
今回はStable Diffusionで画像を生成する際に、ControlNetでイラストの構図を指定して実行する方法について解説します。
ControlNetはStable DiffusionのWebUIであるAUTOMATIC1111の拡張機能として簡単に使用でき、生成する画像のキャラクターのポーズや構図を自由にコントロールできます。ぜひ活用してみてください。
また、当ブログのStable Diffusionに関する記事を以下のページでまとめていますので、あわせてご覧ください。

Stable Diffusionの導入方法から応用テクニックまでを動画を使って習得する方法についても以下のページで紹介しています。

Stable Diffusionとは
Stable Diffusion(ステーブル・ディフュージョン)は2022年8月に無償公開された描画AIです。ユーザーがテキストでキーワードを指定することで、それに応じた画像が自動生成される仕組みとなっています。
NVIDIAのGPUを搭載していれば、ユーザ自身でStable Diffusionをインストールし、ローカル環境で実行することも可能です。
(出典:wikipedia)
Stable DiffusionのWeb UI AUTOMATIC1111
AUTOMATIC1111はStable Diffusionをブラウザから利用するためのWebアプリケーションです。
AUTOMATIC1111を使用することで、プログラミングを一切必要とせずにStable Diffusionで画像生成を行うことが可能になります。
Web UI AUTOMATIC1111のインストール方法
Web UIであるAUTOMATIC1111を実行する環境は、ローカル環境(自宅のゲーミングPCなど)を使用するか、クラウドコンピューティングサービスを利用する2通りの方法があります。
以下の記事ではそれぞれの環境構築方法について詳し解説していますので、合わせてご覧ください。
ControlNetのインストール
AUTOMATIC1111の環境を構築したら、ControlNetを拡張機能としてインストールします。
具体的なインストール手順は以下の記事で解説しています。



ControlNetで使用するポーズデータを作成する
AUTOMATIC1111とControlNetをセットアップしたら、実際にControlNetでキャラクターに取らせたいポーズをしていするためのポーズデータを作成します。
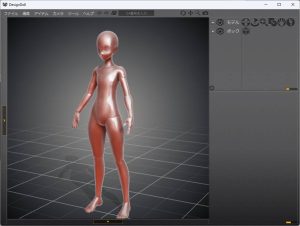
デザインドールで作成する
ポーズデータの作成には、無料で使えるデザインドール(DESIGN DOLL)というツールを使用します。
デザインドールのインストールと使い方を以下の記事で解説していますので、事前にポーズデータを作成しておいてください。
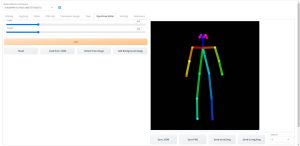
Openpose Editorで作成する
Openpose EditorというAUTOMATIC1111のUIを拡張するツールが公開されました。
Openpose Editorを使用することで、外部ツールを使うことなくAUTOMATIC1111のUI内でポーズデータを作成することができるようになりました。
Openpose Editorのインストール方法と使い方は、以下のページで解説しています。
OpenOpseを使ってイラストを生成
AUTOMATIC1111とControlNetをセットアップし、ポーズデータを用意したら実際にControlNetを使って画像生成をしていきます。
AUTOMATIC1111を起動したら以下のControlNetの項目をクリックして展開します。
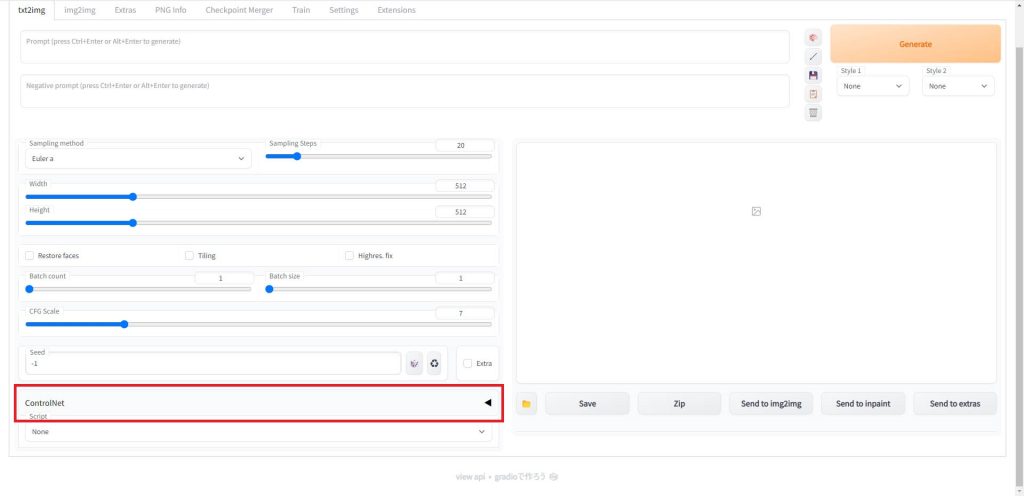
ControlNetの項目を展開すると、構図の指定に使用する画像を読み込む項目がありますので、この赤枠のエリアにポーズファイルをドラッグ&ドロップしてください。
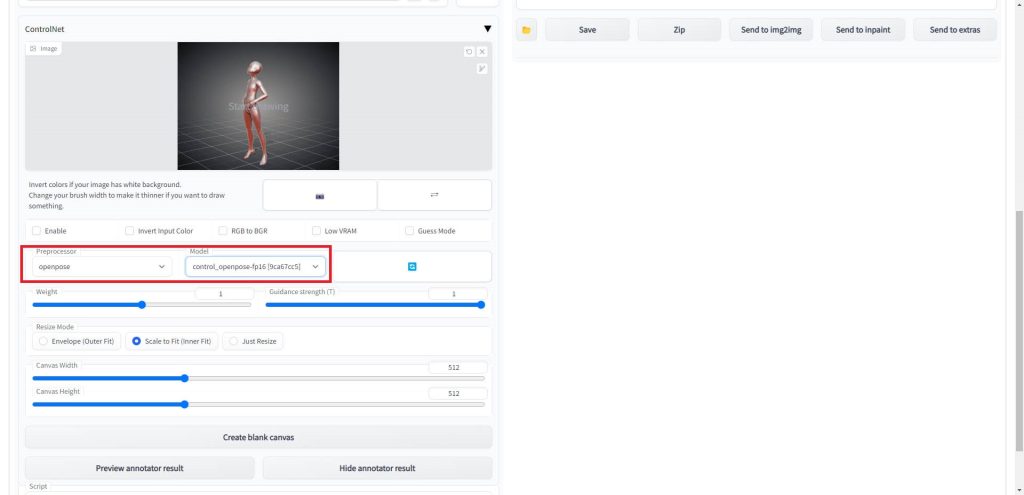
読み込みが完了すると以下のように、ポーズデータの画像が表示されます。
赤枠の部分の「Preprocessor」の項目で「openpose」を選択し、隣の「model」の項目で「control_openpose-fp16.safetensors」を選択します。
「Enable」にチェックを入れ、画像サイズを先ほど読み込んだポーズデータの画像サイズに設定します。
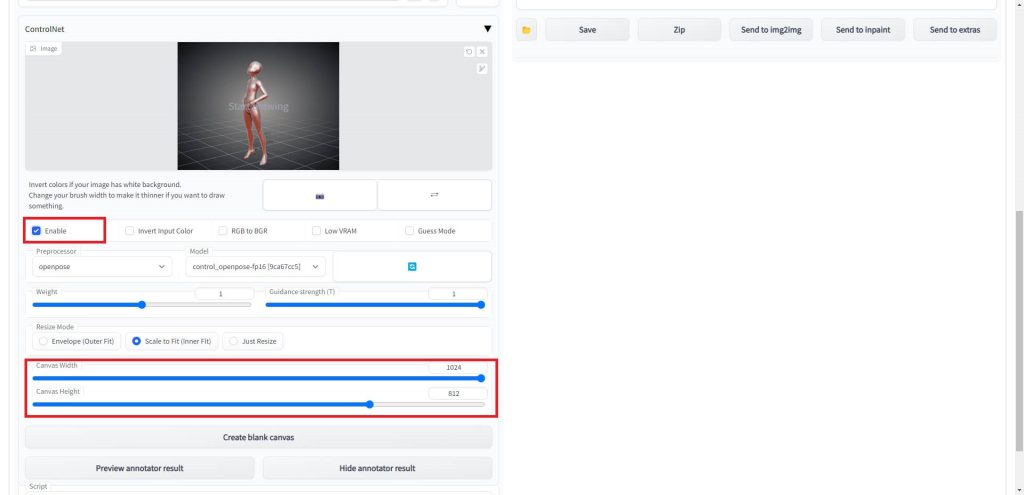
以上でControlNetの設定は完了です。
あとは通常の画像生成と同様にプロンプト、パラメータ等を入力して「Generate」ボタンをクリックすると、画像生成処理が実行されます。

実行結果
ここからは、実際にデザインドールで作成したポーズデータをControlNetで読み込み、ポーズを再現できるかを確認していきます。
使用したポーズデータ
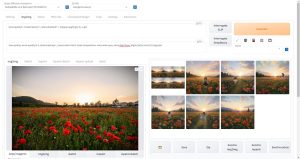
まず、今回デザインドールで作成したポーズデータがこちらです。この画像を先ほどの手順でControlNetに読み込みます。

プロンプトは以下のようなものを用意しました。
ポジティブプロンプト
(best quality)+,(masterpiece)++,(ultra detailed)++, The big city of the near future. She is a girl in a hoodie standing alone.ネガティブプロンプト
(low quality, worst quality)1.4, (bad anatomy)+, (inaccurate limb)1.3,bad composition, inaccurate eyes, extra digit,fewer digits,(extra arms)1.2,logo,text以上の条件で画像を生成します。
プロンプトの作成が難しいと思われている方には、AIでプロンプトを自動生成するのがおすすめです。「StableDiffusionのプロンプト(呪文)を自然言語処理モデルGPT-3(Catchy)で自動生成する方法」で詳細を解説しています。
Stable Diffusionで生成された画像
こちらが生成された画像です。
キャラクターのポーズは、デザインドールで作成したポーズデータがほぼそのまま再現されています。
また背景はプロンプト通りの近未来の都市が描かれています。

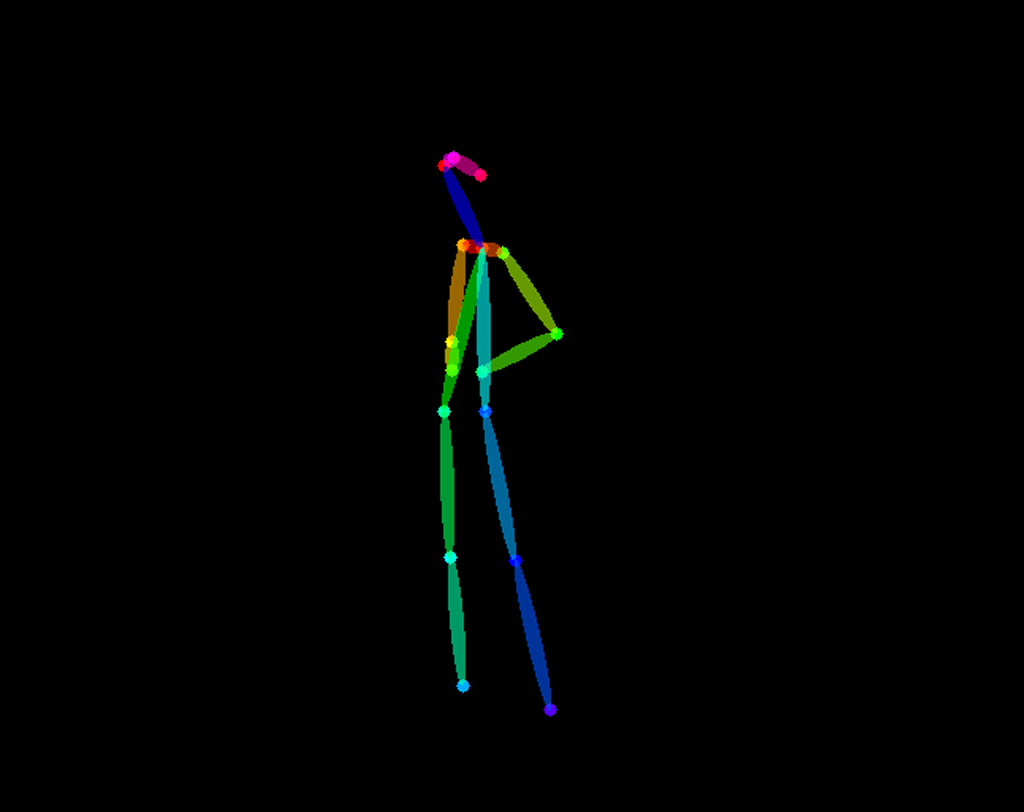
ControlNet生成時にOpenOpse検出した骨格図も出力されています。デザインドールのポーズから正しく骨格検出できていることが確認できました。
Stable Diffusionのテクニックを効率よく学ぶには?
 カピパラのエンジニア
カピパラのエンジニアStable Diffusionを使ってみたいけど、ネットで調べた情報を試してもうまくいかない…
 猫のエンジニア
猫のエンジニアそんな時は、操作方法の説明が動画で見られるUdemyがおすすめだよ!
動画学習プラットフォームUdemyでは、画像生成AIで高品質なイラストを生成する方法や、AIの内部で使われているアルゴリズムについて学べる講座が用意されています。
Udemyは講座単体で購入できるため安価で(セール時1500円くらいから購入できます)、PCが無くてもスマホでいつでもどこでも手軽に学習できます。
Stable Diffusionに特化して学ぶ
Stable Diffusionに特化し、クラウドコンピューティングサービスPaperspaceでの環境構築方法から、モデルのマージ方法、ControlNetを使った構図のコントロールなど、中級者以上のレベルを目指したい方に最適な講座です。
画像生成AIの仕組みを学ぶ
画像生成AIの仕組みについて学びたい方には、以下の講座がおすすめです。
画像生成AIで使用される変分オートエンコーダやGANのアーキテクチャを理解することで、よりクオリティの高いイラストを生成することができます。
まとめ
今回はStable DiffusionでControlNetを使って、キャラクターのポーズを指定して画像生成する方法を解説しました。ControlNetを使用することにより、これまの画像ガチャではなく構図を完全にコントロールして画像を生成できるようになりますので、大幅に自由度があがります。ぜひ試してみてください。
また、以下の記事で効率的にPythonのプログラミングスキルを学べるプログラミングスクールの選び方について解説しています。最近ではほとんどのスクールがオンラインで授業を受けられるようになり、仕事をしながらでも自宅で自分のペースで学習できるようになりました。
スキルアップや副業にぜひ活用してみてください。

スクールではなく、自分でPythonを習得したい方には、いつでもどこでも学べる動画学習プラットフォームのUdemyがおすすめです。
講座単位で購入できるため、スクールに比べ非常に安価(セール時1200円程度~)に学ぶことができます。私も受講しているおすすめの講座を以下の記事でまとめていますので、ぜひ参考にしてみてください。

それでは、また次の記事でお会いしましょう。













コメント