
今回はKerasで作成した機械学習のモデルを保存、読み込みする方法について解説したいと思います。
モデルをファイル出力することで、学習環境以外の場所でも活用できるようになります。
本記事は「Kerasでディープラーニング!Pythonで始める機械学習入」シリーズの手順を解説するページです。シリーズの一覧は以下をご覧ください。

学習モデルの保存
作成した機械学習のモデルを保存するには、Kerasのsaveメソッドを使用します。
引数には以下のようにモデル名を指定します。保存されるモデルファイルの拡張子はHDF5(.h5)となります。
model.save('image-classification.h5')今回は以前、当ブログで掲載した以下の記事で作成したモデルを保存してみます。

作成したソースコード
こちらの記事で紹介したソースコードの層定義以下を変更してモデルを保存できるようにします。
#層を定義
model = models.Sequential()
model.add(Dense(512, activation='relu', input_shape=(10800,))) #activationは活性化関数
model.add(Dropout(0.2))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(2, activation='softmax')) #第1引数分類させる数
#モデルを構築
model.compile(optimizer=tf.optimizers.Adam(0.01), loss='categorical_crossentropy', metrics=['accuracy'])
#EaelyStoppingの設定
early_stopping = EarlyStopping(monitor='val_loss', min_delta=0.0, patience=2)
#モデルを学習させる
log = model.fit(x_train, y_train, epochs=100, batch_size=10, verbose=True, validation_data=(x_test, y_test), callbacks=[early_stopping])
#モデルを保存する
model.save('image-classification.h5')モデル学習後にsaveメソッドでモデルをファイルに保存するように変更しました。
実行結果
先ほどのプログラムを実行すると以下のようになりました。
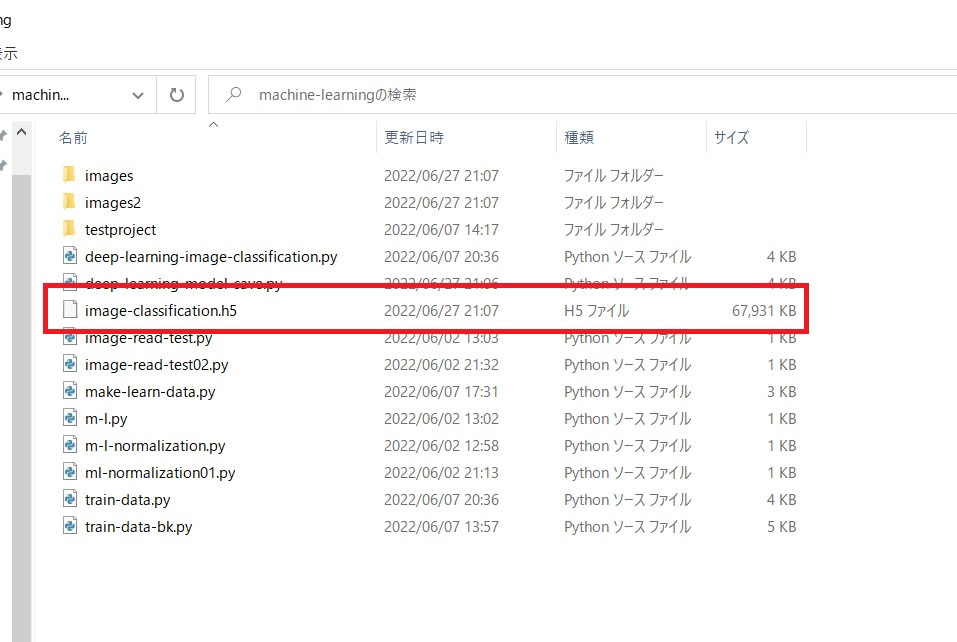
ソースコードと同じディレクトリに「.h5」の拡張子のファイルが保存されたことを確認できました。

学習モデルの読み込み
保存した学習モデルを読み込むには、Kerasのload_modelメソッドを使用します。
引数で読み込むモデルのファイル名を指定します。
model = load_model('image-classification.h5')作成したソースコード
実際に学習モデルを読み込み、モデルの情報を表示するソースコードを以下のように作成しました。
from tensorflow.python.keras.models import load_model
#モデルを読み込み
model = load_model('image-classification.h5')
model.summary() #モデル情報を出力実行結果
実行結果は以下の通りです。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 512) 5530112
_________________________________________________________________
dropout (Dropout) (None, 512) 0
_________________________________________________________________
dense_1 (Dense) (None, 512) 262656
_________________________________________________________________
dropout_1 (Dropout) (None, 512) 0
_________________________________________________________________
dense_2 (Dense) (None, 2) 1026
=================================================================
Total params: 5,793,794
Trainable params: 5,793,794
Non-trainable params: 0先ほど保存した学習モデルの層定義と同様の構造になっていることが確認できました。

モデルをテストする
最後に、保存する前のモデルと同じように推論ができるかをテストしてみます。
「TensorFlowとKerasでニューラルネットワークを実装する」の記事で掲載したソースコードのテストデータを生成する処理を流用し、読み込んだモデルで推論させるコードを以下のように作成しました。
(流用のため、一部不要なコードが含まれています)
from icrawler.builtin import BingImageCrawler
import glob
import cv2
from sklearn.model_selection import train_test_split
from tensorflow import keras
from tensorflow.keras.utils import to_categorical
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, models
from keras.layers import Dense, Dropout
from keras.callbacks import EarlyStopping
from tensorflow.python.keras.models import load_model
#全ての画像ファイルのパスを取得する
files1 = glob.glob("images/*.jpg")
files2 = glob.glob("images2/*.jpg")
files1[len(files1):len(files2)] = files2
#画像データを格納するりすと
image_list = []
#ファイルパスから画像を読み込み
for imgpath in files1:
image = cv2.imread(imgpath) #画像を読み込み
image = cv2.resize(image, (60, 60)) #画像のサイズを変更
#正規化
image = image / 255 #[0~1]にスケーリング
#画像をリストに追加
image_list.append(image)
#ラベルを作成する
label_list = []
label_list2 = []
#50ずつ作成
for i in range(50):
label_list.append("stag_beetle")
for i in range(50):
label_list2.append("mantis")
#ラベルを統合
label_list[len(label_list):len(label_list2)] = label_list2
#学習データとテストデータを作成
x_train, x_test, y_train, y_test = train_test_split(image_list, label_list, test_size=0.2) #20件をテストデータ、それ以外を学習データに分ける
#テーブルデータを作成
columns = ['type'] #列名を指定
df_train = pd.DataFrame(y_train, columns=columns)
df_test = pd.DataFrame(y_test, columns=columns)
print("--TableData--")
print("train df = \n", df_train)
print("test df = \n", df_test)
# 文字列(カテゴリ変数)をダミー変数に変換
y_train = pd.get_dummies(df_train)
y_test = pd.get_dummies(df_test)
print("--dummies--")
print("train dummies = \n", y_train)
print("test dummies = \n", y_test)
#リスト型を配列型に変換
x_train = np.array(x_train)
x_test = np.array(x_test)
x_train = x_train.reshape(80, 10800) #60×60×3(RGB)
x_test = x_test.reshape(20, 10800)
#モデルを読み込み
model = load_model('image-classification.h5')
#モデルを評価する
test_loss, test_accuracy = model.evaluate(x_test, y_test, verbose=0)
print('損失:', test_loss)
print('評価:', test_accuracy)モデルは外部から読み込むため、学習の処理は実装していません。
実行結果は以下の通りです。
損失: 0.5048259496688843
評価: 0.8999999761581421読み込んだモデルでも推論の結果が表示され、動作していることが確認できました。

まとめ
今回はKerasで作成した学習モデルの保存と読み込み方法について解説してみました。学習モデルをファイルとして扱うことで、クラウドで学習し、ローカルのPCで推論を実行したり、Raspberry Piなどのエッジデバイスに実装したりできるようになります。色々な使い道を試してみてください。
機械学習を効率よく学びたい方には、自分のペースで動画で学べるUdemyの以下の講座がおすすめです。数学的な理論からPythonでの実装を習得できます。(私自身もこの講座を受講しています)

機械学習入門におすすめの書籍も以下の記事で紹介していますので、あわせてご覧ください。

また、以下の記事で効率的にPythonのプログラミングスキルを学べるプログラミングスクールの選び方について解説しています。最近ではほとんどのスクールがオンラインで授業を受けられるようになり、仕事をしながらでも自宅で自分のペースで学習できるようになりました。
スキルアップや副業にぜひ活用してみてください。

スクールではなく、自分でPythonを習得したい方には、いつでもどこでも学べる動画学習プラットフォームのUdemyがおすすめです。
講座単位で購入できるため、スクールに比べ非常に安価(セール時1200円程度~)に学ぶことができます。私も受講しているおすすめの講座を以下の記事でまとめていますので、ぜひ参考にしてみてください。

それでは、また次の記事でお会いしましょう。












コメント