
こんにちは、むらさんです。
今回はヤフー画像検索の検索結果ページで表示される画像データをスクレイピングするプログラムを作成してみます。機械学習で使用する画像データをスクレイピングで大量に集められたらいいなと思いました。
目次
スクレイピングするページ
Yahoo!Japanの画像検索ページで「猫」というキーワードで検索してみました。
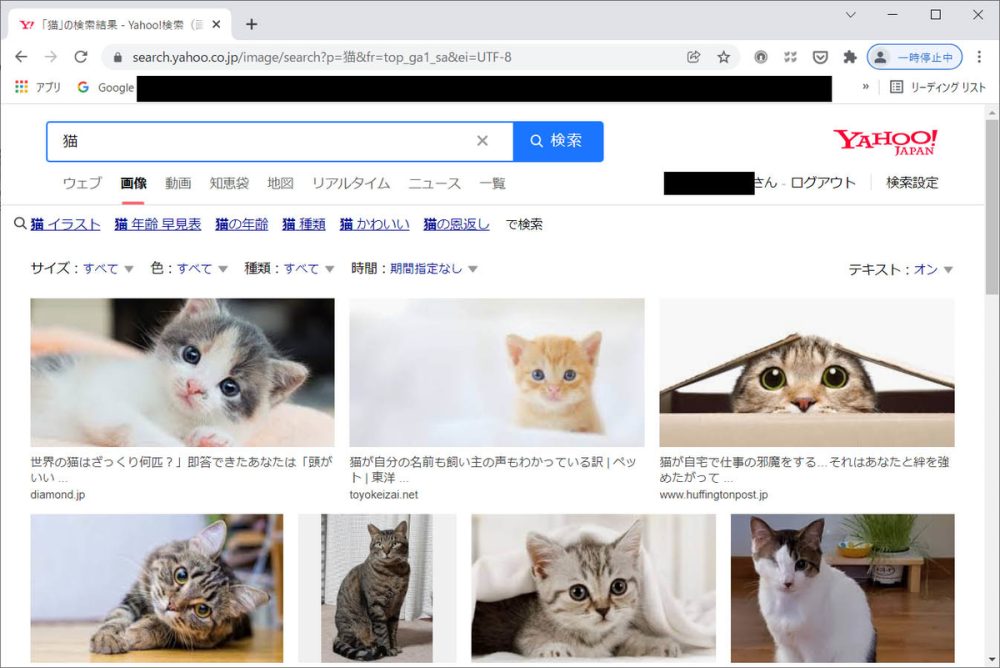
このような画面が検索結果として表示されました。この画像をスクレイピングでダウンロードしてみたいと思います。
import requests
import os
from bs4 import BeautifulSoup
img_page = "https://search.yahoo.co.jp/image/search?p=%E7%8C%AB&fr=top_ga1_sa&ei=UTF-8"
savepath = "./images"
#保存先ディレクトリ作成
os.makedirs(savepath, exist_ok=True)
#検索ページを取得
req = requests.get(img_page)
soup = BeautifulSoup(req.text, 'html.parser')
img_tags = soup.find_all("link", {"rel":'preload'}) #タグで画像ファイルのパスを検索
#画像をダウンロードして保存する
for tag in img_tags:
url_img = tag['href'] #画像パスを取得
extension = os.path.splitext(url_img) #拡張子を取得
filename = os.path.basename(url_img) #ファイル名を取得
#拡張子が画像ファイルの場合は保存する
if extension[1] == ".jpg" or extension[1] == ".jpeg":
#url_list.append(url)
print("url=" + url_img)
print("ets=" + extension[1])
print("filename=" + filename)
#画像をダウンロード
req_img = requests.get(url_img)
#ファイルパスを生成
file_paht = os.path.join(savepath, filename)
#指定したフォルダに保存
with open(file_paht, "wb") as f:
f.write(req_img.content)実行結果
プログラムを実行したところ、以下のように指定したディレクトリにファイルが保存されていました。
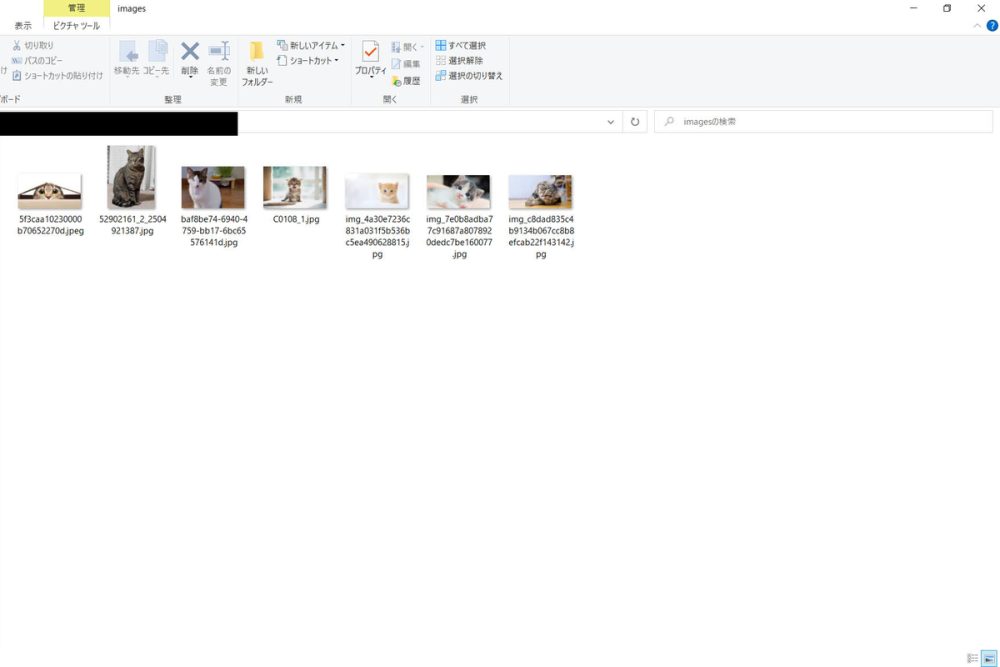
検索画面の上部の画像は保存できたのですが、それ以降の下方向にスクロールしていくと表示される画像はダウンロードすることができませんでした。スクロールすると表示される画像は”img”タグでURLが記述されていましたが、初期ページでは”img”タグで取得する処理を書いても取得できないようです。
まとめ
ヤフー画像検索ではrequestsモジュールを使った方法では先頭の7件しか取得することができませんでした。どうもブラウザをスクロールしていくとURLが変わってさらに下位の画像が表示される仕組みになっているようです。
SeleniumなどのWebブラウザ操作ツールを使ってさらに下位の画像を取得できるよう改良していきたいと思います。
それでは、また次の記事でお会いしましょう。
おすすめ記事
あわせて読みたい


Pythonが学べるプログラミングスクール5選 | 初心者にもおすすめ
プログラミングスクールってたくさんあって、どのスクールを選んだらいいのかな? 自分のキャリアアップに必要なカリキュラムがあるプログラミングスクールを探したいん…
あわせて読みたい

ラズベリーパイ(Raspberry Pi)でできること!活用事例集
ラズベリーパイを買ったけどLチカしたあと何ができるのかイメージがわかない、これからラズベリーパイを買って電子工作で何かを作ってみたいけど何ができるの?という方…










コメント