が特徴で、多くのアプリケーションやウェブサービスで利用されています。
FFmpegは以下の主要なコンポーネントから構成されています。
- ffmpegコマンドラインツール:動画や音声の変換、編集、再エンコード、フィルタリングなどのタスクを実行するためのコマンドラインインターフェースです。
- ffplay:シンプルなマルチメディアプレイヤーで、SDLを使用して動画や音声を再生できます。
- ffprobe:マルチメディアファイルの情報を取得するためのツールです。ストリーム情報、コーデック、メタデータなどを調べることができます。
今回はこの中で「ffmpeg」を使用します。
Pythonでは、ffmpeg-pythonというライブラリを使用することで、FFmpegの機能を簡単に利用できます。このライブラリは、FFmpegのコマンドラインツールの機能をPythonで使いやすくラップしています。
ffmpeg本体のインストール
ここからはffmpegをインストールする手順について解説します。
Windowsでのインストール
Windowsでは、ffmpegの実行ファイル(ffmpeg.exe)をダウンロードし、パスを設定することで利用可能になります。
ダウンロード
FFmpegのリポジトリは以下となります。

GitHubのページにアクセスしたら、画面右側の「Releases」をクリックし、ダウンロードページへ移動します。
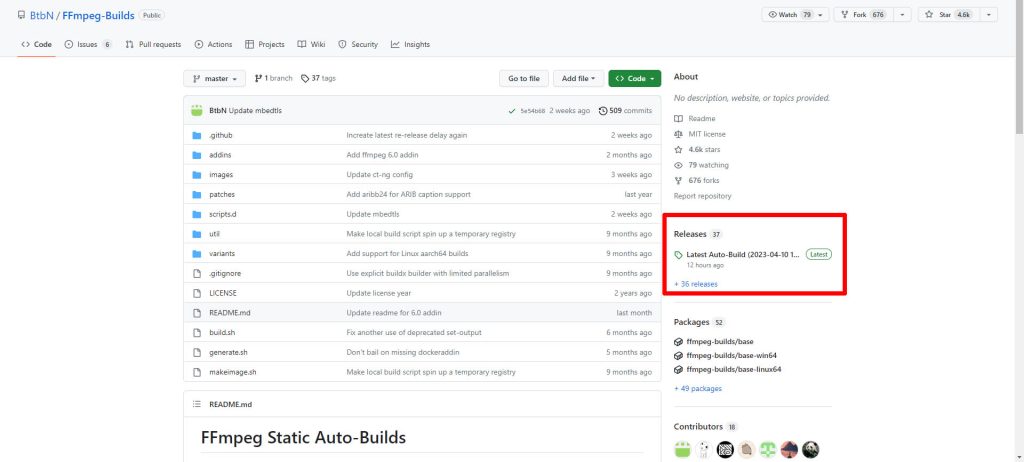
Windows用のGPLライセンスのものを使用しますので、「fmpeg-master-latest-win64-gpl.zip」をダウンロードします。
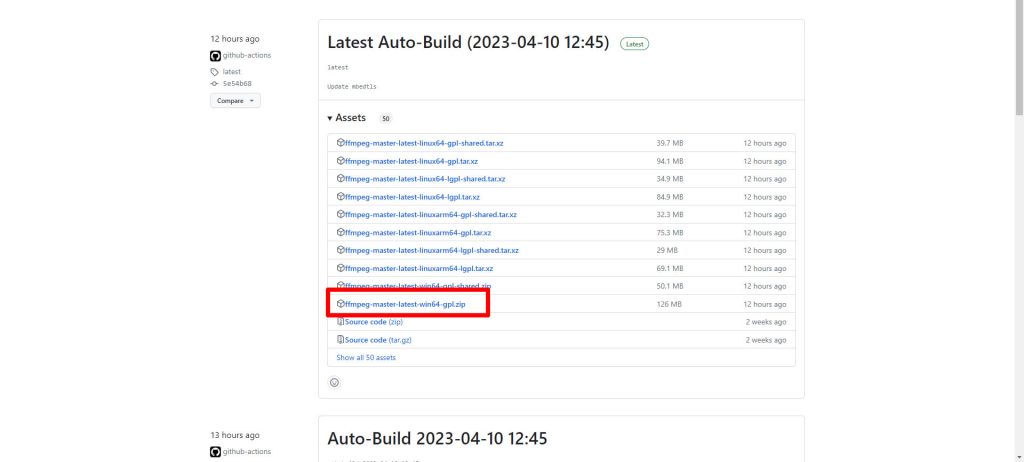
ダウンロードしたファイルを解凍後、以下のexeファイルを使用します。
(解凍したディレクトリ)\ffmpeg-master-latest-win64-gpl\bin\ffmpeg.exePATHを設定する
先ほどダウンロードした「ffmpeg.exe」のパスを設定します。
Windowsの「コントロール パネル」→「システムとセキュリティ」→「システム」をクリックします。
以下の画面が表示されたら、「システムの詳細設定」をクリックします。
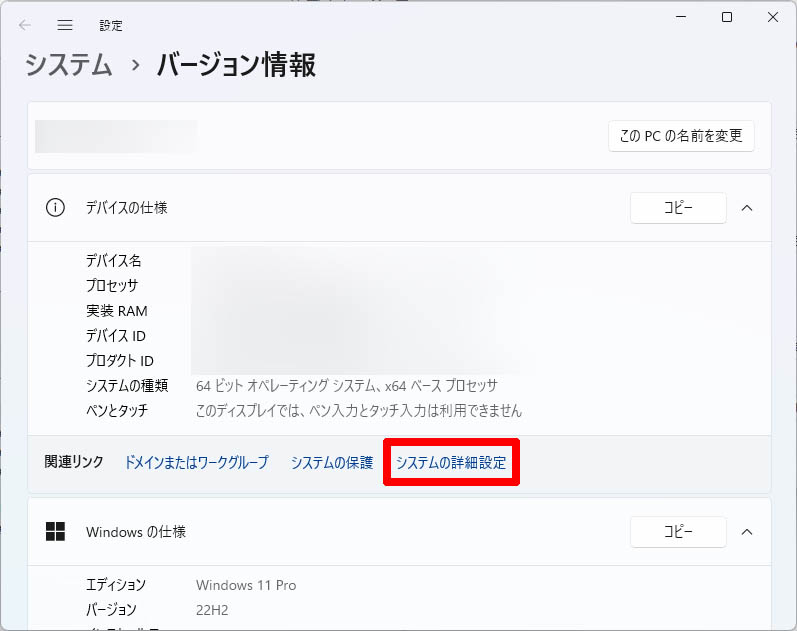
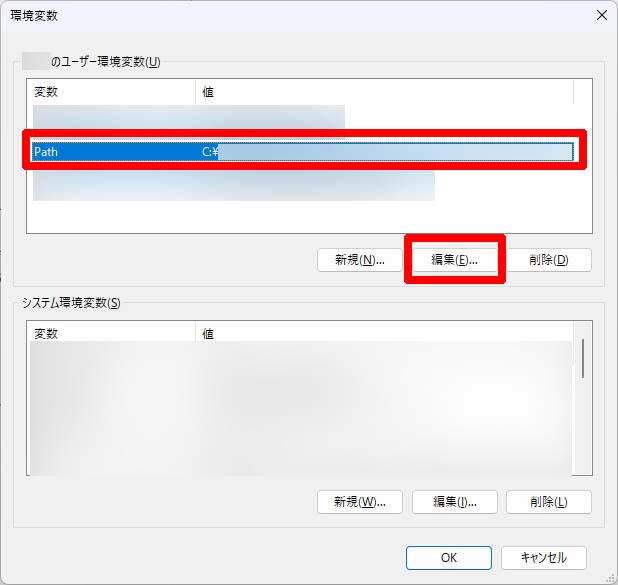
システムのプロパティで「環境変数」をクリックします。
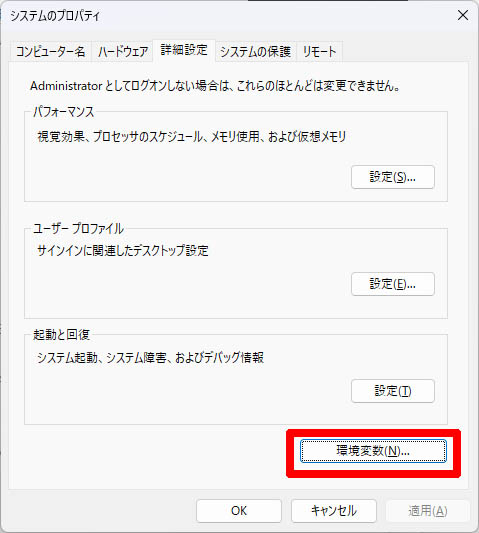
「○○ユーザーの環境変数」の「Path」を選択した状態で「編集」をクリックし、「ffmpeg.exe」が配置されているディレクトリのパスを設定してください。
Linuxでのインストール
コマンドプロンプトで以下のコマンドを実行してください。
sudo apt install ffmpegffmpeg-pythonのインストール
続いてPythonのプログラムからffmpegを利用するためのライブラリをインストールします。
コマンドプロンプトで以下のコマンドを設定してください。
pip install ffmpeg-python以下のようなメッセージが表示されたらインストール完了です。
Successfully built future
Installing collected packages: future, ffmpeg-python
Successfully installed ffmpeg-python-0.2.0 future-0.18.3
OpenAIのライブラリのインストール
必要なライブラリをインストールします。コマンドプロンプトで以下のコマンドを実行してください。
pip install openai作成したPythonコード
このプログラムは、FFmpegを使って動画ファイルから音声データを抽出し、OpenAIのWhisperとChatGPTのAPIを使って、音声データを文字列データに変換し、要約する処理を行います。
Pythonコード解説
FFmpegで動画ファイルから音声を抽出
まず、ffmpeg ライブラリを使って動画ファイルから音声データを抽出します。ffmpeg.input() で動画ファイルを読み込み、ffmpeg.output() で音声ファイルを出力します。最後に ffmpeg.run() で実行します。
#抽出する動画ファイル
stream = ffmpeg.input(MOV_FILE_PATH)
#出力する音声ファイル
stream = ffmpeg.output(stream, AUDIO_FILE_PATH)
#抽出実行
ffmpeg.run(stream)Whisperで音声データを文字列データに変換
抽出した音声ファイルを open で開き、openai.Audio.transcribe() 関数を使ってWhisperによる音声から文字起こしを行います。
#動画、オーディオファイルを開く
audio_file = open(AUDIO_FILE_PATH, "rb")
#Whisperで音声から文字お越し
transcript = openai.Audio.transcribe("whisper-1", audio_file)ChatGPTで要約を作成
要約するためのプロンプトを作成し、openai.ChatCompletion.create() 関数を使ってChatGPTに要約処理を依頼します。返り値の response["choices"][0]["message"]["content"] に要約結果が格納されます。
#ChatGPTプロンプトを作成
prompt = PROMPT_BASE + transcript.text
#推論を実行
response = openai.ChatCompletion.create(
model=GPT_MODEL,
messages=[
{"role": "user", "content": prompt}
]
)
#ChatGPTの回答を出力
print(response["choices"][0]["message"]["content"])全体のソースコード
作成したPythonの全体のソースコードは以下の通りです。
import openai
import ffmpeg
openai.api_key = "(ここにOpenAIのAPIキーを設定)"
MOV_FILE_PATH = "(ここに動画のパスを設定)"
AUDIO_FILE_PATH = "extract_audio.mp3"
PROMPT_BASE = "次の文章を200字程度で要約してください。"
GPT_MODEL ="gpt-3.5-turbo"
### ffmpegで動画ファイルから音声を抽出 ###
#抽出する動画ファイル
stream = ffmpeg.input(MOV_FILE_PATH)
#出力する音声ファイル
stream = ffmpeg.output(stream, AUDIO_FILE_PATH)
#抽出実行
ffmpeg.run(stream)
### Whisperで文字列データに変換 ###
#動画、オーディオファイルを開く
audio_file = open(AUDIO_FILE_PATH, "rb")
#Whisperで音声から文字お越し
transcript = openai.Audio.transcribe("whisper-1", audio_file)
### ChatGPTで要約を作成 ###
#ChatGPTプロンプトを作成
prompt = PROMPT_BASE + transcript.text
#推論を実行
response = openai.ChatCompletion.create(
model=GPT_MODEL,
messages=[
{"role": "user", "content": prompt}
]
)
#ChatGPTの回答を出力
print(response["choices"][0]["message"]["content"])

実行結果
先ほどのPythonコードで実際に動画ファイルを読み込んで、要約文が生成できるかを確認します。
要約対象となる動画
今回は要約の対象となる動画の題材として、私が以前YouTubeに公開したゲーム実況動画を用意しました。こちらの動画ファイルを先ほどのプログラムで読み込んで要約を作成します。
出力結果
ChatGPTで要約した結果は以下の通りです。
動画の内容が正しく要約されていることを確認できました。
\ Pythonを自宅で好きな時に学べる! /
まとめ
今回は、動画の音声データを抽出し、文字起こし、要約文を生成するプログラムの作成方法を解説しました。このプログラムを使うことで、短時間で動画コンテンツの情報をキャッチし、効率的に知識を得ることができます。ぜひお試しください。
また、以下の記事で効率的にPythonのプログラミングスキルを学べるプログラミングスクールの選び方について解説しています。最近ではほとんどのスクールがオンラインで授業を受けられるようになり、仕事をしながらでも自宅で自分のペースで学習できるようになりました。
スキルアップや副業にぜひ活用してみてください。

スクールではなく、自分でPythonを習得したい方には、いつでもどこでも学べる動画学習プラットフォームのUdemyがおすすめです。
講座単位で購入できるため、スクールに比べ非常に安価(セール時1200円程度~)に学ぶことができます。私も受講しているおすすめの講座を以下の記事でまとめていますので、ぜひ参考にしてみてください。

それでは、また次の記事でお会いしましょう。












コメント