今回はPart 1で試した骨格検出アプリケーション「OpenPose」をエッジデバイスであるRaspberry Pi 4に実装できるかを検証していきたいと思います。
また、OpenCVの活用事例についても以下の記事で解説していますので、あわせてご覧ください。
OpenPoseとは
OpenPoseの準備
OpenPoseとはOpenCVと機械学習を使って画像に写っている人物の骨格を検出することが可能なアプリケーションで、製作者のspmallick氏がGithubで無料で公開しています。
今回はこちらのリポジトリの機械学習モデルをお借りして、Raspberry Piで骨格検出をやってみたいと思います。
OpenPoseの導入方法については前回公開したPart 1の記事で詳細を解説していますので、こちらを参考にしてください。

Part 1でダウンロードして実行できるようになった環境の「OpenPose」以下のディレクトリを丸ごとRaspberry Pi 4の作業領域にコピーしてください。
検出対象
また、今回は場所の制約もあり近い距離でしか撮れないため、以下のようなフィギュアをUSBカメラで撮影して骨格を検出したいと思います。


Raspberry Piとは
前回のPart 1ではIntelのCPUを搭載したPCで処理を行いました。今回は手軽に持ち運び、設置が可能なマイコンボードRaspberry Pi 4を使って骨格検出プログラムの実装をしていきたいと思います。
Raspberry Pi 4のスペック等については、以下の記事で解説していますのであわせてご覧ください。


使用するカメラ
今回使用するカメラは当ブログでもおなじみとなったロジクール製のC270nです。安価でアマゾン等でも販売されていますので入手性もよく、Raspberry Pi 4のUSB接続コネクタに差し込むだけですぐに使用できますのでおすすめです。


以下の写真のように対象との距離は30cmほど離してRaspberry Pi 4とWebカメラを設置しました。

左の大きな冷却ファンがついているのがRaspberry Pi 4、右がWebカメラです。

この状態でフィギュアの骨格を検出できるかをテストしていきたいと思います。

作成したソースコード
Raspberry Pi用に変更した箇所
Part 1の記事で公開したソースコードから、Raspberry Pi用に以下の箇所を変更しました。
画像の取得部分を前回はあらかじめ用意された画像ファイルでしたが、今回は毎回Webカメラで撮影して取り込むようにしています。また、マイコンでの処理負荷を考慮して小さくリサイズしました。
#VideoCaptureオブジェクト取得
cap = cv2.VideoCapture(-1)
print("start")
while(True):
#フレームを取得
ret, frame = cap.read()
if not ret:
print("not capture")
break
#画像をリサイズ
frame = cv2.resize(frame, (320, 240))骨格検出を行った後の表示でX,Y各軸の目盛表示をしないようにしました。
また、画像を確認するためEnterキーを押すまで処理を止めています。
print("画像出力")
cv2.imshow("frame", frame)
cv2.waitKey(13) #Enterキーで画像再取り込みアプリ終了時にカメラデバイスをクローズする処理を追加しました。
#カメラデバイスクローズ
cap.release()
#ウィンドウクローズ
cv2.destroyAllWindows()ソースコード全体
以下がRaspberry Pi 4用に作成した全体のソースコードです。
モデルファイルのパスはそれぞれの環境に合わせて任意に変更してください。
import cv2
import time
import numpy as np
import matplotlib.pyplot as plt
#読み込むモデルを選択
MODE = "MPI"
if MODE is "COCO":
protoFile = "(コピーしたファイルのディレクトリパス)/OpenPose/pose/coco/pose_deploy_linevec.prototxt"
weightsFile = "(コピーしたファイルのディレクトリパス)/OpenPose/pose/coco/pose_iter_440000.caffemodel"
nPoints = 18
POSE_PAIRS = [ [1,0],[1,2],[1,5],[2,3],[3,4],[5,6],[6,7],[1,8],[8,9],[9,10],[1,11],[11,12],[12,13],[0,14],[0,15],[14,16],[15,17]]
elif MODE is "MPI" :
protoFile = "(コピーしたファイルのディレクトリパス)/OpenPose/pose/mpi/pose_deploy_linevec_faster_4_stages.prototxt"
weightsFile = "(コピーしたファイルのディレクトリパス)/OpenPose/pose/mpi/pose_iter_160000.caffemodel"
nPoints = 15
POSE_PAIRS = [[0,1], [1,2], [2,3], [3,4], [1,5], [5,6], [6,7], [1,14], [14,8], [8,9], [9,10], [14,11], [11,12], [12,13] ]
net = cv2.dnn.readNetFromCaffe(protoFile, weightsFile)
#VideoCaptureオブジェクト取得
cap = cv2.VideoCapture(-1)
print("start")
while(True):
#フレームを取得
ret, frame = cap.read()
if not ret:
print("not capture")
break
#画像をリサイズ
frame = cv2.resize(frame, (320, 240))
frameCopy = np.copy(frame)
frameWidth = frame.shape[1]
frameHeight = frame.shape[0]
threshold = 0.1
inWidth = 368
inHeight = 368
inpBlob = cv2.dnn.blobFromImage(frame, 1.0 / 255, (inWidth, inHeight),
(0, 0, 0), swapRB=False, crop=False)
net.setInput(inpBlob)
output = net.forward()
H = output.shape[2]
W = output.shape[3]
points = []
for i in range(nPoints):
# confidence map of corresponding body's part.
probMap = output[0, i, :, :]
# Find global maxima of the probMap.
minVal, prob, minLoc, point = cv2.minMaxLoc(probMap)
# Scale the point to fit on the original image
x = (frameWidth * point[0]) / W
y = (frameHeight * point[1]) / H
if prob > threshold :
cv2.circle(frameCopy, (int(x), int(y)), 8, (0, 255, 255), thickness=-1, lineType=cv2.FILLED)
cv2.putText(frameCopy, "{}".format(i), (int(x), int(y)), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2, lineType=cv2.LINE_AA)
cv2.circle(frame, (int(x), int(y)), 8, (0, 0, 255), thickness=-1, lineType=cv2.FILLED)
# Add the point to the list if the probability is greater than the threshold
points.append((int(x), int(y)))
else :
points.append(None)
# Draw Skeleton
for pair in POSE_PAIRS:
partA = pair[0]
partB = pair[1]
if points[partA] and points[partB]:
cv2.line(frame, points[partA], points[partB], (0, 255, 255), 3)
print("画像出力")
cv2.imshow("frame", frame)
cv2.waitKey(13) #エンターキーで画像再取り込み
#キーボード入力処理
key = cv2.waitKey(1)
if key == 13: #enterキーの場合処理を抜ける
break
#カメラデバイスクローズ
cap.release()
#ウィンドウクローズ
cv2.destroyAllWindows()実行結果
先ほどのプログラムを実行した結果です。
画像が小さいですが、フィギュアの骨格がおおむね正しく検出できていることが確認できました。
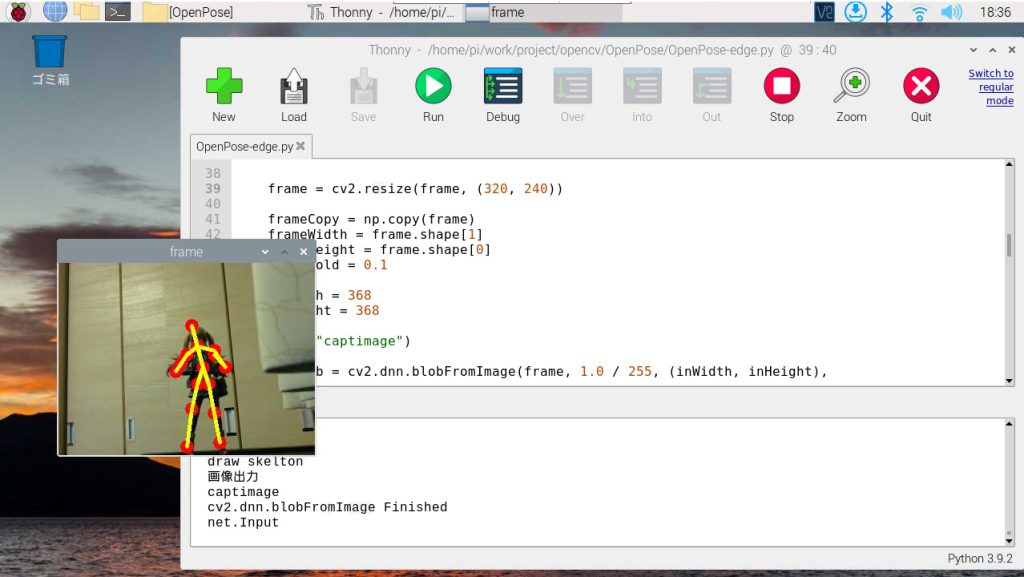
ちなみに骨格検出をする前にリサイズをしていますが、Raspberry Pi 4(4GB版)のGPUメモリの制約からか「640×480」以上のサイズで実行すると固まってしまい検出結果が表示できませんでした。
また、以下の処理で異常に時間がかかっており、現状の実装だとリアルタイムに連続的に骨格検出するのは難しそうです。
output = net.forward() こちらは今後高速化する手段を考えていきたいと思います。
\ Pythonを自宅で好きな時に学べる! /
まとめ
今回はOpenPoseをRaspberry Pi 4に実装するための方法と、検証結果について解説しました。任意のタイミングでWebカメラで撮影した画像に対して骨格検出を行うといった用途では使えそうですが、リアルタイムに処理するには改良が必要ということがわかりました。
今後、高速化や別の学習モデルを使った方法についても試していきたいと思います。
また、OpenCVをさらに詳しく学びたい方には、Udemyの以下の講座もお勧めです。

また、以下の記事で効率的にPythonのプログラミングスキルを学べるプログラミングスクールの選び方について解説しています。最近ではほとんどのスクールがオンラインで授業を受けられるようになり、仕事をしながらでも自宅で自分のペースで学習できるようになりました。
スキルアップや副業にぜひ活用してみてください。

スクールではなく、自分でPythonを習得したい方には、いつでもどこでも学べる動画学習プラットフォームのUdemyがおすすめです。
講座単位で購入できるため、スクールに比べ非常に安価(セール時1200円程度~)に学ぶことができます。私も受講しているおすすめの講座を以下の記事でまとめていますので、ぜひ参考にしてみてください。

それでは、また次の記事でお会いしましょう。











コメント